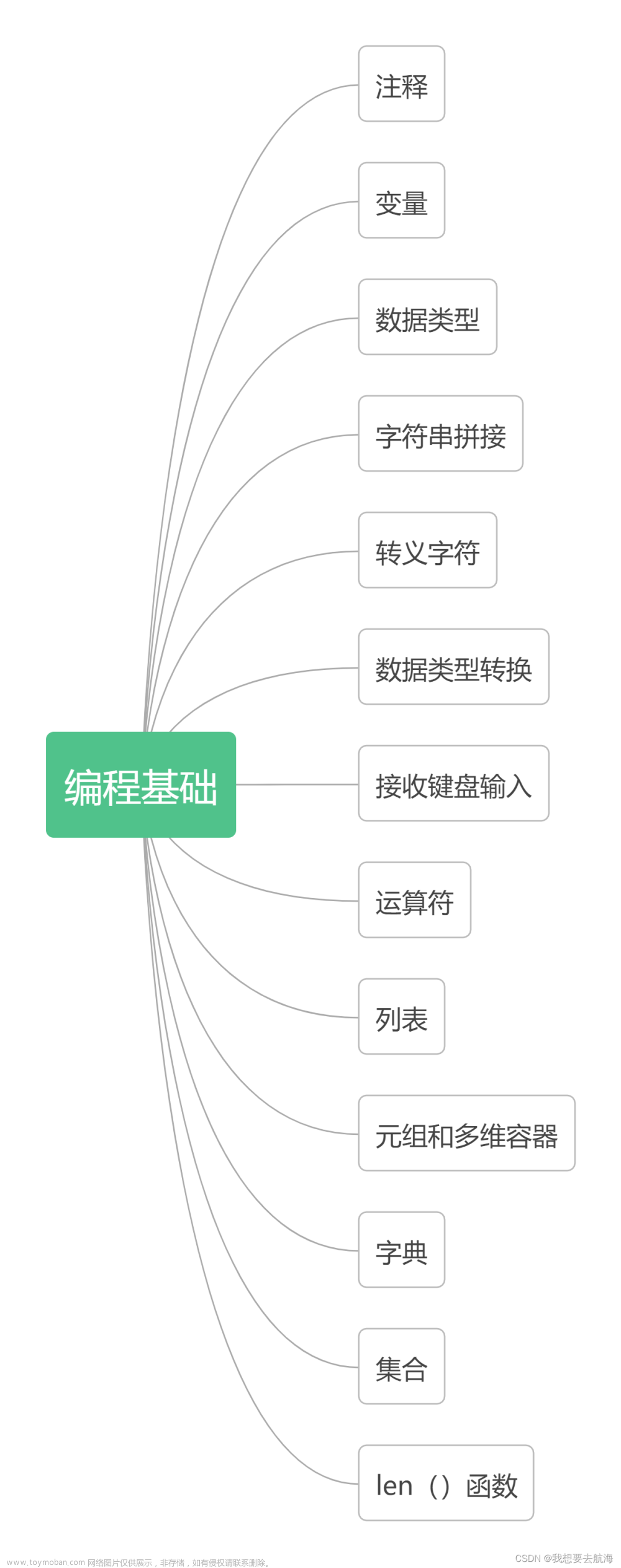
一、变量
首先要讲解的便是变量,如果你有其它语言基础,相信还是比较好理解的
我们的电脑中,很重要的一个性能指标便是内存大小,而所有的程序便是运行在内存中的:

而变量,就是在这个内存中,申请一块属于自己可以调度的内存块,有了这块内存,我们就能用它来计算、存储等等操作了
rust中声明变量有两种方式:不可变变量、可变变量
首先是不可变变量,使用关键字let
fn main() {
let a1=10;
}
它的特点便是不可再变,比如如果你想要更改它的值,就会直接报错:
但在vs code中安装了插件后,当你写出错误的代码时,就会直接给你标红。
如果你此时编译运行它,编译器同样会非常精确的给你标注出来你错在了哪里:

