maraidb和sqlite3部分命令操作区别记录
1.安装sqlite3
在实现我的视频点播系统项目时,我尝试封装了两种数据库的调用逻辑
- mysql(maraidb)
- sqlite3
这里封装sqlite3的原因是,sqlite3主要针对的就是嵌入式数据库,其性能可能不如mysql,但是就好在可以带着走。安装也很方便,内存占用相对于mariadb来说也降低了很多。
教程:安装maraidb
在上面的博客中,安装maraidb需要很多步骤,还需要修改配置文件中的默认字符集为UTF8。
而安装sqlite3就要多方便有方便了,而且sqlite3默认采用的就是uft8字符集,完全不需要修改!
sudo yum install sqlite-devel
就这一行命令就搞定了!
sqlite3 --version #查看当前安装的版本
安装完成后,可以看看sqlite3的版本(如果没有安装,执行这个命令会告知 command not found)
[root@1c2261732150:~]# sqlite3 --version
3.26.0 2018-12-01 12:34:55 bf8c1b2b7a5960c282e543b9c293686dccff272512d08865f4600fb58238alt1
2.基本操作的区别
如下列出一些基本操作在mariadb命令行中,和在sqlite3命令行中的区别
为了方便,注释中m指代mysql,s指代sqlite3
show databases; -- 查看所有数据库 mariadb
.database -- 查看当前数据库 sqlite3
use db_name; -- 进入数据库 m
.open db_name.db; -- 提供.db文件的路径,进入数据库 s
show tables; -- 查看数据库中所有表 m
.tables -- 查看数据库中所有表 s
quit -- 退出数据库命令行 m
.quit -- 退出数据库命令行 s
这便是基础操作的一些区别,更深入的操作我暂时还没有学到。
其中进入数据库的操作就能看出来sqlite的特性,只要有这个.db文件,你就可以很轻松的在另外一个主机上恢复之前的数据(或者进行备份),这也是带着走的体现。
3.创建表
mysql和sqlite3所支持的数据类型也有区别
| sqlite3数据类型 | 描述 |
|---|---|
| NULL | 值是一个 NULL 值。 |
| INTEGER | 值是一个带符号的整数,根据值的大小存储在 1、2、3、4、6 或 8 字节中。 |
| REAL | 值是一个浮点值,存储为 8 字节的 IEEE 浮点数字。 |
| TEXT | 值是一个文本字符串,使用数据库编码(UTF-8、UTF-16BE 或 UTF-16LE)存储。 |
| BLOB | 值是一个 blob 数据,完全根据它的输入存储。 |
在sqlite3中,没有varchar类型。但我们依旧可以使用TEST(8)来限制字符串类型的长度
以我的视频点播项目所用数据库为例,以下是mariadb创建数据表的sql语句
create table tb_video(
id VARCHAR(8) NOT NULL DEFAULT (substring(UUID(), 1, 8)) comment '视频id',
name VARCHAR(50) comment '视频标题',
info text comment '视频简介',
video VARCHAR(255) comment '视频链接',
cover VARCHAR(255) comment '视频封面链接',
insert_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP comment '视频创建时间'
);
在这里我采用了mariadb自带的uuid函数来生成uuid字符串,并使用substring函数截取了uuid前8位的内容,作为视频的唯一id
而如果想让mariadb来保证id字段唯一,可以使用如下命令进行约束
create table tb_video(
id VARCHAR(8) NOT NULL DEFAULT (substring(UUID(), 1, 8)) comment '视频id',
name VARCHAR(50) comment '视频标题',
info text comment '视频简介',
video VARCHAR(255) comment '视频链接',
cover VARCHAR(255) comment '视频封面链接',
insert_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP comment '视频创建时间',
UNIQUE (id)
);
以下是sqlite3的操作,sqlite3中并不支持comment对字段进行注释。
这里要想让id字段唯一,直接在字段类型后面跟着UNIQUE就可以了
-- sqlite3中不支持uuid函数,所以需要用randomblob函数生成一个随机数,再用hex转成16进制作为视频的id
-- sqlite3默认的时间是utc,所以需要用datetime函数将其转化为东八区的时间
CREATE TABLE IF NOT EXISTS tb_video(
id TEXT(8) UNIQUE NOT NULL DEFAULT (lower((hex(randomblob(4))))),
name TEXT NOT NULL,
info TEXT,
video TEXT NOT NULL,
cover TEXT NOT NULL,
insert_time TIMESTAMP DEFAULT (datetime('now', '+8 hours'))
);
4.插入删除数据
在我项目所用字段中,二者插入/删除数据的操作完全相同,这里就不记录了
-- 删除表
drop table tb_video;
-- 插入数据
insert into tb_video (name, info, video, cover) values ('名字1','说明信息1','test1','testc1');
-- 查看所有字段
select * from tb_video;
select * from tb_video where id='45f78a68';
-- 删除数据
delete from tb_video where id = 'D81382A8';
5.使用cpp操作的时候
- mysql必须要进行init,此时就需要指定目标数据库了
- 而sqlite3并不需要进行数据库的连接操作,我们就可以实现在cpp中进行数据库的创建、数据表的创建等操作。
c语言操作sqlite3的方法,可以查看菜鸟教程。上面的用例很详细(虽然没有写注释,但还是能看懂的)我就不写博客了~
5.1 查询时的回调
这里只对select命令操作进行说明,在sqlite3中,所有命令都是用下面这个函数来执行的
SQLITE_API int sqlite3_exec(
