1. seq2seq模型,输入是一个词向量,而不是词向量列表,对吧?
是的,对于seq2seq模型,输入和输出都需要被转换成词向量形式。
对于输入来说,通常会将一个句子转换成一个词向量序列。具体地,对于每个单词或者字符,都会将其对应成一个词向量,然后将所有词向量按照它们在句子中的顺序排列。这个序列作为seq2seq模型的输入,并且会在输入序列的开始位置添加一个特殊的起始标记(如<start>)。
对于输出来说,也需要将其转换为词向量形式。但不同于输入,输出通常是逐个生成的,即在预测下一个单词时,会将前面生成的单词作为条件输入到模型中。因此,在每个时间步骤中,要将当前输出单词转换成一个词向量,并将其指定为下一个时间步骤的输入。
综上所述,对于seq2seq模型来说,输入和输出都需要被转换成词向量形式,但它们的形式是不同的。输入是词向量序列,而输出则是逐个生成的词向量。
2. seq2seq模型的输入层,只能是一个单一的词向量,对吧?
不完全如此。seq2seq模型的输入层可以接受多个词向量的输入。在实际应用中,通常采用embedding方式将一段文本序列中的每个单词或字符转化成一个定长的词向量表示,这些词向量按照它们出现在序列中的顺序组成一个矩阵,然后输入到seq2seq模型的输入层中。
在输入到seq2seq模型时,这个矩阵通常还需要加上特殊的标记,比如<start>和<end>,用于表示序列的开始和结束位置。这样做可以帮助模型更好地把握序列的语义,并提高模型的预测准确率。
需要注意的是,在具体应用中,输入层的形式是可以根据情况进行调整的,使用何种输入层形式最适合取决于实际场景和数据特点。
3. 输入层采用单个词向量与采用多个词向量,两种方案各有什么特点?
使用单个词向量作为输入层,常见的做法是将一段序列中的所有单词或字符编码成一个定长的词向量表示,这个词向量可以被看做是整个序列的语义表示。这种方式的好处是,可以在一定程度上简化模型结构和计算复杂度,同时也避免了序列长度不同带来的问题。
使用多个词向量作为输入层,则需要将序列中每个单词或字符分别编码成词向量表示,并按照其在序列中的顺序组成一个矩阵。这种方式的优点是,可以更好地保留序列中每个单词或字符的信息,从而提高模型的表示能力。
在具体应用中,选择哪种方式取决于实际场景和数据特点。如果序列长度相对较短,且语义信息主要集中在整个序列中,那么使用单个词向量作为输入层可能会更加合适。如果序列长度比较长,且语义信息分布在序列的各个位置上,那么使用多个词向量作为输入层可能会更有效。
需要注意的是,无论使用哪种方式,都需要对序列进行预处理,以便将序列转化成神经网络所需要的输入形式。同时,还需要根据具体应用场景设计合适的模型结构和超参数,以便获取最佳的性能。
4. Chatbot 算法模型的输入是单个词向量,还是多个词向量?
Chatbot算法模型的输入通常是多个词向量,而不是单个词向量。聊天机器人需要理解用户给出的整个语句,而不是仅仅理解一个单独的单词。因此,在训练Chatbot模型时,通常会使用自然语言处理技术来将输入的文本转化为向量序列,并将其提供给模型进行处理。这些向量通常表示输入的句子中每个单词的嵌入向量,从而使模型能够在理解整个句子的基础上生成回复。
5. 我想构建并训练一个聊天算法模型,感觉应该是一个seq2seq模型,请问该模型的输入层采用单个词向量,还是采用多个词向量?
Seq2seq模型用于聊天机器人的训练,通常采用的输入层是多个词向量,而不是单个词向量。这是因为聊天机器人需要理解整个语句的意义和上下文,而不是仅仅理解一个单一的单词。因此,在Seq2seq模型的训练中,通常将输入文本转化为多个词向量序列,并将其作为模型的输入。在这些词向量序列中,每个词向量通常代表输入句子的一个单词或子序列的特征向量。同时,通常还会使用注意力机制来帮助模型捕捉输入序列中每个单词对回复生成的重要性,并影响回复的生成过程。
6. 那么这个模型的输出层应该是什么形式?
Seq2seq模型的输出层通常使用softmax层,用于对单词表中每个单词的概率进行建模。在聊天机器人中,每个时间步模型都会预测下一个最有可能出现的单词,这类似于一种向前预测,可以不断地迭代直到生成完整的回复。因此,输出层通常是一个基于单词表大小进行softmax归一化的向量,每个元素代表在该位置处预测单词的概率,然后从这些分布中采样选择概率最高的单词作为输出,并将其输入到下一时间步进行迭代预测回复。该方法可以在训练时最大化目标序列的似然概率,并产生更准确和连贯的回复。
7. 聊天机器人的输入和输出,是采用两个相对独立的网络模型吗?
