为什么叫支持向量机
在第二章中我们学过感知机,它是最小化所有误分类点到超平面的距离之和, M 为误分类点的集合,得到的分离超平面是不唯一的。
min
ω
,
b
[
−
∑
x
i
∈
M
y
i
(
ω
⋅
x
i
+
b
)
]
\min_{\omega,b}[-\sum_{x_i \in M}y_i (\omega\cdot x_i+b)]
ω,bmin[−xi∈M∑yi(ω⋅xi+b)]
在支持向量机中,
{
分类确信度
∣
ω
⋅
x
i
+
b
∣
∣
∣
ω
∣
∣
分类正确性
y
i
(
ω
⋅
x
i
+
b
)
⇒
几何间隔
γ
i
=
y
i
(
ω
⋅
x
i
+
b
)
∣
∣
ω
∣
∣
\begin{cases} 分类确信度 \frac{|\omega\cdot x_i+b|}{||\omega||}\\ 分类正确性 y_i(\omega\cdot x_i +b) \end{cases} \Rightarrow几何间隔\gamma_i=\frac{y_i(\omega\cdot x_i +b)}{||\omega||}
{分类确信度∣∣ω∣∣∣ω⋅xi+b∣分类正确性yi(ω⋅xi+b)⇒几何间隔γi=∣∣ω∣∣yi(ω⋅xi+b)
哪些样本最有用?就是几何间隔最小的点
min
γ
i
\min \gamma_i
minγi。
然后使得几何间隔最小的点最大
max
ω
,
b
min
γ
i
\max_{\omega,b}\min \gamma_i
maxω,bminγi,一看这形式就知道要使用到最大熵章节讲到的原始问题和对偶问题。
R
n
R^n
Rn空间中点和向量是等价的,最有用的那些点
min
γ
i
\min \gamma_i
minγi称为支持向量。
线性可分支持向量机
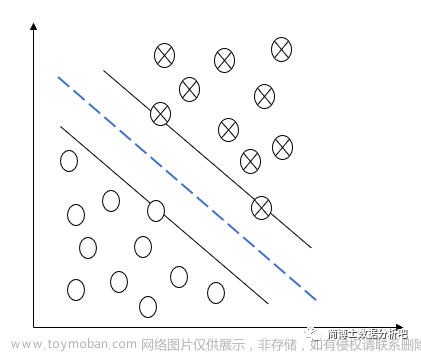
线性可分支持向量机是可以将样本点完全分类开来,但是这种情况在现实中是很少的,但是它是最简单的支持向量机。我们先理清它的过程,还有一些证明,后面的向量机都是在它的基础上发展的。
假设有 N 个样本,M 个特征 ,Y 只有正类(+1)和负类(-1)
几何间隔和函数间隔
几何间隔的定义(点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)到超平面
ω
⋅
x
+
b
=
0
\omega\cdot x + b=0
ω⋅x+b=0的距离):
γ
i
=
∣
ω
⋅
x
i
+
b
∣
∣
∣
ω
∣
∣
=
y
i
(
ω
⋅
x
i
+
b
)
∣
∣
ω
∣
∣
=
y
i
(
ω
∣
∣
ω
∣
∣
⋅
x
i
+
b
∣
∣
ω
∣
∣
)
\begin{aligned} \gamma_i&=\frac{|\omega\cdot x_i +b|}{||\omega||}\\ &=\frac{y_i(\omega\cdot x_i +b)} {||\omega||}\\ &=y_i(\frac{\omega}{||\omega||}\cdot x_i+\frac{b}{||\omega||}) \end{aligned}
γi=∣∣ω∣∣∣ω⋅xi+b∣=∣∣ω∣∣yi(ω⋅xi+b)=yi(∣∣ω∣∣ω⋅xi+∣∣ω∣∣b)
几何间隔的最小值
γ
=
min
i
γ
i
\gamma = \min_i \gamma_i
γ=miniγi
优化问题为:
max
ω
,
b
γ
s
.
t
.
y
i
(
ω
∣
∣
ω
∣
∣
⋅
x
i
+
b
∣
∣
ω
∣
∣
)
≥
γ
,
i
=
1
,
2
,
.
.
.
