大家好,我是老兵。
本期为大家带来spark源码精讲系列,我将结合自身的理解深入浅出的剖析spark内核。全文内容很肝,希望能够给大家提供帮助。
1 引子(环境准备)
本文整体基于Spark2.4.1代码讲解,首先需要准备编译环境。
1)编译环境
1)scala2.11+ jdk1.8+ maven3.5+ Git2.0 + Spark2.4.1
2)windows环境(idea)


2)编译
准备好上述环境(自行百度安装教程),开始执行编译。
切换到下载解压后的spark目录,执行maven命令:
mvn -Pyarn -Phadoop-2.6 -Dscala-2.11 -DskipTests clean package

最终编译成功后的结果如下:

注:因篇幅问题,源码编译问题可自行百度网上教程
3)注意事项
整体讲解内容分为:任务提交->Driver注册启动->SparkContext初始化->Executor启动->Task启动
主要围绕下面三个流程图展开,所以大家在忘记时请回到这里!!

standalone模式

YarnClient模式

YarnCluster模式
2 源码剖析—Spark任务提交
假如现在我们已经有了一个简单的spark demo,例如word-count计算,并且设置好cores、executors以及部署模式,正待提交集群。
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("MyWordCount").setMaster("yarn");
val sc = new SparkContext(conf)
val result = sc.textFile("hdfs://hadoop002:9000/wordcount.txt")
.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
result.foreach(println)
sc.stop()
}
2.1 脚本提交
1) 先来看看大致的spark-submit任务提交脚本

2) 跟踪$SPARK_HOME/bin下的Spark-Submit脚本,实际执行的是bin/spark-class脚本,发现在其内部调用org.apache.spark.deploy.SparkSubmit类。

整体看下这个脚本主要做了这些事情:
-
首先校验SPARK_HOME/conf、spark相关依赖目录SPARK_HOME/jars、hadoop相关依赖目录$HADOOP_HOEM/lib
-
将校验所得所有目录地址拼接为LAUNCH_CLASSPATH变量
-
将$JAVA_HOME/bin/java 定义为RUNNER变量
-
调用build_command()方法,创建执行命令
-
把build_command()方法创建的命令,循环加到数组CMD中,最后执行exec执行CMD命令

这里只要知道,CMD命令最终调用org.apache.spark.deploy.SparkSubmit类,即Spark程序的入口。
2.2 提交主函数执行
接下来我们把目光移入SparkSubmit类。
SparkSubmit职责:准备Driver注册启动和SparkContext启动
定位到脚本中的执行主类org.apache.spark.deploy.SparkSubmit。解析脚本提交参数并根据参数action进行模式匹配,此时为SUBMIT操作,执行submit方法

1) Submit()方法。执行doRunMain(),判断是否使用proxyUser模式,并执行runMain()

2) 执行RunMain()方法,这个是核心方法。

2.2.1 调用prepareSubmitEnvironment()准备Submit环境
跟踪RunMain方法,首先调用的是prepareSubmitEnvironment()函数。进行后续解析参数,获取Args、Classpath、SparkConf和MainClass工作

1) 根据参数中master/deploy-mode配置,设置对应的clusterManager和部署模式(YARN/STANDALONE/MESOS/K8S/LOCAL CLIENT/CLUSTER)

2) 根据args中的参数,设置相关的childArgs/classPath/ChildMainClass等返回结果

- MAIN_CLASS:CLIENT模式<Yarn client/Standalone client>
使用程序自定义主类
- MAIN_CLASS:STANDALONE-CLUSTER模式
使用REST: org.apache.spark.deploy. RestSubmissionClientApp|| org.apache.spark.deploy. ClientApp
- MAIN_CLASS:YARN-CLUSTER模式
org.apache.spark.deploy.yarn.YarnClusterApplication
- MAIN_CLASS: MESOS-CLUSTER模式
org.apache.spark.deploy. RestSubmissionClientApp
- MAIN_CLASS: KUBERNETES-CLUSTER模式
org.apache.spark.deploy.k8s.submit.KubernetesClientApplication
至此,spark内部已经完成了不同deployMode下的MainClass的定义,并且已经获取到classpath、conf等信息。
2.2.2 调用MainClass类执行方法, 准备注册Driver和启动SparkContext
现在准备加载MainClass主类(注意:此时这个MainClass不一定是我们开发程序里的Main函数),大概有如下步骤:

1) 获取当前执行线程类加载器ClassLoader并加载Jar包 注意: 需要判断spark加载用户提交的jar和spark自身Jar的优先级(DRIVER_USER_CLASS_PATH_FIRST)

2) mainClass实例化并执行对应的start()方法
注意: 除了Client模式下的用户自定义类之外,其余的MainClass全部继承SparkApplication类,即client模式走else条件:JavaMainApplication(这个类会调用我们自己写的Main函数)。

下面我们分模式讨论不同MainClass的start()方法,执行流程不熟悉的同学请移步到那三张图。
2.2.2.1 Standalone cluster模式下start()入口
org.apache.spark.deploy.ClientApp.start()
这里是spark的内置默认模式:standalone模式的MainClass执行逻辑,主要交互角色为Driver->Master->Worker,SparkContext在某worker上初始化。
-
1)注册RpcEnv,调用onStart()方法向
Master提交Driver注册 -
2)Master接受请求后选择合适的worker
启动Driver -
3)后续Driver启动并初始化
SparkContext -
4)执行
task任务分发和Executor启动。

2.2.2.2 Yarn Client/Standalone Client模式下start()入口
org.apache.spark.deploy.JavaApplication.start()
这里是YarnClient模式的MainClass执行逻辑,底层会直接调用我们程序的Main方法,在client端初始化sparkcontext。
-
1)根据反射执行
用户自定义程序Main(),并继续后续的SparkContext初始化操作 -
2)启动Executor并反向注册到
Driver -
3)程序执行到action算子时候调用DAGSchduler的start()方法执行DAG划分
-
4)TaskScheduler的taskset调度
-
5)Executor任务执行

注: 两者后续的SparkContext初始化过程区别
1)Yarn-Client模式的SparkContext初始化过程中会调用YarnClientSchedulerBackend的start(), 再调用submitApplication()提交启动AppMaster请求到Yarn RM;并在后续的ApplicationMaster中的run()中启动ExecutorRunner
2)Standalone-client模式下的SparkContext初始化过程会调用StandaloneSchedulerBackend的start(), 向Master申请运行Application的资源, 随后在worker上启动对应的Executor运行任务。
2.2.2.3 YarnCluster模式下的start()入口
org.apache.spark.deploy.yarn.YarnClusterApplication.start():
这里是YarnCluster模式下的MainClass执行逻辑,Driver在Yarn的ApplicationMaster上启动,进行SparkContext初始化。
-
1)获取Application的环境和信息
-
2)调用SubmitApplication()提交启动AppMaster请求到YarnRM
-
3)后续等待RM启动AppMaster
-
4)启动Driver和Executor


2.3 Yarn模式后续: AppMaster接收submitApplication请求
这里可以接着上面所述,在Yarn部署环境下,MainClass的start()方法执行成功,同时完成向Yarn提交Application请求。
注意:
1)这里Yarn Client已经完成了SparkContext的初始化操作(并且在YarnClientSchedulerBackend中提交了Application);
2)而Yarn Cluster在main方法中刚提交Application,未开始初始化SparkContext。
Yarn提交任务后,ApplicationMaster启动后执行main函数,并调用自身的run()函数,根据条件判断启动Driver或者ExecutorLauncher接受资源调度。


下面我们分别剖析YarnClient和YarnCluster模式的AppMaster启动。
2.3.1 Yarn-Cluster模式的AppMaster启动
原理:Spark内部把Driver作为一个ApplicationMaster在Yarn中启动。
-
1)执行User自定义Main方法并初始化SparkContext(启动Driver)
-
2)创建DriverRpcEndpoint连接YarnScheduler
-
3)后续CreateAllocator()申请container容器并启动Driver

启动Driver

调用Main方法
2.3.2 Yarn-Client模式的AppMaster启动
Client模式已经有Driver和SparkContext,此时只需要创建ExecutorLauncher线程(仅负责和SparkContext通信)。
-
1)不运行SparkContext,只与SparkContext进行联系进行资源的分派)
-
2)DriverRpcEndpoint连接YarnScheduler
-
3)后续CreateAllocator()申请container容器并启动

