这一期我们来分享利用UI自动化方式获取视频信息
1.分析请求数据(包括解析文章请求、内容请求、视频请求、token等解析):
# -*- coding = utf-8 -*-
# ------------------------------
# @time: 2022/5/5 17:56
# @Author: drew_gg
# @File: analyze_data_news.py
# @Software: wei_chat_news
# ------------------------------
import json
import gzip
from io import BytesIO
from bs4 import BeautifulSoup
from urllib.parse import urlparse, parse_qs
from qn import common_qiniu as qn_url
def analyze_news(driver):
"""
分析账号内容
:param driver:
:return:
"""
freq = False
news_data = []
for re in driver.requests:
if "https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=" in re.url:
try:
if "freq control" in str(re.response.body):
freq = True
else:
buff = BytesIO(re.response.body)
f = gzip.GzipFile(fileobj=buff)
htmls = f.read().decode('utf-8')
news_data.append(json.loads(htmls))
except Exception as e:
print(e)
# return news_data
if "https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5" in re.url:
if "freq control" in str(re.response.body):
freq = True
return news_data, freq
def analyze_video(driver, url=''):
"""
分析账号视频
:param driver:
:param url:
:return:
"""
news_data = []
video_data = []
video_cover = []
vid = ''
cover = ''
tx_vid = ''
tx_cover = ''
for re in driver.requests:
if url and url.split('#')[0].replace('http', 'https') in re.url:
buff = BytesIO(re.response.body)
f = gzip.GzipFile(fileobj=buff)
htmls = f.read().decode('utf-8')
ht = BeautifulSoup(htmls, features="lxml")
video = ht.findAll('iframe', {'class': 'video_iframe'})
if video:
for v in video:
if "vid" in v.attrs['data-src']:
tx_vid = parse_qs(urlparse(v.attrs['data-src']).query)['vid'][0]
if tx_vid + '.png' in re.url:
tx_cover = qn_url.url_to_qiniu(re.url, 'png')
if "https://mp.weixin.qq.com/mp/videoplayer?action=get_mp_video_play_url" in re.url:
pa = re.url.split('&')
for i in pa:
if 'VID' in i.upper():
vid = i.split('=')[1]
buff = BytesIO(re.response.body)
f = gzip.GzipFile(fileobj=buff)
htmls = f.read().decode('utf-8')
html_dic = json.loads(htmls)
html_dic['vid'] = vid
news_data.append(html_dic)
# print(json.loads(htmls))
if "https://mp.weixin.qq.com/mp/videoplayer?action=get_mp_video_cover&vid=" in re.url:
pa = re.url.split('&')
for i in pa:
if 'VID' in i.upper():
vid = i.split('=')[1]
news_cover = json.loads(re.response.body)['url']
video_cover.append(vid + '@@@@' + news_cover)
# 获取TX视频的视频
if "https://vd6.l.qq.com/proxyhttp" in re.url:
buf = BytesIO(re.response.body)
f = gzip.GzipFile(fileobj=buf) # // gzip 文件498行做了修改,遇到异常中断执行,而不是抛出异常
data = f.read().decode('utf-8')
video_data.append(json.loads(data))
video_dic = {}
video_url = []
# 视频路径 //json.loads(news_data[0]['vinfo'])['vl']['vi'][0]['ul']['ui'][3]['url']
if video_data:
for n1 in video_data:
vi_dic = {}
try:
for n2 in (json.loads(n1['vinfo']))['vl']['vi']:
vi_l = []
vid = n2['vid']
for n3 in n2['ul']['ui']:
vi_l.append(n3['url'])
vi_dic['url'] = vi_l
except Exception as e:
print("解析无vinfo!")
print(e)
video_url.append(vi_dic)
video_dic[vid] = video_url
if news_data:
try:
# 如果vid相同,把cover加入news_data
for i, v1 in enumerate(news_data):
if video_cover:
for v2 in video_cover:
if v1['vid'] == v2.split('@@@@')[0]:
cover = v2.split('@@@@')[1]
else:
cover = ''
news_data[i]['cover'] = cover
except Exception as e:
print(e)
return news_data, video_dic, tx_cover
def analyze_token(driver):
"""
分析账号token
:param driver:
:return:
"""
news_data = []
for re in driver.requests:
if "https://mp.weixin.qq.com/cgi-bin/home?t=home/index&lang=zh_CN&token=" in re.url:
pa = re.url.split('=')[-1]
news_data.append(pa)
return news_data
2.获取视频主方法:
def get_video_main():
"""
爬取文章视频
:return:
"""
news_link = read_sql.deal_mysql("get_news_link.sql")
if news_link:
for i in news_link:
link_url = i[4]
print(" get video ing !")
driver = video.get_video(link_url)
try:
time.sleep(1)
# 获取文章数据
news_data, video_dic, tx_cover = analyze_news.analyze_video(driver, link_url)
# 如果有TX视频
if video_dic:
for k, y in video_dic.items():
if k != '':
for v in y:
video_url = m3u8_mp4.m3u8_mp4_main(v['url'][0])
vid = k
if video_url:
in_video.insert_video_tx(i, vid, video_url, tx_cover)
un.update_news(i[0])
else:
print("无视频数据")
# 数据插入数据库
in_video.insert_video(i, news_data)
if news_data:
un.update_news(i[0])
except Exception as e:
print(e)
finally:
driver.quit()
else:
print("暂无数据处理!")