,
N
\begin{aligned} & \max_{\omega,b}\quad \gamma\\ &s.t. \quad y_i(\frac{\omega}{||\omega||}\cdot x_i+\frac{b}{||\omega||})\ge \gamma,i=1,2,...,N \end{aligned}
ω,bmaxγs.t.yi(∣∣ω∣∣ω⋅xi+∣∣ω∣∣b)≥γ,i=1,2,...,N
函数间隔的定义:
γ
^
i
=
∣
ω
⋅
x
i
+
b
∣
=
y
i
(
ω
⋅
x
i
+
b
)
\begin{aligned} \hat\gamma_i&={|\omega\cdot x_i +b|}\\ &={y_i(\omega\cdot x_i +b)} \\ \end{aligned}
γ^i=∣ω⋅xi+b∣=yi(ω⋅xi+b)
函数间隔的最小值
γ
^
=
min
i
γ
^
i
\hat\gamma = \min_i \hat\gamma_i
γ^=miniγ^i
优化问题为:
max
ω
,
b
γ
^
/
∣
∣
ω
∣
∣
s
.
t
.
y
i
(
ω
⋅
x
i
+
b
)
≥
γ
^
,
i
=
1
,
2
,
.
.
.
,
N
\begin{aligned} & \max_{\omega,b}\quad \hat\gamma/||\omega||\\ &s.t. \quad {y_i(\omega\cdot x_i +b)}\ge \hat\gamma,i=1,2,...,N \end{aligned}
ω,bmaxγ^/∣∣ω∣∣s.t.yi(ω⋅xi+b)≥γ^,i=1,2,...,N
怎么将几何间隔和函数间隔联系起来?
第一种:将
ω
\omega
ω归一化,即
∣
∣
ω
∣
∣
=
1
||\omega||=1
∣∣ω∣∣=1
以下这三种超平面的
ω
,
b
\omega,b
ω,b不一样,但是表示的是同一个超平面。
3
x
(
1
)
+
4
x
(
2
)
+
1
=
0
6
x
(
1
)
+
8
x
(
2
)
+
2
=
0
3
5
x
(
1
)
+
4
5
x
(
2
)
+
1
5
=
0
3x^{(1)}+4x^{(2)}+1=0\\ 6x^{(1)}+8x^{(2)}+2=0\\ \frac{3}{5}x^{(1)}+\frac{4}{5}x^{(2)}+\frac{1}{5}=0\\
3x(1)+4x(2)+1=06x(1)+8x(2)+2=053x(1)+54x(2)+51=0
将
ω
\omega
ω归一化后,函数间隔和几何间隔就是等价的,此时优化问题为:
max
ω
,
b
γ
^
/
∣
∣
ω
∣
∣
s
.
t
.
{
y
i
(
ω
⋅
x
i
+
b
)
≥
γ
^
,
i
=
1
,
2
,
.
.
.
,
N
∣
∣
ω
∣
∣
=
1
\begin{aligned} & \max_{\omega,b}\quad \hat\gamma/||\omega||\\ &s.t. \begin{cases} {y_i(\omega\cdot x_i +b)}\ge \hat\gamma,i=1,2,...,N\\ ||\omega ||=1 \end{cases} \end{aligned}
ω,bmaxγ^/∣∣ω∣∣s.t.{yi(ω⋅xi+b)≥γ^,i=1,2,...,N∣∣ω∣∣=1
第二种:对
γ
^
\hat\gamma
γ^做处理,和刚刚三个超平面处理类似,对
ω
,
b
\omega,b
ω,b进行放缩,可以使得
γ
^
=
min
i
γ
^
i
=
1
\hat\gamma=\min_{i}\hat\gamma_i=1
γ^=miniγ^i=1
此时优化问题为:
min
ω
,
b
∣
∣
ω
∣
∣
s
.
t
.
y
i
(
ω
⋅
x
i
+
b
)
≥
1
,
i
=
1
,
2
,
.
.
.