到目前为止,不同模式下的MainClass的start()方法已经开始执行,但是Driver启动过程我们暂时还不清楚。
3 源码剖析—Driver注册启动
现在我们来看看不同模式下的Driver启动过程。
3.1 Standalone模式
org.apache.spark.deploy.ClientApp.start()开始执行...
3.1.1 ClientApp提交请求
-
1)ClientApp的start()注册ClientEndpoint
-
2)封装DriverDescript :MainClass/Jars/memory/cores。
-
3)向Master发送注册请求

3.1.2 Master接受Driver注册请求
Master在ACTIVE状况下的大致功能为:
1)启动或释放可用的worker、drivers和apps缓存(HashMap)
2)存储或释放apps和drivers至等待watings队列(ArrayBuffer)中并持久化
3)等待apps或者drivers变化时调用schedule()调度

Master接受Driver注册流程:
-
1)根据DriverDescript信息创建Driver对象
-
2)Driver对象持久化、加入Driver等待队列<待调度>和内存set中
-
3)Schedule()调度
-
4)返回注册结果

schedule()中driver注册逻辑:
-
1)shuffle打散可用的AliveWorkers(根据剩余cores排序)
-
2)遍历waitingDrivers数组,每个Driver内部循环遍历AliveWorkers。判断AliveWorkers中是否存在当前的可用memory和cores满足当前Driver运行的所需memory和cores,如果满足则waitingDrivers-1并调用launchDriver()
-
3)调用launchDriver在worker上启动Driver并将状态通知Master
-
4)调用startExecutorsOnWorkers启动Executor(后续)
3.1.3 Worker上启动Driver
-
1)WorkerInfo添加Driver信息、DriverInfo添加worker信息
-
2)向worker发送启动Driver的命令;等待worker启动DriverRunner线程启动Driver(调用
launchDriver方法) -
3)Worker上的Driver状态置为RUNNING
-
4)Driver启动完成后,DriverRunner线程通知worker清除内存中的当前driver信息并移动到已完成队列中
-
5)同时更新当前worker的内存和cpu数量,并通知Master相关Driver状态变更

launchDriver()方法:org.apache.spark.deploy.Worker
-
1)创建DriverRunner线程并启动(
调用driver方法) -
2)创建Driver目录、下载用户Jar包;封装启动命令;启动Driver初始化SparkContext
-
3)线程阻塞并向Master通知Driver的状态

prepareAndRunDriver()方法:下载用户 jar包到工作目录、准备启动命令、启动Driver


runDriver()方法:封装Driver启动命令,Build命令格式化处理并执行获取返回码状态

最终执行的Driver命令cmd:执行用户提交的真实ManiClass,并执行后续的SparkContext过程

3.1.4 Driver启动后反向注册Master
-
1)Driver启动返回码exitCode适配, DriverRunner线程通知worker
-
2)清理worker内存中的当前driver信息、添加当前driver至finishedDrivers;Worker中内存和cores更新(减去当前driver的core/memory)
-
3)发送Driver更新消息至Master
-
4)Master接受消息并开始调用schedule()调度

Worker更新内存中driver信息:移除driver信息、减去内存/core、加入已完成driver队列中

Master接收Driver状态信息:移除driver信息、减去内存/core、加入已完成driver队列中
-
1)移除Master内存、持久化引擎中的drivers信息
-
2)当前driver加入到Master的已完成drivers队列; 并设置当前driver的状态
-
3)减去该driver关联的 worker信息中的Driver内存和cores资源
-
4)重新调度schedule()方法

3.1.5 后续调用startExecutorsOnWorkers()启动Executor


基于Master的schedule()调度方法调度当前可用资源,每次新的app加入或者资源变化时都会被调用:
-
1)遍历wattingApps需要分配的apps
-
2)查找可用的worker列表内存和core是否满足并根据剩余cores排序
-
3)根据分配机制(spreadOut/non spreadOut方法)分配资源
-
4)根据分配结果,在worker中启动executor