这里的意思就是,不可以给不可变变量赋值两次
与不可变变量相对的就是可变变量,使用方法如下:
fn main() {
let mut a1=10;
a1=20;
}
即:只需要在let关键字后面,添加一个mut关键字,就可以声明一个可变的变量了
除了上面两个变量外,rust中也有常量,也就是不可更改的,需要用到const关键字
fn main() {
const a1:i32=10;
}
可以很明显的看到,常量与不可变的变量还有有些区别的:
- 常量的名称后面必须紧跟变量的类型,比如这里的
:i32(后面马上讲解到) -
const后面不可以添加mut关键字使它可变
所以总的来说,rust中声明变量的方式非常简单,只有三个关键字:let、mut、const
除却这个,对于变量,你还需要注意一点的,rust中的变量支持隐藏,比如下面这段代码:
fn main() {
let a=10;
let a='c';
}
粗一看,就是让变量a等于两个不同类型的值:数字、字符
但由于数字与字符所占的内存大小不同,对于rust这门编译型的语言,所以这样想肯定是错的。
之所以可以这样写,是因为rust支持变量隐藏,也就是当你后面再用let等关键字等于一个值后,那么前面那个就被隐藏了
比如这里的a,一旦又了第二句,那么在第二句之后再使用a这个变量,都将等于'c',而前面那个10也并没有在内存中消失,而是被隐藏起来了,你只能在这两句的中间使用到这个数字
fn main() {
let a=10;
println!("a=={}",a); //a==10
let a='c';
println!("a=={}",a); //a==c
}
这里用到了打印宏,先记住这个用法即可,后面会再对它进行详细介绍
这个特性可以方便我们这些取名困难户,可以给很多变量取一样的名称
但要注意,下面这样写就是错误的:
fn main() {
let a=10;
a='c';
}
因为这就不是声明一个新的变量来存值,而是想要给原本的变量重新赋值,由于两者类型不同、同时a是不可变的变量,所以失败了。
二、数据类型
上面我们提到了,所谓的变量就是为了在电脑内存中申请一块内存给我们使用
那内存要申请多大的呢?这就涉及到了变量所要存储的数据类型,根据类型的不同,所申请的内存大小也是不同的
rust中的数据类型分为两种:标量 (scalar)和 复合(compound)
1.标量
首先我们来看看标量,所谓标量,代表的就是单个值,rust中标量分为四种:整型、浮点型、布尔类型和字符类型。
首先我们来看整型:
| 长度 | 有符号 | 无符号 |
|---|---|---|
| 8-bit | i8 |
u8 |
| 16-bit | i16 |
u16 |
| 32-bit | i32 |
u32 |
| 64-bit | i64 |
u64 |
| 128-bit | i128 |
u128 |
| arch | isize |
usize |
前面的长度一列,就代表这个类型要占多大的内存,而后面的有符号与无符号列,通俗来说就是可正可负的数,以及只能为正数
这里的i代表int( integer),即整数,后面的数字则代表它说要占用的内存大小
而u则代表unsigned,即无符号,后面的数字同样是它所要占用的内存大小
一般我们最常用的就是i32,即一个变量占32位内存大小,并且既可以存储正数,也可以存储负数
至于最后的一行arch,isize与usize,则代表它的大小取决去当前系统架构,如果为x86,则它等同于i32与u32,如果为x64,则它等同于i64与u64
正如我们所看见的,即使我们不注明类型,它也能默认为我们推导出来:

这是因为100这个数字字面量默认为i32,所以编译器就可以自动为什么推导出这个变量的类型
而一旦不给它赋值,又不注明它的类型,编译器就不知道这个变量需要多大的内存,所以就会直接报错:
这时我们就可以手动给它注明它的类型,编译器知道它需要多大内存,就不会报错了:

说完整形,下面我们就到浮点型了。
整形说白了就是整数,而浮点型说白了就是小数,只有两种:
| 长度 | 类型 |
|---|---|
| 32-bit | f32 |
| 64-bit | f64 |
唯一需要注意的是,小数字面量为f64类型
比如:

如果不手动指定,它就会自动推导出f64
紧跟着的便是布尔型,它只有两个可选值:true与false

如果你给赋值除了true与false之外的值,它将会直接报错
如果你学过C/C++,应该知道在C/C++中只要不为0,那就是true,这也是两种语言的区别,相比较来看,rust这样对其加以限定可以更加的安全(但对应的也减少了自由度)
布尔类型与前面两种类型不同,前面两种类型主要用于计算,而布尔类型主要用于判断,比如后面将要介绍的if判断语句,就必须要用到布尔类型
最后,就是字符类型了,它主要用于表示一个字符,使用起来也非常的简单

唯一需要注意的是,字符是用单引号,双引号指代的是字符串,这个涉及到更加深入的知识了,所以需要等到后面再讲解
2.复合类型
所谓复合类型,就是将多个上面提到的标量组合成的一种类型
而Rust 有两个原生的复合类型:元组(tuple)和数组(array)。
首先来看元组,它可以将多个不不同的数据类型放在一起组成一个新的类型,且一旦声明,它的长度就不可增加活或者减少
使用方法如下:
fn main() {
let tup=(100,'余',true,10.1);
}
比如上面这个代码,就直接将上面提到的四种标量放在一起,组成了一个元组。
注意:元组是以()表示的,里面放入各个元素,且各个元素之间用,分隔
由于rust可以自动推导出其类型,所以这里我们没有手动为其标注类型:

如果想要手动标注,就可以根据这个自动推导的格式进行标注即可
如果我们想要取出里面的值,也很简单,使用.加数字即可,就像下面这样:
fn main() {
let tup=(100,'余',true,10.1);
println!("{} {} {} {}",tup.0,tup.1,tup.2,tup.3);
}
注意下标是从0开始的,所以4个元素就只能为0到3
这里用到了println!宏进行打印输出,其第一个参数为格式化字符串,字符串中的{}叫做占位符,即将后面紧跟的参数,挨个放入这些大括号的位置,然后进行输出
后面会再对它进行更加细致的讲解
得到的输出结果就是:
100 余 true 10.1
如果元组里面没有任何参数,则称它为单元(unit) 元组,直接写作(),代表空值。
除了元组外,还有数组也很常用,它的使用方法与元组还是有点差距的,其中最大的差别就是,数组中的所有元素的类型必须相同(而上面提到的元组各个元素类型可以不同)
使用方法如下:
fn main() {
let arr=[1,2,3,4,5,6,7,8];
println!("{} {} {} {}",arr[0],arr[1],arr[2],arr[3]);
}
注意它的大小同样是不可变的(想要可变长的,后面会使用Vec,这里先略过)
它的声明使用[],访问其中的元素同样是用的[]中间添加下标的方式进行访问,而且也是从0开始的
如果你想要手动更改元素类型,可以像这里自动推导一样,手写自己想要的类型即可
比如改为
[i64;8]
前面的为数据类型,后面的为元素个数
除此之外,如果你想要赋值一个数组同样的值,那就可以像下面这样写:
let arr=[100;5];
这代表我要申请一个数组有5个元素,每个元素都等于100
三、函数
下面要介绍的便是rust中的函数了
其实在介绍函数强,我们就已经使用过函数了,最常见的main入口函数,就是一个函数
函数的目的就是可以让我们重复的使用一些代码,比如每声明一个变量,我就要打印它三次,没有函数时,就得这样写:
fn main() {
let a=10;
println!("{}",a);
println!("{}",a);
println!("{}",a);
let a=20; //用到变量隐藏的特性
println!("{}",a);
println!("{}",a);
println!("{}",a);
}
明显打印的这个步骤有些重复了,所以我们就可以将其封装为一个函数,比如下面这样:
fn main() {
let a=10;
printNum(a);
let a=20; //用到变量隐藏的特性
printNum(a)
}
fn printNum(i:i32){
println!("{}",i);
println!("{}",i);
println!("{}",i);
}
通过将打印的这个步骤封装成为一个函数,那我们就可以方便的调用它来执行任务了。
如果学过C/C++会觉得这样写有点奇怪,因为调用的地方在函数的前面,但在rust中不存在前后关系,它们都同处于一个作用域
一个最简单的函数长下面这样:
fn simple(){
}
通过关键字fn加一个函数名字,()与{}组成,除此之外什么都没有,同样,它也不能做任何事。
为了能让这个函数干一些事情,我们就需要在函数体,也就是{}中写一些代码:
fn simple(){
println!("代码");
println!("code");
//.....
}
这时,它就可以执行一些任务了。
但只是这样还不够,在没有任何输入的情况下,这个函数能做的事情基本就写死了:无论任何地方调用它,其结果都是一样的(调用随机数除外)。
所以我们就需要函数参数,也就是从函数外部传入的变量,可以让函数内部来使用,参数写在()中。
fn simple(i:i32,c:char,f:f64,b:bool){
println!("{} {} {} {}",i,c,f,b);
}
函数的参数可以有任意多个,唯一需要注意的是,各个参数都必须在其后注明类型,并且多个参数之间,要用,分隔
如果不注明,编译器也无法推断它是什么类型,从而不知道它要占用多大的内存,由此编译失败
调用它也很简单,写函数名称并在()中顺序填写对应的参数就行了
fn main() {
simple(100, 'c', 3.1415, true);
}
但仅仅只是这样仍旧不够,比如我想用函数计算两个数字之和,函数计算完成后,得把结果送回来呀!
这就用到了函数的返回值:
fn sum(a:i32,b:i32) -> i32{
return a+b;
}
即,在()与{}之间,用 ->指明这个返回值的类型即可,因为这里要返回数字和,所以用的i32类型
然后在函数内部,通过return 关键字,返回运算结果就行了。
然后当你调用这个函数时,就可以用一个变量来接收它的返回值并输出:
fn main() {
let s=sum(100,200);
println!("a+b={}",s);
}
这就是rust中最简单的函数用法,但事实上,rust中的函数,还有很多高级特性,这个留在后面再讲了。
四、注释
任何语言应该都支持注释,其作用就在于解释代码,毕竟很多项目并不是一个人就能完成的,你写的代码别人不一定能看懂。
同样的,你现在写的代码,等几个月后,你自己也未必能看懂,这时候你就能体会到注释的好处了。
注意,注释是给人看的,编译器不会管,相反,编译器会在内部首先清理掉这些注释才会开始编译代码
但rust中的注释比其它大部分语言的注释都还要更高级一点,因为它除了正常的注释外,还支持文档注释
所谓文档注释,就是你在代码中写的注释,cargo可以一键帮你生成文档。
首先来看普通注释:
fn main() {
let a=10; //声明一个类型为i32的变量
}
一个普通的注释就是这么的简单,只需要将你先解释的东西,放在 //之后就可以了,而//可以放在文件中的任何位置
如果你想要写多行注释,那就可以用多个 //
fn main() {
//声明一个
//类型为
//i32的变量
let a=10;
}
但这些写比较麻烦,所以我们还可以用 \**\
fn main() {
/*
声明一个
类型为
i32的变量
*/
let a=10;
}
除了普通的注释,我们还可以写文档注释,用于生成对应的文档
比如上面介绍函数时,就写了一个求和函数sum,我们就可以为这个函数写文档注释:
fn main() {
let s=sum(100,200);
println!("a+b={}",s);
}
/// 这是一个求和函数
/// # 例子
/// ```
/// let s=sum(100,200)
/// ```
fn sum(a:i32,b:i32) -> i32{
return a+b;
}
注意文档注释是用的///,直接写在函数的上方即可,并且这里的注释是markdown格式,比如这里的 # 代表这是个一级标题,而代码前后的 ```,就代表中间写的是代码
然后我们运行命令 cargo doc --open,就能看到浏览器打开一个帮助文档:

这里就可以看到我们的函数sum的注释了
然后点进去,你就能看到完整的注释:

上面这种方式是给指定的函数写注释并生成文档的方式
但有时我们还需要为当前整个库写注释,比如算法库,里面有求和函数、求最大函数等等的函数
为了给这个整体库写注释,我们需要用到 \\!,还是上面的那个例子,为当前程序写个注释:
//! # 我的文档注释
//!
//! 这是一个测试文档的例子程序
fn main() {
let s=sum(100,200);
println!("a+b={}",s);
}
/// 这是一个求和函数
/// # 例子
/// ```
/// let s=sum(100,200)
/// ```
fn sum(a:i32,b:i32) -> i32{
return a+b;
}
然后运行命令 cargo doc --open

就可以看到当前整个库都有注释了。
注意:我这里虽然都说的是库,但实际上rust给库定义了一个新名词:Crate
翻译过来就是箱子的意思,即装各种东西的箱子
五、控制流
控制流,说白了就是控制程序运行流程的,比如通过前面的代码,你应该已经建立起了这样的一个认知:
程序是从main函数的函数体开始,从上到下,遇到一句代码就执行一句代码,遇到一个函数,就跳到函数所在的位置执行完再返回原处,然后继续向下执行
但很多时候我们并不希望这样,比如我们要判断用户输入的一个数字,如果大于0,我们就执行大于0的语句,小于0,我们就要执行小于0的语句
这就不能直接顺序执行下来了。
还有前面曾经用过打印语句,只打印了三次还好,但如果要打三百次、三千次呢?我们同样不能手写三千条相同的语句吧!
所以这时候我们就需要改变程序原本顺序执行的流程
首先就是判断语句,例子如下:
fn main() {
let a=10;
if a>0 {
println!("a>0");
}else{
println!("a<=0");
}
}
判断语句用到的就是if关键字,后面紧跟要判断的布尔类型,如果为true,则执行紧跟其后{}中的内容
如果为false,则执行关键字else后面{}中的内容
这样就实现了在不同情况下执行不同语句的目的。
当然,
else以及紧跟其后的语句是可以省略的,这样的效果就是只要if后面的表达式不为true,那就什么都不执行
或者我们也可以增加判断分支数量:
fn main() {
let a=10;
if a>0 {
println!("a>0");
}else if a==0{
println!("a==0");
}else{
println!("a<0");
}
}
增加的方式就是在if语句的后面、else语句的前面,增加else if语句,并紧跟需要判断的语句即可
基本的比较运算符我就不再多讲了,比如这里的
a>0a==0就是两个比较运算符,分别代表大于、等于,如果是,这个运算符就会返回true,否则就会返回false,注意代码中等于是两个=,一个=叫做赋值
总的来说判断语句还是很简单的,下面我们再来介绍一下rust中的循环语句,也就是如何能用简短的几句代码,重复执行某些代码无数次
rust中的循环语句共有三个:for、while以及loop
为了简便,我们从loop开始说起,它的使用方法非常简单:
fn main() {
let a=10;
loop {
println!("{}",a);
}
}
即:只需要一个loop关键字后面跟着{},而{}中就是我们想要循环的语句
注意:这个语句是无限循环,这就是说,一旦你运行这个代码,程序就停不下来,会一直打印数字10
可以按
Ctrl+C快捷键强制暂停
如果想要让它停下来,我们还需要用到另一个关键字:break,即跳出当前循环的意思
fn main() {
let mut a=10;
loop {
println!("{}",a);
a=a+1;
if a==20{
break;
}
}
}
上面这段代码的意思就是,每打印一次,我就让a的数字加一,如果等于20了,我就调用break,跳出当前循环,然后程序结束
但这样还有有点麻烦,每次都需要我自己判断是否跳出,这时候就有了while语句:
fn main() {
let mut a=10;
while a!=20 {
println!("{}",a);
a=a+1;
}
}
while语句与loop的区别就在于,在while与{}之间,可以填写一个布尔表达式
我这里填写的是 a!=20,意思就是,只要a不等于20,就会一直循环后面的语句
但由于我在循环体内部每次都加了一个1,所以当a==20的时候,while后面的布尔表达式为false,然后就自动跳出了循环,不需要我们自己调用break