sqlite3*, /* An open database */
const char *sql, /* SQL to be evaluated */
int (*callback)(void*,int,char**,char**), /* Callback function */
void *, /* 1st argument to callback */
char **errmsg /* Error msg written here */
);
如果你执行的是插入、更新等等sql语句,sqlite_callback函数不会被调用(我测试过了)。目前我只发现select语句会调用这个callback函数。
比如我的数据库tb_video中有如下两行数据
df65c8c5|名字1|说明信息1|test1|testc1|2023-05-04 16:57:10
80cd3f51|名字1|说明信息1|test1|testc1|2023-05-04 19:02:05
#include <stdio.h>
#include <stdlib.h>
#include <sqlite3.h>
// 每当有结果返回的时候,用这个函数来处理结果
// 第一个参数可以从sqlite3_exec中主动传入
// argc 是结果的行数(二维数组行数)
// argv 是存放数据的二维数组
// azColName 是存放字段名称的二维数组
static int callback(void *NotUsed, int argc, char **argv, char **azColName)
{
int i;
for (i = 0; i < argc; i++)
{
printf("%s = %s\n", azColName[i], argv[i] ? argv[i] : "NULL");
}
printf("\n");
return 0;
}
// sqlite3数据库打开测试
void SqliteTest()
{
sqlite3 *db;// 数据库指针
char *zErrMsg = 0;
std::string sql;
int ret;
// 打开数据库文件
if (sqlite3_open("test.db", &db))
{
fprintf(stderr, "Can't open database: %s\n", sqlite3_errmsg(db));
exit(0);
}
else
{
fprintf(stderr, "Opened database successfully\n");
}
sql = "select * from tb_video;";
// 执行sql语句
ret = sqlite3_exec(db, sql.c_str(), callback, 0, &zErrMsg);
if (ret != SQLITE_OK)
{
fprintf(stderr, "SQL error: %s\n", zErrMsg);
sqlite3_free(zErrMsg);
}
else
{
fprintf(stdout, "SQL successfully\n");
}
sqlite3_close(db);
}
用这个函数来查询,会打印如下的结果。从这个结果中,就能推测出callback函数4个参数分别的作用,已经在代码的注释中说明了。
Opened database successfully
id = df65c8c5
name = 名字1
info = 说明信息1
video = test1
cover = testc1
insert_time = 2023-05-04 16:57:10
id = 80cd3f51
name = 名字1
info = 说明信息1
video = test1
cover = testc1
insert_time = 2023-05-04 19:02:05
其中,第四个参数是给callback函数传入的第一个入参。
5.2 通过回调插入数据到Json字符串
我的视频点播项目在查询的时候,需要将结果保存为json字符串,如果使用mysql的c++操作,就可以直接在遍历结果的二维数组时,将结果放入到Json::Value中
// 查询所有-输出所有视频信息(视频列表)
bool SelectAll(Json::Value *video_s)
{
#define SELET_ALL "select * from %s;"
std::string sql;
sql.resize(512);
sprintf((char*)sql.c_str(),SELET_ALL,_video_table.c_str());
// 这里加锁是为了保证结果集能被正常报错(并不是防止修改原子性问题,mysql本身就已经维护了原子性)
// 下方执行语句后,如果不保存结果集 而又执行一次搜索语句,之前搜索的结果就会丢失
// 加锁是为了保证同一时间只有一个执行流在进行查询操作,避免结果集丢失
_mutex.lock();
// 语句执行失败了
if (!MysqlQuery(_mysql, sql)) {
_mutex.unlock();
_log.error("Video SelectAll","query failed");
return false;
}
// 保存结果集到本地
MYSQL_RES *res = mysql_store_result(_mysql);
if (res == nullptr) {
_mutex.unlock();
_log.error("Video SelectAll","mysql store result failed");
return false;
}
// 遍历结果集,存到json中
int num_rows = mysql_num_rows(res);//获取结果集的行数
for (int i = 0; i < num_rows; i++) {
MYSQL_ROW row = mysql_fetch_row(res);//获取每一行的列数
Json::Value video;
video["id"] = row[0];
video["name"] = row[1];
video["info"] = row[2];
video["video"] = row[3];
video["cover"] = row[4];
video["insert_time"] = row[5]; //mysql中存放的就是可读时间 (其实存时间戳更好)
//json list
video_s->append(video);
}
mysql_free_result(res);//释放结果集
_mutex.unlock();
_log.info("Video SelectAll","select all finished");
return true;
}
而在sqlite3中,就需要使用callback函数的第一个参数来进行json字符串的保存;这里因为sqlite3会给我们返回字段名字,我们就可以直接用字段明作为json的字段名,将参数作为json字段的对应参数。更省事了!