,
N
\begin{aligned} & \min_{\omega ,b}\quad ||\omega||\\ &s.t. \quad {y_i(\omega\cdot x_i +b)}\ge 1,i=1,2,...,N\\ \end{aligned}
ω,bmin∣∣ω∣∣s.t.yi(ω⋅xi+b)≥1,i=1,2,...,N
显然,第二种处理能使得问题更加简单。
证明分离超平面存在且唯一
目标函数是凸函数,约束条件是放射函数,所以这个凸优化问题存在最优解。
现在证最优解是唯一的(反证法):

原始问题算法流程
输入:数据集
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
N
,
y
N
)
}
,
y
i
∈
{
+
1
,
−
1
}
T=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\},y_i\in \{+1,-1\}
T={(x1,y1),(x2,y2),...,(xN,yN)},yi∈{+1,−1}
输出:最大间隔分离超平面与决策函数
- 构造优化问题
min
ω
,
b
1
2
∣
∣
ω
∣
∣
2
s
.
t
.
1
−
y
i
(
ω
⋅
x
i
+
b
)
≤
0
,
i
=
1
,
2
,
.
.
.
,
N
\begin{aligned} & \min_{\omega ,b}\quad \frac{1}{2}||\omega||^2\\ &s.t. \quad 1-{y_i(\omega\cdot x_i +b)}\le 0,i=1,2,...,N\\ \end{aligned}
ω,bmin21∣∣ω∣∣2s.t.1−yi(ω⋅xi+b)≤0,i=1,2,...,N
所得解为
ω
∗
,
b
∗
\omega^* ,b^*
ω∗,b∗
- 分离超平面
ω
∗
⋅
x
+
b
∗
=
0
\omega^*\cdot x + b^*=0
ω∗⋅x+b∗=0
决策函数
f
(
x
)
=
s
i
g
n
(
ω
∗
⋅
x
+
b
∗
)
f(x)=\rm sign(\omega^*\cdot x + b^*)
f(x)=sign(ω∗⋅x+b∗)
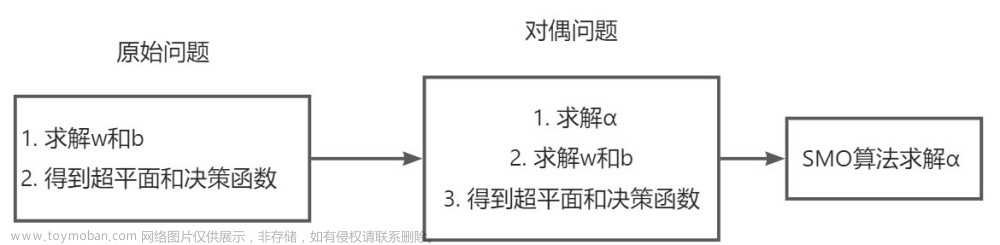
对偶算法
推导对偶优化问题

由 α \alpha α推导 ω \omega ω和 b

对偶算法流程
输入:数据集
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
N
,
y
N
)
}
,
y
i
∈
{
+
1
,
−
1
}
T=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\},y_i\in \{+1,-1\}
T={(x1,y1),(x2,y2),...,(xN,yN)},yi∈{+1,−1}
输出:最大间隔分离超平面与决策函数
- 构造优化问题
min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( x i ⋅ x j ) − ∑ i = 1 N α i s . t . ∑ i = 1 N α i y i = 0 α i ≥ 0 , i = 1 , 2 , . . . , N \begin{aligned} & \min_{\alpha}\quad \frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N \alpha_i \alpha_j y_i y_j (x_i\cdot x_j)-\sum_{i=1}^N \alpha_i\\ &s.t. \quad \sum_{i=1}^N \alpha_i y_i= 0\\ &\quad \quad \alpha_i\ge 0,i=1,2,...,N\\ \end{aligned} αmin21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nαis.t.i=1∑Nαiyi=0αi≥0,i=1,2,...,N