[补充:schedule()的分配机制]:
-
spreadOut算法(默认): 20core 10executor
根据配置平均将core分配到worker上。遍历所有worker,按照配置将core平均分布到每个 worker上,每个worker只分配一个executor,跳出循环,进入下个worker。 直到所有的 executor分配完成。 结果: 10个worker,每个启动一个2core/executor
-
非spreadOut算法:
尽可能少的启动worker, 优先在一个worker上分配,完全利用worker上的core。 遍历所有worker, 在每个worker上根据worker中剩余的core数量完全分配给executor, 直到当前 worker上的core分配完成,进入下个worker。直到executor分配完成。 结果: 2个worker, 每个启动1个executor, 10个core
3.2 YarnCluster模式
org.apache.spark.deploy.yarn.YarnClusterApplication.start()开始执行...
3.2.1 Client提交Application
-
1)YarnClusterApplication类中创建spark.deploy.yarn.Client对象,并执行run()
-
2)如果设置spark.yarn.submit.waitAppCompletion,run()方法一直运行直到application推出,否则在application提交后client进程就退出
-
3)执行submitApplication()提交Application, 由RM指定一个NM来执行封装的命令,启动AM
-
4)获取submitApplication()执行状态,如果failed/killed则抛出错误

3.2.2 SubmitApplication提交创建AppMaster请求
-
1)初始化YarnClient对象,执行YarnClient方法,提交Application
-
2)创建AM容器启动的上下文环境、启动命令、上传程序包到
HDFS -
3)调用yarnClient自带方法,提交创建AM Contarnier请求

-
4)执行APP启动Command bin/java ApplicationMaster –class --jar:根据deployMode不同,启动ApplicationMaster(YarnCluster)和ExecutorLauncher(YarnClient)

3.2.3 ApplicationMaster启动准备
-
1)设置系统配置参数
-
2)根据match配置在NM上启动Driver或ExecutorLauncher

3.2.4 启动ApplicationMaster并创建Driver容器
-
1)创建UserThread线程并运行,调用User自定义类Main,启动Driver线程并初始化SparkContext
-
2)向ResourceManager注册ApplicationMaster(Yarn底层),成功后申请启动Executor的Container资源
-
3)启动ExecutorRunner
-
4)在NodeManager上启动ConreasinedExecutorBackend

3.2.4.1 创建UserThread线程运行用户Main()
加载用户自定义MainClass, 执行Main方法(后续SparkContext初始化)

3.2.4.2 注册AM并启动ExecutorRunner
-
1)向RM注册AM (spark.driver.host/port),向Yarn底层的RMClient提交注册AppMaster的申请并启动AppMaster
-
2)创建DriverEndpoint通信对象,保持和YarnSchedulerBackend通信
-
3)AM向 RM申请Container容器资源,分配资源并启动ExecutorRunner对象(后续NM启动Executor)

-
3.1)获取所有的container资源状态并挑选存在剩余资源的容器,并启动Executor


-
3.2)向NM申请启动Container启动Executor
准备启动CorseGrainedExecutorBackend类命令,在NM上启动Container

YarnClient模式可自行查阅源码,执行流程和YarnCluster类似,仅最终启动的组件不同(ExecutorLauncher)
4 源码剖析—SparkContext初始化
Driver启动成功后开始调用我们自定义的MainClass方法,即WordCount中的Main(),即来到了第一步:SparkContext初始化。

SparkContext初始化过程透明化,Spark底层做了很多事情,包括Spark环境初始化、创建TaskSchduler和DAGScheduler、SparkContext激活等。
4.1 初始化Spark环境及相关配置
1)定义私有变量

2)初始化相关配置

4.2 SparkEnv环境创建
1) 从SparkConf中获取Driver信息,调用Create()方法

2) 创建Driver RPC Endpoint对象
这个是Driver的RPC通信对象,可以和外部组件通信。

3) 创建SerializerManager(默认为JavaSerializer)、brocastManager、创建MapOutpuTrackerMaster及其RPC Endpoint对象(这几个都是序列化、内部存储、Shuffle相关的组件)

4) 创建ShuffleManager(默认为sort shuffle)、MemoryManager(默认为UnifiedMemoryManager:1.6之后)