3.内容详情处理方法:
def get_content_main():
"""
获取文章详情
:return:
"""
video_format = ' controlslist="nodownload"' \
' style="margin-right: auto;margin-left: auto;outline: 0px;' \
'box-sizing: border-box;' \
'vertical-align: inherit;' \
'display: block;clear: both;overflow-wrap: break-word !important;' \
'visibility: visible !important; max-width: 100%;' \
'" controls="controls" src="'
news_link_l = read_sql.deal_mysql("get_news_for_content.sql")
if news_link_l:
for i in news_link_l:
news_id = i[0]
news_title = i[1]
news_link = i[2]
have_video = i[3]
print(datetime.datetime.now(), '*********** get content ing !')
# 获取内容
news_content, news_video, img_l, source = content.get_content(news_link)
# # 更新视频表封面图
# for c, k in cover.items():
# in_video.update_video(vid=c, is_cover=1, cover=k)
# data-src替换成src,把隐藏参数去掉
news_content_all = news_content.replace('data-src', 'src').replace(' style="visibility: hidden;"', '')
# url图片转存七牛并替换
for im in img_l:
time.sleep(0.1)
new_img = qn_url.url_to_qiniu(im, 'png')
news_content_all = news_content_all.replace(im, new_img)
news_dic = [{'news_id': str(news_id)}]
if have_video == 1:
sql_result = read_sql.deal_more_mysql("get_video_for_content.sql", news_dic)
if sql_result:
for v1 in sql_result:
video_html = '<video poster="' + v1[4] + '"' + video_format + v1[1] + '"></video>'
for v2 in news_video:
if v1[0] in str(v2):
news_content_all = news_content_all.replace(str(v2).replace('data-src', 'src'), video_html)
else:
print('视频还未转存')
continue
# 插入内容
try:
in_content.insert_content(news_id, news_title, news_content_all, source)
except Exception as e:
print(e)
# 更新weichat_news表的is_content字段
un.update_news(news_id, 1)
else:
print("暂无数据处理!")
4.遇到m3u8视频,处理方法:
# -*- coding = utf-8 -*-
# ------------------------------
# @time: 2022/5/23 11:21
# @Author: drew_gg
# @File: get_m3u8.py
# @Software: wei_chat_news
# ------------------------------
import os
import time
import random
import requests
import subprocess
import urllib3
from qn import common_upload as qiniu
urllib3.disable_warnings()
project_path = os.path.abspath(os.path.dirname(__file__))
video_path = os.path.abspath(os.path.join(os.path.dirname(__file__), 'video'))
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
def get_user_agent():
header = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'content-type': 'application/json',
'x-requested-with': 'XMLHttpRequest',
'Accept-Language': 'zh-CN,zh;q=0.8',
'User-Agent': random.choice(user_agent_list)}
return header
def get_m3u8_file(url_m3u8, timeout=(10, 30), max_retry_time=3):
"""
获取m3u8信息
:param url_m3u8: m3u8的视频地址
:param timeout: 超时时间
:param max_retry_time: 尝试次数
:return:
"""
# 获取主域名的完整路径
host_path = get_path(url_m3u8)
# 随机获取headers,防止被认为机器刷
headers = get_user_agent()
i = 1
while i <= max_retry_time:
try:
res = requests.get(url=(url_m3u8.rstrip()).strip(), headers=headers, timeout=timeout, verify=False)
if res.status_code != 200:
return None
# res.text 返回ts信息目录
return host_path, res.text
except Exception as e:
print(e)
i += 1
return None
def deal_m3u8_file(host_path, content_m3u8):
"""
处理m3u8记录,获取单个的ts文件
:param host_path: 主目录路径
:param content_m3u8: m3u8记录
:return:
"""
ts_file = {}
content_m3u8 = content_m3u8.split('\n')
for i, m in enumerate(content_m3u8):
if "#EXTINF:" in m:
ts_file[content_m3u8[i+1].split('?')[0]] = host_path + content_m3u8[i+1]
if "#EXT-X-ENDLIST" in m:
break
# ts_file 返回ts字典{'ts名称':'ts连接'}
return ts_file
def get_path(url):
"""
获取域名目录
:param url: m3u8连接
:return:
"""
if url.rfind("/") != -1:
return url[0:url.rfind("/")] + "/"
else:
return url[0:url.rfind("\\")] + "\\"
def download_ts_video(ts_url):
"""
下载ts文件
:param ts_url:
:return:
"""
# 通过ts链接下载ts文件
ts_name = str(int(time.time() * 1000000))
save_ts_path = video_path + '\\' + ts_name + '\\'
# 创建存放ts文件的目录
cmd = "md %s" % save_ts_path
os.popen(cmd)
time.sleep(1)
# 存放ts顺序与名称文件的txt文件名称
ts_record_file = save_ts_path + ts_name + '.txt'
# 构建copy /b 字符串 ts_str
ts_str = ''
# ts写入ts_record_file
with open(ts_record_file, "w+") as f:
for k, y in ts_url.items():
try:
response = requests.get(y, stream=True, verify=False)
except Exception as e:
print("异常请求:%s" % e.args)
# 下载后ts文件的名称
ts_path_file = save_ts_path + k
# 下载ts文件
with open(ts_path_file, "wb+") as file:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
file.write(chunk)
f.write("file '%s'\n" % k)
ts_str += k + '+'
return ts_record_file, save_ts_path, ts_str.strip('+')
def ts_to_mp4(ts_txt, save_ts_path, ts_str):
"""
合并ts文件生成mp4文件
:param ts_txt: ts记录表txt文件 // 用于ffmpeg合并所用
:param save_ts_path: 存放ts文件路径
:param ts_str: ts顺序串 // 1.ts + 2.ts + 3.ts + ……
:return:
"""
# 存放txt文件的名称
txt = ts_txt.split(save_ts_path)[1]
# 合并后存放视频的名称
video_name = txt.split('.')[0] + '.mp4'
# 生成copy /b 命令
copy_cmd = "cd /d " + save_ts_path + "© /b " + ts_str + ' ' + video_name
# 生成ffmpeg命令 //由于windows下python无法用管理员执行ffmpeg,只能舍弃这种合并方式
# ffmpeg_cmd = "cd /d %s & ffmpeg -f concat -safe 0 -i %s -c copy %s" % (save_ts_path, txt, video_name)
# print(copy_cmd)
# print(ffmpeg_cmd)
try:
# 管道cmd模式执行cmd命令,可以收到命令执行结果
subprocess.check_output(copy_cmd, shell=True, stderr=subprocess.PIPE)
# ffmpeg的命令
# subprocess.Popen(ffmpeg_cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
except subprocess.CalledProcessError as err:
raise AssertionError('合并文件失败!')
return save_ts_path + video_name
def m3u8_mp4_main(url):
"""
获取m3u8信息下载并上传七牛并转码 // 暂时没有处理加密的ts文件
:param url:
:return:
"""
# 获取m3u8信息 // ts文件信息和主目录路径
video_download_url = ''
try:
host_path, text_m3u8 = get_m3u8_file(url)
# 获取具体ts信息,ts_file字典{'ts名称':'ts连接'}
ts_file = deal_m3u8_file(host_path, text_m3u8)