static int callback(void *json_videos, int argc, char **argv, char **azColName)
{
Json::Value* video_s = (Json::Value*)json_videos;//转为原本的类型
Json::Value video;//单个视频
for (int i = 0; i < argc; i++)
{
video[azColName[i]] = argv[i] ? argv[i] : "NULL";//存入数据
printf("%s = %s\n", azColName[i], argv[i] ? argv[i] : "NULL");
}
printf("\n");
video_s->append(video);//插入到json数组中
return 0;
}
在主函数中,创建一个Json::Value对象,将其强转为void*的指针,传给callback函数
// 查询
Json::Value videos;
sql = "select * from tb_video;";
// 执行sql语句
ret = sqlite3_exec(db, sql.c_str(), callback, (void*)&videos, &zErrMsg);
if (ret != SQLITE_OK)
{
fprintf(stderr, "SQL error: %s\n", zErrMsg);
sqlite3_free(zErrMsg);
}
else
{
fprintf(stdout, "Table created successfully\n");
}
sqlite3_close(db);
std::string json_str;
vod::JsonUtil::Serialize(videos,&json_str);
std::cout << json_str << std::endl;
编译执行,最终打印的json字符串如下(完整代码见 Github)
[
{
"cover" : "testc1",
"id" : "df65c8c5",
"info" : "\u8bf4\u660e\u4fe1\u606f1",
"insert_time" : "2023-05-04 16:57:10",
"name" : "\u540d\u5b571",
"video" : "test1"
},
{
"cover" : "testc1",
"id" : "80cd3f51",
"info" : "\u8bf4\u660e\u4fe1\u606f1",
"insert_time" : "2023-05-04 19:02:05",
"name" : "\u540d\u5b571",
"video" : "test1"
}
]
5.3 对表的查询
除了使用sqlite3_exec针对数据库进行操作,还可以用下面这个函数,对指定的表进行查询
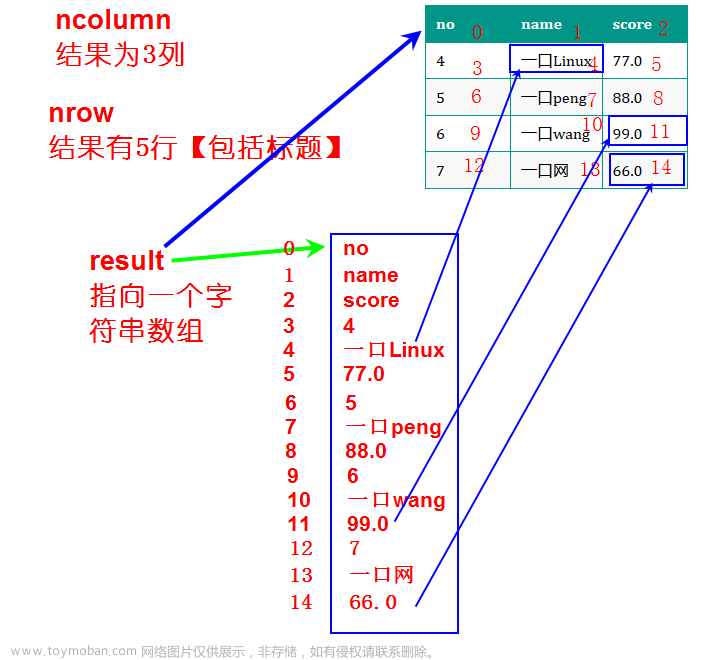
int sqlite3_get_table(
sqlite3* db, /* 数据库连接 */
const char *zSql, /* 查询语句 */
char ***pazResult, /* 查询结果 */
int *pnRow, /* 查询结果的行数 */
int *pnColumn, /* 查询结果的列数 */
char **pzErrmsg /* 错误信息 */
);
参数说明如下,这里就比较类似mysql的查询函数了,其会给我们返回结果集,以及结果的行数、列数,让我们自己遍历进行操作。
-
db: 数据库连接对象,是已经打开的数据库连接。 -
zSql: 执行的 SQL 查询语句。 -