5) 创建创建BlockManagerMaster、BlockManager等

4.3 创建TaskSchduler和DAGScheduler
Spark核心的两大组件,贯穿整个Spark任务的DAG划分、task任务分配和提交。


4.3.4.1 创建TaskScheduler
1)初始化TaskScheduler/SchedulerBackend
根据不同的master url,创建对应的TaskScheduler和SchedulerBackend(TaskScheduler的RPC对象)
-
1)Local(本地单CPU模式): TaskSchedulerImpl:max_local_task_failures:1(本地最大任务重试) LocalSchedulerBackend:totalCores:1(本地启动cpu核数数量1)

-
2)Local_N_REGEX(Local[*]模式): TaskSchedulerImpl :max_local_task_failures:1((本地最大任务重试) LocalSchedulerBackend:threadCount:1(本地启动指定数目CPU/所以可执行cpu)

-
3)LOCAL_N_FAILURES_REGEX (Local[n,m]本地失败重试模式): TaskSchedulerImpl :maxFailures:m(本地最大任务失败重试) LocalSchedulerBackend:threadCount:1(本地启动指定数目CPU/所以可执行cpu)

-
4)SPARK_REGEX(StandAlone模式): TaskSchedulerImpl/StandaloneSchedulerBackend

-
5)Yarn模式下的TaskScheduler和SchedulerBackend创建 TaskSchedulerImpl:根据master-url(cluster/client)初始化 YarnClient/YarnClusterSchedulerBackend: 根据master url(cluster/client)初始化相应的Backend
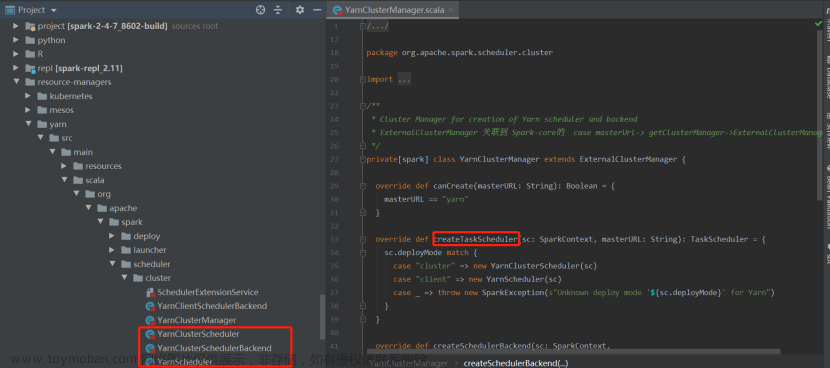
2)初始化taskScheduler资源调度池pool

创建FIFO/FAIR的taskset资源调度池,后续调度taskset任务。

-
1)FIFO(队列机制,先进先出)

-
2)FAIR(读取资源调度文件配置)

4.3.4.2 创建/启动DAGScheduler并注册心跳
DAGScheduler创建(TaskScheduler引用),等待后续Job的任务DAG调度:
-
1)初始化事件处理线程,主要作用于后续处理DAG切分的核心逻辑
-
2)发送
TaskScheduler成功创建心跳到HeartbeatReceiver

4.3.4.3 TaskScheduler启动
1)Schedulebackend启动
创建TaskScheduler RPCEndpoint对象(和Driver进行通信的实例)

2)推测任务执行
对一个Stage里面运行慢的Task,会在其他节点的Executor上再次启动这个task,如果其中一个Task实例运行成功则将这个最先完成的Task的计算结果作为最终结果,同时会干掉其他Executor上运行的实例,从而加快运行速度。

-
1)检测是否有需要推测式执行的Task, 满足非local模式下开启spark.speculation,开启推测执行,存在则backend调用reviveOffers获取资源运行推测任务。

-
2)当成功的Task数超过总Task数的75% (spark.speculation.quantile: 0.75),再统计任务运行时间中位数乘以1.5(spark.speculation.multiplier)的运行时间阈值,如果超出该阈值则启动推测

-
3)在TasksetManager为下个task分配executor时候dequeueTask()中启用调度检测,先过滤掉已经成功执行的task,另外,推测执行task不在和正在执行的task同一Host执行,不在黑名单executor里执行。