- 求解优化问题,得到最优解
α ∗ = ( α 1 ∗ , α 2 ∗ , . . . , α N ∗ ) T \alpha^* = (\alpha_1^*,\alpha_2^*,...,\alpha_N^*)^T α∗=(α1∗,α2∗,...,αN∗)T
- 根据 α ∗ \alpha^* α∗得到
ω
∗
=
∑
i
=
1
N
α
i
∗
y
i
x
i
\omega^*=\sum_{i=1}^N \alpha_i^* y_i x_i
ω∗=i=1∑Nαi∗yixi
找到符合
α
j
∗
>
0
\alpha_j^*>0
αj∗>0的点
(
x
j
,
y
j
)
(x_j,y_j)
(xj,yj),计算
b
∗
=
y
j
−
∑
i
=
1
N
α
i
∗
y
i
(
x
i
⋅
x
j
)
b^*=y_j-\sum_{i=1}^N \alpha_i^*y_i(x_i\cdot x_j)
b∗=yj−i=1∑Nαi∗yi(xi⋅xj)
- 分离超平面
ω
∗
⋅
x
+
b
∗
=
0
\omega^*\cdot x + b^*=0
ω∗⋅x+b∗=0
决策函数
f
(
x
)
=
s
i
g
n
(
ω
∗
⋅
x
+
b
∗
)
f(x)=\rm sign(\omega^*\cdot x + b^*)
f(x)=sign(ω∗⋅x+b∗)
线性支持向量机(不完全可分)
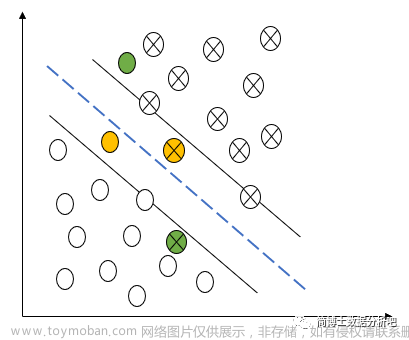
引入松弛因子
在线性支持向量机中,有四类点:
正确分类且在分界线外面的点(白色的点):
y
i
(
ω
⋅
x
i
+
b
)
≥
1
y_i(\omega\cdot x_i+b)\ge 1
yi(ω⋅xi+b)≥1
分类正确但在超平面与分界线之间的点(黄色的点):
y
i
(
ω
⋅
x
i
+
b
)
+
ξ
i
≥
1
,
ξ
i
∈
(
0
,
1
)
y_i(\omega\cdot x_i+b) + \xi_i\ge 1 ,\xi_i\in (0,1)
yi(ω⋅xi+b)+ξi≥1,ξi∈(0,1)
在超平面上的点:
y
i
(
ω
⋅
x
i
+
b
)
+
ξ
i
≥
1
,
ξ
i
=
1
y_i(\omega\cdot x_i+b) + \xi_i\ge 1 ,\xi_i=1
yi(ω⋅xi+b)+ξi≥1,ξi=1
分类错误的点:
y
i
(
ω
⋅
x
i
+
b
)
+
ξ
i
≥
1
,
ξ
i
>
1
y_i(\omega\cdot x_i+b) + \xi_i\ge 1 ,\xi_i>1
yi(ω⋅xi+b)+ξi≥1,ξi>1
解决重点就都集中到了这个关键的参数
ξ
i
\xi_i
ξi 上,我们给它起名叫做弹性因子或松弛变量。
现在我们就要把原来线性可分的目标函数改成考虑所有松弛变量的新函数,目标函数是:
min
1
2
∣
∣
ω
2
∣
∣
+
C
∑
i
=
1
N
ξ
i
\min \frac{1}{2}||\omega^2||+C\sum_{i=1}^N \xi_i
min21∣∣ω2∣∣+Ci=1∑Nξi
这里的
C
C
C 被称作惩罚系数,它决定了原始参数和松弛变量之间的影响权重。
- C C C越大代表了误分类起到的作用更大,也可以说对误分类的惩罚力度大
- C C C越小代表正确分类的参数作用更大,对误分类的惩罚力度小
原始问题算法流程
- 构造优化问题
min
ω
,
b
,
ξ
i
1
2
∣
∣
ω
2
∣
∣
+
C
∑
i
=
1
N
ξ
i
s
.
t
.
1
−
ξ
i
−
y
i
(
ω
⋅
x
i
+
b
)
≤
0
,
i
=
1
,
2
,
.
.
.
,
N
−
ξ
i
≤
0
,
i
=
1
,
2
,
.
.
.