pazResult: 一个 char 类型的指针数组(二维,每一行是一个指针,指向一个字符串),用于存储查询结果。每个元素都指向一个表示每行数据的字符串数组。最后一个元素为 NULL。 -
pnRow: 用于存储查询结果的行数。 -
pnColumn: 用于存储查询结果的列数。 -
pzErrmsg: 用于存储错误信息。
sqlite3_get_table 函数执行查询语句时,结果集中的每个单元格都被解释为一个字符串。查询结果将被存储在指针数组 pazResult 中,每行数据占用一个字符串数组(除了最后一个元素为 NULL)。表格的第一行包含列名,后面的每行则为查询结果中的一条记录。
sqlite3_get_table 函数的作用是执行一条 SQL 查询语句,并将其结果存储在一个表格中,以便后续处理和分析。
调用完毕这个函数,处理完结果集后,需要调用如下函数释放结果集。
char **pazResult; /* 二维指针数组,存储查询结果 */
int nRow = 0, nColumn = 0;/* 获得查询结果的行数和列数 */
sqlite3_get_table(db, "SELECT * FROM tb_video;", &pazResult, &nRow, &nColumn, NULL);
// 遍历处理结果集
// ....
sqlite3_free_table(pazResult);// 处理完毕结果集后释放
5.3.1 错误示例
如下是一个示例的错误代码!
char **pazResult; /* 二维指针数组,存储查询结果 */
/* 获得查询结果的行数和列数 */
int nRow = 0, nColumn = 0,index=0;
sqlite3_get_table(db, "SELECT * FROM tb_video;", &pazResult, &nRow, &nColumn, NULL);
std::cout << nRow << " " << nColumn << std::endl;
for (int i = 0; i < nRow; i++)
{
for (int j = 0; j < nColumn; j++)
{
printf("%-8s : %-8s\n", pazResult[j],pazResult[i][j]);
}
}
sqlite3_free_table(pazResult);
编译不会出错,但是执行的时候,直接会出现段错误
Opened database successfully
2 6
Segmentation fault
这是因为我们的pazResult只是一个二级指针,我们并没有给他初始化为多少行多少列的模式,导致最终++的时候,会出现访问错位的情况。
如果改成下面这样的打印
cout << pazResult[j] << endl;
cout << "--" << endl;
cout << pazResult[i][j] << endl;
cout << "---" << endl;
打印的结果就是这样的,合计是在遍历每一个字符串!
id
--
i
---
name
--
d
---
info
--
---
video
--
---
cover
--
---
insert_time
--
后面重复的就省略掉了
为什么不行呢?这是因为pazResult实际上的结构是这样的
id
name
info
video
cover
insert_time
df65c8c5
名字1
说明信息1
test1
testc1
2023-05-04 16:57:10
使用pazResult[i][j]进行访问:
- 当i是0的时候,访问的是
id字符串 - 此时
j就变成id字符串里面的下标了 - 而
nColumn远大于id字符串的长度(id只有两个字符,而在我这里nColumn=6) - 所以就出现了段错误
Segmentation fault!