4.4 SparkContext初始化
4.4.1 初始化applicationId、ui、blockManager、ContextCleaner、MetricSystem
-
1)创建ContextCleanner并启动: 清理那些超出应用范围的RDD、shuffleDependency和Broadcast
-
2)创建MetricSystem并启动: 统计信息管理器
-
3)创建ExecutorAllocationManager(是否开启动态资源配置),根据工作负载来衡量是否应该增加或减少executor
-
4)BlockManager初始化


4.4.2 启动事件消息监听器;发送环境更新和应用启动消息

4.5 激活SparkContext
将当前SparkContext的状态从contextBeingConstructed(正在构建中)改为activeContext(已激活)

至此,SparkContext已经初始化完成,TaskScheduler和DagScheduler已经创建,程序进入任务划分等待阶段。
5 源码剖析—Executor启动
在任务进入任务划分等待阶段时,ExecutorBackend线程已经开始准备启动Executor的工作(这两个步骤是同步进行的)。
至于启动多少executor和如何启动,ExecutorBackend会遵循你的Spark-submit脚本。
这里仅剖析Yarn模式下的Executor情况(Standalone模式情况类似,只不过是对Master反向注册)
5.1 CoarseGrainExecutorBackend向Driver注册Executor
-
1)初始化CoarseGrainedExecutorBackend环境,创建RPC对象
-
2)启动onStart()方法,向Driver发送ask注册请求(自身的RPC ref对象)
-
3)Driver的CoarseGrainedScheduleBackend接收请求并注册Executor
-
4)CoarseGrainedExecutorBackend接受请求并创建Executor

5.1.1 创建CoarseGrainedExecutorBackend环境(RPC对象)

5.1.2 CoarseGrainedSchedulerBackend接收请求,注册Executor
-
1)内存executorDataMap中添加Executor信息(Executor address记录、数量+1)

-
2)向CoarseGrainedExecutorBackend发送registeredExecutor完成信息

-
3)调用makeOffers(), 等待后续分配taskset给Executor

5.1.3 CoarseGrainedExecutor接收executor的注册消息,启动executor

5.2 CoarseGrainExecutorBackend启动Executor
-
1)创建ThreadPool线程池
-
2)创建Executor并序列化
-
3)等待后续分配task

Executor此时创建完成,开始进入等待任务分配阶段。
6 源码剖析—Task启动
现在开始进行Task启动过程,首先进行的是任务切分和分配工作。
6.1 Task任务切分
6.1.1 DAGScheduler初始化
DAGScheduler的功能:
1)计算并追踪DAG和划分stage: 最后finalStage,倒推遇到宽依赖就划分stage,优先提交父stage
2)根据stage中的taskset最优算法<存在cache或者checkpoint操作的>设置好优先位置,否则等待taskscheduler进行最优位置划分;最后提交taskset到Taskscheduler上
3)处理因shuffle过程丢失的RDD,重新计算和提交; 一个stage内部的原因,则是task自己解决
在完成SparkContext初始化和Executor启动后,这里还是回到我们提交的Main方法中。

我们定位到Spark程序中的Action算子(foreach/collect算子),其内部调用SparkContext的runJob方法。

-
1)SparkContext嵌套的runJob方法(所有的
action算子均有这个runJob函数)
-
2)调用DAGScheduler的runJob方法

-
2.1)初始化
DAGSchedulerEventProcessLoop,DAGSchedulerEventProcessLoop是来对DAGScheduler主要事件进行管理(包括接收JobSubmit提交等消息处理) -
2.2)
submitJob方法调用eventProcessLoop的post方法,调用eventProcessLoop post将JobSubmitted事件添加到DAGScheduler事件队列,给自己发送一个提交任务的作业
-
3)
eventProcessLoop的receive接收,处理jobtask(调用DAGScheduler的handleJobSubmitted方法)
6.1.2 DAGScheduler切分Stage
我们定位到DAGScheduler的handleJobSubmited()方法:

-
1)触发job的最后一个rdd,创建
finalStage并同时创建shuffleMapStage -
2)用finalStage创建一个Job,这个job的最后一个stage,就是
finalStage -
3)将Job相关信息,加入内存缓冲中
-
4)第四步,使用
submitStage方法提交finalStage
6.1.2.1 创建finalStage(ResultStage)
-
1)检查当前final RDD是否处于屏障阶段
-
2)获取当前final RDD的父stage(
ShuffleMapStage) -
3)创建当前final RDD的stage(
ResultStage)并更新保存内存中的stage信息,即当前stage(ResultStage)和父stage(ShuffleMapStage)
-
3.1)调用getOrCreateParentStage获取当前
final rdd的父parentShuffleMapStage
-
3.2)获取当前finalRDD的
shuffleDependencies依赖;遍历final RDD的shuffleDependiences,然后创建ShuffleMapStage -
4)创建
ResultStage -
4.1)封装Result Stage的id、rdd、partitions和所有shuffle的Dependies信息;
-
4.2)内存中更新并保存当前Result Stage的信息(shuffleId对应的Map对象)
-
4.3)返回所有的
stagelist(Result Stage/ShuffleMap Stage)
6.1.2.2 创建shuffleMapStage
-
1)获取当前final RDD到其dependencies中最近的shuffle RDD之间的
shuffle dependencies。 例如: A(shuffle) –> B(shuffle) -> C(final RDD) 则只返回B->C
-
2)遍历父
shuffleDependencies,创建shuffleMapStage
-
2.1)根据
shuffleId获取当前父shuffle RDD的shuffleStage,如果当前shuffleStage已经存在,则直接返回 -
2.2)否则创建父shuffle RDD的
ShuffleMapStage。此过程循环调用直到所有的depedencies全部遍历完成,完成RDD的所有shuffleMapStage的创建
注意:
1)如果shuffleIdToMapStage内存中查找不到当前RDD的shuffle stage信息,首先调用getMissingAncestorShuffleDependencies获取没有注册到shuffleToMapStage中当前RDD的父shuffle dependies信息,并判断获取的dep在shuffleToMapStage中是否存在,不存在则调用createShuffleMapStage创建其父shuffleRDD的shuffle Stage
2)最终调用createShuffleMapStage创建自身的shuffle Stage。内部循环调用getOrCreateParentStages和createShuffleMapStage,遍历所有的父shuffle rdd并创建对应的stage。

-
3)创建ShuffleMapStage

-
3.1)封装
shuffle stage的shuffleId、rdd、parents、shuffleDependendies、MapOutTracker信息; -
3.2)内存中更新并保存shuffleStage的信息(shuffleId对应的Map对象)
-
3.3)判断
mapOutputTracker是否包含该shuffle stage信息,没有则将该shuffle信息(shuffleId/partition数量)封装为shuffleStatus注册到mapOutTracker中, 后续Driver上的mapOutTrackerMaster根据这个shuffleId查找该shuffle信息
6.1.2.3 为当前finalStage生成Job
-
1)根据当前的action算子及生成的stage创建
Active Job对象 -
2)将当前的active job加入到内存Map中,并和Stage的active Job字段关联
-
3)获取当前job的所有stageIds和stageInfo信息,发送Job启动的消息
-
4)提交Stage任务

补充:stage划分算法
1)DAGScheduler中根据action RDD算子创建finalStage2)finalStage中创建active Job并将job信息加入内存缓存中
3)使用submitStage提交finalStage
4)获取final RDD的shuffleDependies,遍历调用查找finalStage的父stage
5)调用getMissingParentStage查找finalStage的父stage(根据rdd的dependies判断, 如果是shuffleDependency宽依赖则生成stage,Narrow窄依赖则继续压入栈中继续向上遍历),最后返回stage列表 6)如果存在父stage, 则递归调用submitStage(如果一直存在则递归直到stage0), 将当前stage加入waitingStage待提交;
7)如果不存在stage, 则直接提交stage中未提交的tasks(submitMissingTasks)
8)后续submitMissingTask, 为stage创建一批tasks,数量等同于partitions(final RDD的); 计算每个task对应的Partition最佳位置 9)对于stage的task,创建taskset对象,调用TaskSchduler的submitTasks方法
6.1.2.4 查找父stages
-
1)对stage的active job id进行验证,如果存在,进行第2步,如果不存在,则abortStage终止
-
2)判断当前stage是否为waiting、running、failed状态,如果是则终止
-
3)调用
getMissingParentStages,遍历当前stage父RDD依赖
-
3.1)判断rdd的dependencies类型,如果是
宽依赖,则将其生成一个新的stage -
3.2)如果是
窄依赖则继续将rdd放入栈中 -
3.3)返回stage list(New Shuffle Stage | Null)
-
4)获取
getMissingParentStages返回结果
-
4.1)如果当前stage不存在未提交的父stage,则调用
submitMissingTasks方法,提交当前stage所有未提交的task -
4.2)如果当前stage存在未提交的父Stage,递归调用submitStage()直到最开始的stage0。并将当前stage加入waitingStages等待执行队列中,后续执行
-
4.3)递归调用submitStage提交所有未提交的父stage,直到最开始的stage0, 陆续调用submitMissingTasks
总结:递归调用查找
父stage, 最终执行最开始的stage0,其他的stage加入等待队列中,待后续执行
-
5)执行当前stage的submitMissingTasks提交task