,
N
\begin{aligned} & \min_{\omega ,b,\xi_i}\quad \frac{1}{2}||\omega^2||+C\sum_{i=1}^N \xi_i\\ &s.t. \quad 1-\xi_i -{y_i(\omega\cdot x_i +b)}\le 0,i=1,2,...,N\\ &\qquad -\xi_i\le 0 ,i=1,2,...,N \end{aligned}
ω,b,ξimin21∣∣ω2∣∣+Ci=1∑Nξis.t.1−ξi−yi(ω⋅xi+b)≤0,i=1,2,...,N−ξi≤0,i=1,2,...,N
所得解为
ω
∗
,
b
∗
\omega^* ,b^*
ω∗,b∗
- 分离超平面
ω
∗
⋅
x
+
b
∗
=
0
\omega^*\cdot x + b^*=0
ω∗⋅x+b∗=0
决策函数
f
(
x
)
=
s
i
g
n
(
ω
∗
⋅
x
+
b
∗
)
f(x)=\rm sign(\omega^*\cdot x + b^*)
f(x)=sign(ω∗⋅x+b∗)
对偶算法
推导对偶优化问题

由 α \alpha α推导 ω \omega ω和 b

对偶算法流程
输入:数据集
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
N
,
y
N
)
}
,
y
i
∈
{
+
1
,
−
1
}
T=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\},y_i\in \{+1,-1\}
T={(x1,y1),(x2,y2),...,(xN,yN)},yi∈{+1,−1}
输出:最大间隔分离超平面与决策函数
- 给定惩罚参数 C C C,构造优化问题
min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( x i ⋅ x j ) − ∑ i = 1 N α i s . t . ∑ i = 1 N α i y i = 0 0 ≤ α i ≤ C , i = 1 , 2 , . . . , N \begin{aligned} & \min_{\alpha}\quad \frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N \alpha_i \alpha_j y_i y_j (x_i\cdot x_j)-\sum_{i=1}^N \alpha_i\\ &s.t. \quad \sum_{i=1}^N \alpha_i y_i= 0\\ &\quad \quad 0\le\alpha_i\le C,i=1,2,...,N\\ \end{aligned} αmin21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nαis.t.i=1∑Nαiyi=00≤αi≤C,i=1,2,...,N
- 求解优化问题,得到最优解
α ∗ = ( α 1 ∗ , α 2 ∗ , . . . , α N ∗ ) T \alpha^* = (\alpha_1^*,\alpha_2^*,...,\alpha_N^*)^T α∗=(α1∗,α2∗,...,αN∗)T
- 根据 α ∗ \alpha^* α∗得到
ω
∗
=
∑
i
=
1
N
α
i
∗
y
i
x
i
\omega^*=\sum_{i=1}^N \alpha_i^* y_i x_i
ω∗=i=1∑Nαi∗yixi
找到符合
0
<
α
j
∗
<
C
0<\alpha_j^*<C
0<αj∗<C的点
(
x
j
,
y
j
)
(x_j,y_j)
(xj,yj),计算
b
∗
=
y
j
−
∑
i
=
1
N
α
i
∗
y
i
(
x
i
⋅
x
j
)
b^*=y_j-\sum_{i=1}^N \alpha_i^*y_i(x_i\cdot x_j)
b∗=yj−i=1∑Nαi∗yi(xi⋅xj)
- 分离超平面
ω
∗
⋅
x
+
b
∗
=
0
\omega^*\cdot x + b^*=0
ω∗⋅x+b∗=0
决策函数
f
(
x
)
=
s
i
g
n
(
ω
∗
⋅
x
+
b
∗
)
f(x)=\rm sign(\omega^*\cdot x + b^*)
f(x)=sign(ω∗⋅x+b∗)
从合页损失的角度理解线性支持向量机
合页的表达式


软间隔和合页损失
原始优化问题:
min
ω
,
b
,
ξ
i
1
2
∣
∣
ω
2
∣
∣
+
C
∑
i
=
1
N
ξ
i
\min_{\omega ,b,\xi_i}\quad \frac{1}{2}||\omega^2||+C\sum_{i=1}^N \xi_i
ω,b,ξimin21∣∣ω2∣∣+Ci=1∑Nξi