# 下载ts文件,获取ts文件存放路径,copy /b命令需要的ts字符串、ffmpeg执行所需要的ts文件txt信息
record_file_ts, ts_path_save, str_ts = download_ts_video(ts_file)
# 获取合并后的文件
video_file = ts_to_mp4(record_file_ts, ts_path_save, str_ts)
# 视频上传七牛并转码
video_download_url = qiniu.upload_qiniu(video_file)
except Exception as e:
print(e)
finally:
return video_download_url
if __name__ == '__main__':
m3u8_url = "https://apd-vlive.apdcdn.tc.qq.com/defaultts.tc.qq.com/svp_50001/D9WbuxKxEK_3ORIxMGPmLkb_Hf-9EYaHERGcUiwKAObEk-a" \
"C0oWDQrKibK2oJu9pTk6cCYTLBJ7Ya_890oNNu3dwYOVwrsvU9m0A7bjXVSnVUWQ8BAb_6iyUrfHJdj6JLB9ORCEBpj6FY8Ew97akeKokNWBTMwN2Cmy" \
"4xm72amqgqHo3zn0lSA/szg_6565_50001_0bc3waaaiaaagyamd24b4jrfdmgdasyaabca.f341003.ts.m3u8?ver=4"
m3u8_mp4_main(m3u8_url)
常规视频分析如图(一般都是三个视频,超清、高清、流畅,至少有两个):

m3u8的视频:
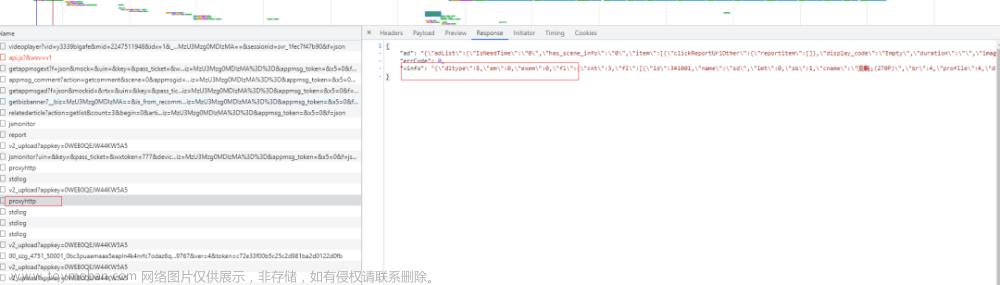
解析vinfo后一般有3个m3u8地址:
{'url':'https://apd-ab3bfda6e3c7f17903673bc29aa63be3.v.smtcdns.com/omts.tc.qq.com/AwfBnjY0sy7CusqUlUD8AyDJttC4uz-symHTokgF7fts/uwMROfz2r57EIaQXGdGnCmdeOm5ieD5vLVPWVxBgVS8DGd80/svp_50001/6JH7xBzZnXGE6Alc3apP8D4zuLTz0odtRlLJgtXefYU36iQhSBOLVoZp2S5N-SNIZ3x1oed-eIUVs_G-fLiqfq0LcwjmKOI353EmSEI_qltjWg0pnPvzVL-SjsSf5jD83PHEkaXv7JjRWPdNPPbt18hkmeDySTlIhMZkKdCn8X7P-Zz-5Iku_Q/szg_4751_50001_0bc3puaamaaa5eapln4k4nrfc7odaz6qabsa.f304110.ts.m3u8?ver=4','vt':2806,'dtc':0,'dt':2},
{'url':'https://apd-19bad465f8d944562bdc26c7556258de.v.smtcdns.com/omts.tc.qq.com/AwfBnjY0sy7CusqUlUD8AyDJttC4uz-symHTokgF7fts/uwMROfz2r57EIaQXGdGnCWdeOm4EnYbsz8uMYzCQBiqsbQpy/svp_50001/6JH7xBzZnXGE6Alc3apP8D4zuLTz0odtRlLJgtXefYU36iQhSBOLVoZp2S5N-SNIZ3x1oed-eIUVs_G-fLiqfq0LcwjmKOI353EmSEI_qltjWg0pnPvzVL-SjsSf5jD83PHEkaXv7JjRWPdNPPbt18hkmeDySTlIhMZkKdCn8X7P-Zz-5Iku_Q/szg_4751_50001_0bc3puaamaaa5eapln4k4nrfc7odaz6qabsa.f304110.ts.m3u8?ver=4','vt':2806,'dtc':0,'dt':2},
{'url':'https://apd-vlive.apdcdn.tc.qq.com/defaultts.tc.qq.com/svp_50001/6JH7xBzZnXGE6Alc3apP8D4zuLTz0odtRlLJgtXefYU36iQhSBOLVoZp2S5N-SNIZ3x1oed-eIUVs_G-fLiqfq0LcwjmKOI353EmSEI_qltjWg0pnPvzVL-SjsSf5jD83PHEkaXv7JjRWPdNPPbt18hkmeDySTlIhMZkKdCn8X7P-Zz-5Iku_Q/szg_4751_50001_0bc3puaamaaa5eapln4k4nrfc7odaz6qabsa.f304110.ts.m3u8?ver=4','vt':12800,'dtc':0,'dt':2}
目前看TX视频都是m3u8格式,好在ts文件都是没有加密的,所以也就没做解密处理。
强调几点:
1.视频的封面图和视频,都是有vid的,通过vid相同来处理视频的封面图,也是根据vid来替换视频,比如一篇文章中有多个视频。
2.账号执行表是为了处理异常执行情况,比如执行到一半,被封禁了,下次执行又得所有账号在来一遍,浪费时间,所以加了一个patch来标志,没执行完的pitch继续执行,执行完了下次执行时最大的patch加1,这样就保障了这些任务。

视频记录:

钉钉处理登录情况:
再次说明:以上仅供分享学习,请不要用于恶意爬虫!!
资源分享
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走…
文章来源:https://www.toymoban.com/news/detail-430194.html
喜欢软件测试的小伙伴们,如果我的博客对你有帮助、如果你喜欢我的博客内容,请 “点赞” “评论” “收藏” 一 键三连哦! 文章来源地址https://www.toymoban.com/news/detail-430194.html
文章来源地址https://www.toymoban.com/news/detail-430194.html
到了这里,关于干货,用UI自动化方式获取视频信息,请勿恶意爬虫的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!