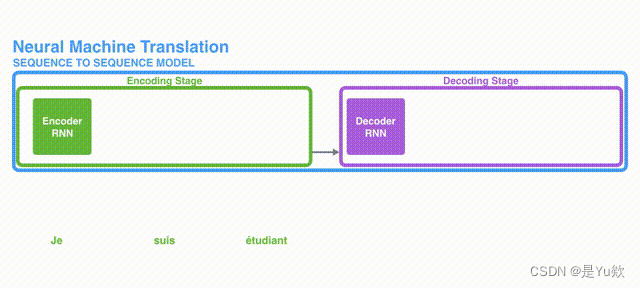
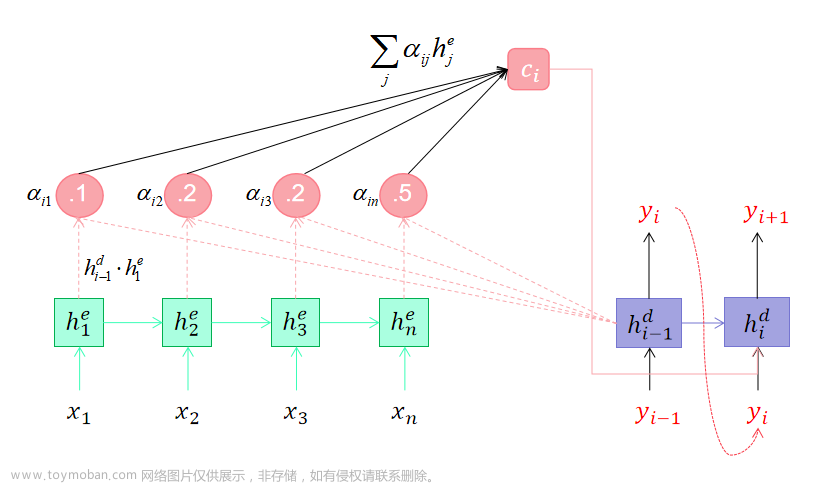
是的,一般情况下聊天机器人采用的是序列到序列(Sequence-to-sequence)模型,它由两个相对应的循环神经网络(RNN)组成,分别被称为Encoder和Decoder。
Encoder负责将输入文本序列编码成一个固定长度的向量,它可以是最后一个时间步的RNN隐藏状态或者是所有时间步的隐藏状态的平均值,后者也称为上下文向量或Encoder输出,其维度一般与隐藏状态相等。Encoder的作用是将输入文本内容进行抽象和编码,以便在之后的Decode阶段使用。
根据不同的任务和应用场景,Decoder可以采用不同的形式和结构,例如单层或多层RNN、LSTM、GRU以及更高级别的Transformer(自注意力模型),Decoder的输入依次是上一个时间步的输出和上下文向量。Decoder的目标是生成对应于输入序列的输出序列,因此将Encoder产生的上下文向量与Decoder输入进行结合,以便在逐步预测输出序列时,保存先前的信息,并生成一致的回复。
两个网络模型实际上是共同训练的。 在训练过程中,Encoder和Decoder都被联合优化,通过比较Ground Truth与模型生成的输出之间的差异来计算损失函数,并通过反向传播算法更新模型的权重参数。最终,模型学习从输入到输出的映射关系,实现自然语言回复的生成。
8. <start>这样的特殊标记,对应的词向量如何选择?用零向量表示这样的标记行吗?
<start>这样特殊的标记通常称为开始标记或起始标记,它是序列到序列模型中的一种常见设计。而对于这类特殊的标记,其对应的词向量可以人工设置,也可以使用训练得到的词向量。通常采用的方法包括:
-
随机初始化。可以将起始标记的词向量随机生成一个新的向量,并通过后续的训练来逐渐调整。
-
借鉴预训练的词向量。可以使用现有的预训练好的词向量(如Word2Vec、GloVe等)对起始标记进行初始化。
-
其他方式。还可以采用其他一些特殊的向量表示方式,比如全零向量、均值向量等。
需要注意的是,并不是所有的情况下都需要对起始标记进行初始化。对于某些任务(如翻译任务),起始标记的选择并不会对模型的性能产生巨大影响,因此可以选择不加以处理或采用简单的全零向量进行初始化。而对于某些任务(如语音识别任务),由于起始标记的位置信息对于后续的预测非常重要,因此采用一个合理的初始化方案有助于提升模型的性能。