令
ξ
i
=
[
1
−
y
i
(
ω
⋅
x
i
+
b
)
]
+
=
{
1
−
y
i
(
ω
⋅
x
i
+
b
)
ξ
i
>
0
0
ξ
i
≤
0
\xi_i = [1-y_i(\omega\cdot x_i + b)]_+=\begin{cases} 1-y_i(\omega\cdot x_i + b) & \xi_i > 0\\ 0& \xi_i\le 0 \end{cases}
ξi=[1−yi(ω⋅xi+b)]+={1−yi(ω⋅xi+b)0ξi>0ξi≤0
min
ω
,
b
,
ξ
i
1
2
∣
∣
ω
2
∣
∣
+
C
∑
i
=
1
N
ξ
i
=
min
ω
,
b
1
2
∣
∣
ω
2
∣
∣
+
C
∑
i
=
1
N
[
1
−
y
i
(
ω
⋅
x
i
+
b
)
]
+
=
min
ω
,
b
∑
i
=
1
N
[
1
−
y
i
(
ω
⋅
x
i
+
b
)
]
+
+
1
2
C
∣
∣
ω
2
∣
∣
=
min
ω
,
b
∑
i
=
1
N
[
1
−
y
i
(
ω
⋅
x
i
+
b
)
]
+
+
λ
∣
∣
ω
2
∣
∣
\min_{\omega ,b,\xi_i}\quad \frac{1}{2}||\omega^2||+C\sum_{i=1}^N \xi_i\\ =\min_{\omega,b}\quad \frac{1}{2}||\omega^2||+C\sum_{i=1}^N [1-y_i(\omega\cdot x_i + b)]_+\\ =\min_{\omega,b}\quad \sum_{i=1}^N [1-y_i(\omega\cdot x_i + b)]_+ + \frac{1}{2C}||\omega^2||\\ =\min_{\omega,b}\quad \sum_{i=1}^N [1-y_i(\omega\cdot x_i + b)]_+ + \lambda ||\omega^2||
ω,b,ξimin21∣∣ω2∣∣+Ci=1∑Nξi=ω,bmin21∣∣ω2∣∣+Ci=1∑N[1−yi(ω⋅xi+b)]+=ω,bmini=1∑N[1−yi(ω⋅xi+b)]++2C1∣∣ω2∣∣=ω,bmini=1∑N[1−yi(ω⋅xi+b)]++λ∣∣ω2∣∣
可以理解为最小化合页损失,后面是惩罚项。
三个损失函数的比较

非线性支持向量机
核函数
非线性的也分为可分和不可分两种情况。我们主要看非线性支持向量机(不可分)的情况。
我们需要将非线性转化为线性:原空间的点映射到新空间,用线性支持向量机取解决。
分析线性支持向量机的优化问题,我们可以发现关键计算
(
x
i
⋅
x
j
)
(x_i\cdot x_j)
(xi⋅xj)这个内积,其余都是单个数,所以要求新空间是能够计算内积的。
设映射是
Φ
\Phi
Φ,
z
i
=
Φ
(
x
i
)
,
z
j
=
Φ
(
x
j
)
z_i = \Phi(x_i),z_j = \Phi(x_j)
zi=Φ(xi),zj=Φ(xj)
z
i
⋅
z
j
=
Φ
(
x
i
)
⋅
Φ
(
x
j
)
=
K
(
x
i
,
x
j
)
核函数
z_i\cdot z_j = \Phi (x_i)\cdot \Phi(x_j)=K(x_i,x_j) 核函数
zi⋅zj=Φ(xi)⋅Φ(xj)=K(xi,xj)核函数
有很多映射对应一个核函数,我们不关心具体是什么映射,只关心核函数。
在新空间里
min
α
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
K
(
x
i
,
x
j
)
−
∑
i
=
1
N
α
i
\min_{\alpha}\quad \frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N \alpha_i \alpha_j y_i y_j K(x_i,x_j)-\sum_{i=1}^N \alpha_i
αmin21i=1∑Nj=1∑NαiαjyiyjK(xi,xj)−i=1∑Nαi
如何找到正定核?(
K
(
x
i
,
x
i
)
≥
0
K(x_i,x_i)\ge 0
K(xi,xi)≥0)
满足以下两个条件:
①
K
K
K是对称函数
② 新空间上的Gram矩阵半正定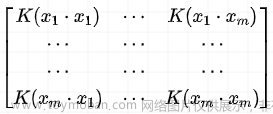
这部分的具体内容需要泛函的知识,难度较大,感兴趣可以看《统计学习方法 李航》
常用核函数(我们所说的核函数就是正定核):
- 线性内核函数 K ( x i , x j ) = x i ⋅ x j K(x_i,x_j)=x_i\cdot x_j K(xi,xj)=xi⋅xj