我还是学艺不精呀!🤣
5.3.2 正确操作
正确的办法应该是这样的
Json::Value videos;
char **pazResult; /* 二维指针数组,存储查询结果 */
/* 获得查询结果的行数和列数 */
int nRow = 0, nColumn = 0,index=0;
sqlite3_get_table(db, "SELECT * FROM tb_video;", &pazResult, &nRow, &nColumn, NULL);
std::cout << nRow <<" " << nColumn << std::endl;
index = nColumn;//从第二列开始,跳过第一行(第一行都是字段名)
for (int i = 0; i < nRow; i++)
{
for (int j = 0; j < nColumn; j++)
{
// 前nColumn个数据都是字段名,所以可以用 pazResult[j] 来打印
printf("%-8s : %-8s\n", pazResult[j],pazResult[index]);
index++;
}
}
sqlite3_free_table(pazResult);
成功打印出了数据库中两行的数据
Opened database successfully
2 6
id : df65c8c5
name : 名字1
info : 说明信息1
video : test1
cover : testc1
insert_time : 2023-05-04 16:57:10
id : da6d27be
name : 名字2
info : 说明信息2
video : test2
cover : testc2
insert_time : 2023-05-04 19:59:38
和从数据库命令行中读取到的结果相同
sqlite> select * from tb_video;
df65c8c5|名字1|说明信息1|test1|testc1|2023-05-04 16:57:10
da6d27be|名字2|说明信息2|test2|testc2|2023-05-04 19:59:38
最终的完整代码如下
void SqliteTest()
{
sqlite3 *db; // 数据库指针
char *zErrMsg = 0;
std::string sql;
int ret;
// 打开数据库文件
if (sqlite3_open("test.db", &db))
{
fprintf(stderr, "Can't open database: %s\n", sqlite3_errmsg(db));
exit(0);
}
else
{
fprintf(stderr, "Opened database successfully\n");
}
// 查询
Json::Value videos;
char **pazResult; /* 二维指针数组,存储查询结果 */
/* 获得查询结果的行数和列数 */
int nRow = 0, nColumn = 0;
sqlite3_get_table(db, "SELECT * FROM tb_video;", &pazResult, &nRow, &nColumn, NULL);
std::cout << nRow <<" " << nColumn << std::endl;
int index = nColumn;//从第二列开始,跳过第一行(第一行都是字段名)
for (int i = 0; i < nRow; i++)
{
Json::Value video;
for (int j = 0; j < nColumn; j++)
{
// 前nColumn个数据都是字段名,所以可以用 pazResult[j] 来打印
// printf("%-8s : %-8s\n", pazResult[j],pazResult[index]);
video[pazResult[j]] = pazResult[index] ?pazResult[index] : "NULL"; // 存入数据
index++;
}
// json list
videos.append(video);
}
std::string json_str;
vod::JsonUtil::Serialize(videos, &json_str);
std::cout << json_str << std::endl;
sqlite3_free_table(pazResult);
sqlite3_close(db);
}
完整输出如下,json字符串内的数据是正确的!
Opened database successfully
2 6
[
{
"cover" : "testc1",
"id" : "df65c8c5",
"info" : "\u8bf4\u660e\u4fe1\u606f1",
"insert_time" : "2023-05-04 16:57:10",
"name" : "\u540d\u5b571",
"video" : "test1"
},
{
"cover" : "testc2",
"id" : "da6d27be",
"info" : "\u8bf4\u660e\u4fe1\u606f2",
"insert_time" : "2023-05-04 19:59:38",
"name" : "\u540d\u5b572",
"video" : "test2"
}
]
sqlite3在返回数据的时候也会给我们返回表中的字段名。我们可以将json字段的key设置成字段名,这样就实现了字段的统一
个人认为,为了避免出现同一value而key不同的情况,最好是将应用层和数据库中的字段统一。否则出现二义性问题不好排查。特别是当一个表中的字段较多的时候。
结语
需要注意的是,二者只是适用范围的区别,并没有孰强孰弱的差距。
以下是gpt3.5对二者区别的总结:
SQLite3 和 MySQL 都是流行的关系型数据库管理系统,但它们有不同的用途和设计重点。文章来源:https://www.toymoban.com/news/detail-490637.html
- SQLite3 的主要目标是作为嵌入式数据库使用,包括在移动设备和桌面应用程序中,也可以作为轻量级数据库使用。相比之下,MySQL 的主要重点是支持大型企业级应用程序和高负载服务器。
- SQLite3 是一个服务器不需要客户端的完全独立的自包含数据库,MySQL 是一个客户端/服务器模型的数据库,需要一个专用的服务器端。
- SQLite3 支持 SQL-92 标准的基本功能,而 MySQL 支持更广泛的 SQL 标准以及许多扩展功能。
- SQLite3 的数据存储在单个文件中,而 MySQL 的数据通常存储在多个文件或分布式系统中。
就记录这么多吧!文章来源地址https://www.toymoban.com/news/detail-490637.html
到了这里,关于【Sqlite3】maraidb和sqlite3部分命令操作区别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!