6.1.2.5 提交submitMissingTasks

-
1)获取当前stage没有计算的partitions和properities
-
1.1)如果是shuffleMapStage,调用MapOutputTrackerMaster的
findMissingpartitions方法查找MapOutputTracker中需要参与计算的该stage的partitionIds
-
1.2)如果是
ResultStage, 获取当前job中未计算的partitionId
-
2)将stage添加到
runningStage中 -
3)匹配stage类型,获取task对应partition的最优资源位置来运行job(查看缓存cache中内存->查找BlockManager存储优先级别)

-
4)根据stage类型不同封装task, 传递给TaskScheduler调用task
6.1.2.6 Task提交
DAGScheduler生产DAG切分完成taskset,将taskset提交给TaskScheduler,由TaskScheduler完成task任务分配(具体的executor上)。
-
1)
TaskSchduler的submitTask方法。把tasks封装到TaskSetManager,并且放入到调度器 -
2)执行
backend.reviveOffers(), 调用CoarseGrainedSchedulerBackend的reviveOffers进行任务分配(executor最优位置分配) -
3)执行launchTasks(scheduler.resourceOffers(workOffers)), 执行task排序

6.2 Executor启动Task
CoarseGrainedSchedulerBackend调用makeOffers, 启动task任务
-
1)调用scheduler.resourceOffers(workOffers)对task排序和task任务分配(executor和task位置)

-
2)执行
launchTasks, 发送消息给CoarseGrainedExecutorBackend创建task任务,对应的Executor准备启动Task任务
-
3)CoarseGrainedExecutorBackend接收请求,调用Executor执行launchTask任务调度

-
4)Executor创建
TaskRunner线程对象,并在线程池中取出线程执行(后续task执行)
至此,task任务的划分和分配已经完成,下面我们来看下task任务在executor上的启动执行过程。
6.3 Task任务执行
6.3.1 反序列化task代码,创建TaskContext
前面说到Executor创建TaskRunner线程并执行。TaskRunner线程首先反序列化程序代码和数据,然后进行后续操作

-
1)初始化Task线程环境和TaskMemoryManager等组件
-
2)对序列化的task数据进行反序列化

-
3)远程网络通信拉取文件(文件、资源、jar等)

-
4)调用Task的runTask()方法,进行数据计算

Task可进一步分成ShuffleMapTask和ResultTask(根据shuffle宽依赖),执行不同的runTask()逻辑。
6.3.2 调用Task的runTask()方法
-
1)由ShuffleMapTask创建的ShuffleWriter执行代码定义的算子,并将结果写入到对应分区的bucket文件

-
2)ShuffleMapTask返回MapStatus到DAGScheduler MapOutputTracker中
-
3)ResultTask则直接反序列化代码,并执行func自定义方法,将结果传到driver或者输出都调用RDD.iteralator()方法

最终task在不同的executor上分布式执行,反序列化数据和执行逻辑并进行状态上报,直至任务完成。文章来源:https://www.toymoban.com/news/detail-423388.html
6.4 补充说明
由于篇幅有限且个人水平有限,spark源码暂时剖析到这里。未详尽之处后续有时间还会继续推出文章进行补充,不喜勿喷,谢谢大家~文章来源地址https://www.toymoban.com/news/detail-423388.html
到了这里,关于2万字硬核spark源码精讲手册的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!