- 多项式核函数 K ( x i , x j ) = ( x i ⋅ x j + 1 ) q K(x_i,x_j)=(x_i\cdot x_j+1)^q K(xi,xj)=(xi⋅xj+1)q
- 径向基核函数(高斯核函数,RBF) K ( x i , x j ) = exp { − ∣ ∣ x i − x j ∣ ∣ 2 2 σ 2 } K(x_i,x_j)=\exp \{-\frac{||x_i-x_j||^2}{2\sigma^2}\} K(xi,xj)=exp{−2σ2∣∣xi−xj∣∣2}
还有一种字符串核函数:
算法流程
和线性支持向量机不同的地方就是将 x i ⋅ x j x_i\cdot x_j xi⋅xj改为 K ( x i , x j ) K(x_i,x_j) K(xi,xj)。
输入:数据集
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
N
,
y
N
)
}
,
y
i
∈
{
+
1
,
−
1
}
T=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\},y_i\in \{+1,-1\}
T={(x1,y1),(x2,y2),...,(xN,yN)},yi∈{+1,−1}
输出:最大间隔分离超平面与决策函数
- 给定惩罚参数 C C C,构造优化问题
min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j K ( x i , x j ) − ∑ i = 1 N α i s . t . ∑ i = 1 N α i y i = 0 0 ≤ α i ≤ C , i = 1 , 2 , . . . , N \begin{aligned} & \min_{\alpha}\quad \frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N \alpha_i \alpha_j y_i y_j K(x_i, x_j)-\sum_{i=1}^N \alpha_i\\ &s.t. \quad \sum_{i=1}^N \alpha_i y_i= 0\\ &\quad \quad 0\le\alpha_i\le C,i=1,2,...,N\\ \end{aligned} αmin21i=1∑Nj=1∑NαiαjyiyjK(xi,xj)−i=1∑Nαis.t.i=1∑Nαiyi=00≤αi≤C,i=1,2,...,N
- 求解优化问题,得到最优解
α ∗ = ( α 1 ∗ , α 2 ∗ , . . . , α N ∗ ) T \alpha^* = (\alpha_1^*,\alpha_2^*,...,\alpha_N^*)^T α∗=(α1∗,α2∗,...,αN∗)T
- 根据 α ∗ \alpha^* α∗得到
ω
∗
=
∑
i
=
1
N
α
i
∗
y
i
K
(
⋅
,
x
i
)
\omega^*=\sum_{i=1}^N \alpha_i^* y_i K(\cdot,x_i)
ω∗=i=1∑Nαi∗yiK(⋅,xi)
找到符合
0
<
α
j
∗
<
C
0<\alpha_j^*<C
0<αj∗<C的点
(
x
j
,
y
j
)
(x_j,y_j)
(xj,yj),计算
b
∗
=
y
j
−
∑
i
=
1
N
α
i
∗
y
i
K
(
x
i
,
x
j
)
b^*=y_j-\sum_{i=1}^N \alpha_i^*y_iK(x_i,x_j)
b∗=yj−i=1∑Nαi∗yiK(xi,xj)
- 分离超平面
ω
∗
⋅
x
+
b
∗
=
0
\omega^*\cdot x + b^*=0
ω∗⋅x+b∗=0
决策函数
f
(
x
)
=
s
i
g
n
(
ω
∗
⋅
x
+
b
∗
)
f(x)=\rm sign(\omega^*\cdot x + b^*)
f(x)=sign(ω∗⋅x+b∗)
SMO算法
SMO算法用来求解第二步中的优化问题。
坐标下降法(简化优化问题,每次更新一个参数)

SMO算法求α(每次更新两个参数)



更新完两个α后,更新b和Ei

参数的选择
 文章来源:https://www.toymoban.com/news/detail-476313.html
文章来源:https://www.toymoban.com/news/detail-476313.html
SMO算法流程
 文章来源地址https://www.toymoban.com/news/detail-476313.html
文章来源地址https://www.toymoban.com/news/detail-476313.html
到了这里,关于SVM——《统计学习方法第七章》的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!