9. Seq2seq模型的encode和decode之间是如何衔接的?
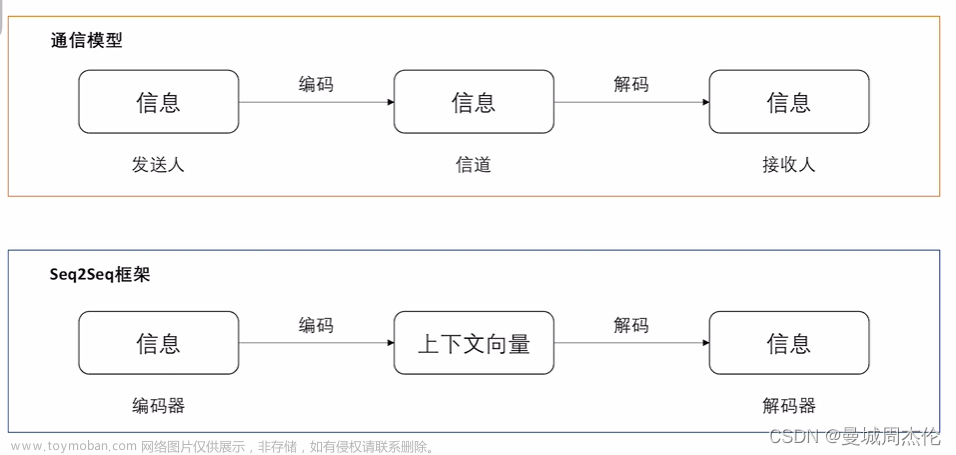
Seq2Seq(Sequence-to-Sequence)模型是一种神经网络模型,通常用于解决序列到序列的任务,例如自然语言翻译、语音识别和文本摘要等。
在Seq2Seq模型中,编码器(Encoder)将输入序列编码成一个向量表示,而解码器(Decoder)则将该向量解码成另一个序列。衔接的关键在于编码器和解码器之间所使用的共享权重矩阵。
具体来说:
-
编码器将输入序列中的每个单词依次输入到RNN(循环神经网络)中,每个时间步上的输出被传递给下一个时间步,并且被用于生成下一个时间步的状态。最终,编码器会输出一个向量,该向量包含了输入序列的所有信息。
-
解码器会对目标序列进行逐个预测,每个时间步都会基于前面的预测结果和编码器输出的向量来更新RNN的状态,并生成下一个单词的概率分布。由于编码器和解码器使用相同的权重矩阵,因此编码器输出的向量可以看作是解码器的初始隐藏状态。
-
为了使解码器能够正确衔接编码器的输出向量,通常需要对编码器输出的向量进行一些加工。最常见的方式是将该向量作为解码器的初始隐藏状态,并在每个时间步上将其与解码器当前的隐藏状态拼接起来,然后再输入到RNN中进行预测。
因此,Seq2Seq模型的衔接关键在于共享权重矩阵和将编码器输出向量转化为初始化解码器的隐藏状态。
10. Decode如何确定当前输出是输出序列的终点?
在Seq2Seq模型中,解码器如何确定当前输出是否已经结束取决于解码器的设计和任务的特定需求。以下是一些常见的策略:
-
固定长度输出:解码器根据事先设定好的序列长度来进行解码操作,不管任务需要生成多长的序列,都只会生成一个固定长度的序列。当解码器生成了指定数量的单词或达到了预先决定的结束符号时,就认为序列生成完成。
-
基于结束符号的输出:在某些任务中,目标句子的长度可能是可变的,这时可以通过设定一些特殊的结束符号来表示序列的结束。在解码的过程中,当解码器预测到了结束符号时,就认为序列生成完成,停止解码操作。
-
基于Attention机制的输出:在Seq2Seq模型中,当解码器解码完前面的部分时,它需要在整个输入序列中选择合适的信息来生成下一个单词。这时,通过Attention机制可以让解码器关注源序列中的不同部分,并给予不同的权重。当解码器在所有的位置都输出了一个结束符号或者达到了一个最大输出长度时,就认为序列生成完成。
-
基于概率的结束:在某些任务中,序列的长度可能是不确定的,也没有指定的结束符号。这时,可以通过预测输出单词的概率来判断序列生成是否完成。当解码器无法预测下一个单词的概率超过某个设定的阈值时,认为序列生成已经完成。文章来源:https://www.toymoban.com/news/detail-462381.html
综上所述,Seq2Seq模型中解码器如何确定当前输出是否结束取决于具体任务的需求以及解码器的设计。文章来源地址https://www.toymoban.com/news/detail-462381.html
到了这里,关于构建seq2seq模型的常见问题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!