当然,如果你想要调
break,仍然是可以调用的
但如果每次遍历一系列的数字都这样写,我们可能仍然还是会觉得麻烦,这时候就有了for语句
fn main() {
for i in 10..20{
println!("{}",i);
}
}
for循环中有两个关键字,for与in,其中in后面的就是要遍历的对象,通过语法 10..20就可以自动生成一个10到20的范围对象,并将该对象中的值,依次赋值给for后面的变量名i
然后我们就可以在循环体中使用这个变量名i,一旦遍历完成,就会自动退出
注意范围运算符
..生成的范围对象是左闭右开的,具体来说,10..20,i只会等于10到19
前期知道它是如何用的就行了,后面有机会会对它介绍的更加深入
当你使用一个变量的等于它时,也会自动为你推导出它的类型:
除了基本的遍历数字外,它还可以遍历数组,但不能遍历元组:
fn main() {
let arr=[10,20,30,40];
let t=(10,'c',false);
//正确,可以遍历数组,因为每个数组的元素类型都相同
for i in arr{
println!("{}",i);
}
//错误,由于元组元素类型可能相同,所以不能这样遍历
// for i in t{
// println!("{}",i);
// }
}
当然,只要是循环,就支持使用break关键字,for循环也不例外,这里不再过多赘述
事实上,除却break关键字外,还有一个continue关键字,它不像break会直接跳出当前循环,它仅仅只是跳过当下这一次的循环
比如,我想要输出0到10之间的奇数:
fn main() {
for i in 0..10{
if i%2==0 { //如果是偶数
continue; //那就跳过当前循环,不执行后面的语句
}
println!("{}",i);
}
}
%是取余符号,如果一个数字除于2余0,那就是偶数,就调用continue,跳过当前循环,不执行后面的打印函数
否则,那就是奇数,不执行continue,也就是不跳过当前循环,执行后面的打印语句
这里介绍的是最基础的语法,rust中还有很多更加高级的用法,就留到后面章节再介绍了。
总结
rust中分为let、mut、const三个关键字用于声明变量与常量
如果为let,代表变量不可变,如果用let mut,则代表变量可变,如果为const,则代表这是一个常量,比如标注数据类型,且其后不可跟mut使之可变
然后是数据类型,分为两类:标量与复合类型
其中标量有四个类型:整型、浮点型、布尔类型和字符类型。
而复合类型只有两个:元组、数组
其中如果直接给变量赋值的话,可以省略类型注解,因为编译器可以直接推导出来
但如果你想要手动指定、或者不想赋值,那就可以自己手写类型注解,方法就是在变量名后面添加一个:然后写上类型就行了
比如:
let a:i32;
注意元组与数组最大的区别有两点:
- 元组可以存放不同类型的元素,而数组只能存放同种类型的元素
- 元素访问通过
.数字下标的方式,而数组则使用的[数字下标]
相同点就是两者的长度一旦声明了,就不可以再更改了
然后是函数,用关键字fn声明,既有参数,又有返回值的函数长下面这样:
fn name(a:i32) -> i32 {
return a;
}
然后是注释,rust中注释分为三种:
-
\\或\**\:普通注释,一般用于注释特定的几行代码 -
\\\:文档注释,一般用于注释函数,使用的markdown格式,可以直接在生成的文档中查看 -
\\!:文档注释,一般用于注释当前这个Crate(箱子,或者理解为库),同样可以在生成的文档中查看
生成文档的命令为:cargo doc
打开文档的命令为:cargo doc --open文章来源:https://www.toymoban.com/news/detail-424803.html
最后还有控制流,分为判断语句、循环语句两种文章来源地址https://www.toymoban.com/news/detail-424803.html
- 判断语句:可通过:
if、else if、else建立分支语句,根据不同情况来执行不同的语句 - 循环语句:共有三种:
loop、while、for,本质都是不断循环一段语句,但其能力是从左到右逐渐增强的
到了这里,关于rust教程 第二章 —— rust基础语法详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!