欢迎关注『CVHub』官方微信公众号!

Title: Efficient and Effective Text Encoding for Chinese Llama and Alpaca
PDF: https://arxiv.org/pdf/2304.08177v1.pdf
Code: https://github.com/ymcui/Chinese-LLaMA-Alpaca
导读
大型语言模型LLM,如ChatGPT和GPT-4,已经彻底改变了自然语言处理研究。然而,LLMs的昂贵训练和部署对于透明和开放的学术研究提出了挑战。为了解决这些问题,该项目开源了中文LLaMA和Alpaca大语言模型,并强调指令微调。通过增加20K个中文token扩展了原始LLaMA的中文词汇表,增加了编码效率并提高了基本语义理解。通过将中文数据进行辅助预训练并使用中文指令数据进行微调,可大大改善模型对指令的理解和执行能力。
引言
随着大型语言模型LLMs的出现,自然语言处理NLP领域已然经历了一次革命性的范式转变。这些模型以其庞大的规模和广泛的训练数据为特征,已经展示出了理解和生成类似于人类文本的强大能力。与用于文本理解的预训练语言模型BERT不同,GPT系列注重文本生成能力。作为GPT家族中最新的LLMs,ChatGPT和GPT-4引起广泛关注,并成为这个快速发展领域最具代表性的强大模型。
ChatGPT(OpenAI,2022)是基于GPT-3.5架构构建的高级对话人工智能模型,可以进行上下文感知的类人交互。它的成功为GPT-4(OpenAI,2023)的开发铺平了道路,GPT-4是一种更复杂的LLM,已经展示出更大的自然语言理解、生成和各种NLP任务的潜力。这两个模型开辟了新的研究和应用方向,引起了人们对探索人工通用智能AGI能力的兴趣。这些LLMs不仅在多个基准测试中表现出令人印象深刻的性能,而且还展示了少量数据学习和适应新任务的能力。
尽管LLMs异常强大,但这些模型也存在某些限制:
- 私有化,这限制了外界对这些模型源码的访问,并阻碍了更广泛的研究社区基于它们的成功进行研究的能力。
- 训练和部署这些大语言模型所需的巨大计算资源对于资源有限的研究人员来说也是一个挑战
为了应对这些限制,自然语言处理研究社区已经转向开源平替方案。其中最著名的是:LLaMA和Alpaca,其中Alpaca模型在LLaMA的基础上进一步用指令数据进行了微调。这些开源LLMs的设计旨在促进学术研究并加快自然语言处理领域的进展。通过开源这些模型,自然语言处理社区旨在创建一个鼓励模型开发、微调和评估进一步发展的环境,最终构建一些强大的LLMs,以应用于各类应用中。
现有的大语言模型存在私有化和资源受限的问题,因此学术界转向了开源平替方案:LLaMA和Alpaca等,以促进更大的透明度和协作。然而,这些开源模型在处理中文任务时仍然存在困难,因为它们的词汇表中只包含了几百个中文单词,导致编码和解码中文文本的效率受到很大影响。为此,该项目提出了一种改进的中文LLaMA和Alpaca模型,通过添加20k个中文单词来扩展词汇表,从而提高了这些模型处理和生成中文文本的能力。同时采用低秩适应LoRA方法来确保模型的高效训练和部署,从而为其他语言的模型适应提供了参考。这项工作为将LLaMA和Alpaca模型推广到其它语言提供了一个基础,也提供了一些方法扩展这些模型的词汇表和提高性能。
这份技术报告的贡献如下:
- 通过向原始
LLaMA的词汇表中添加20k个中文词汇,增强了中文编码和解码效率并改善了LLaMA的中文理解能力。 - 采用Low-Rank Adaptation
LoRA方法,实现了中文LLaMA和Alpaca模型的高效训练和部署,使研究人员能够在不产生过多计算成本的情况下使用这些模型。 - 评估了中文
Alpaca7B和13B模型在各种自然语言理解NLU和自然语言生成NLG任务中的表现,在中文语言任务中相比原始LLaMA模型取得了显著的提高。 - 公开了相关研究的资源和结果,促进了
NLP社区内进一步的研究和协作,并鼓励将LLaMA和Alpaca模型适应到其他语言中。
Chinese LLAMA
LLaMA是一个基于transformer架构的仅解码器的基础性大语言模型。与其它基于transformer的大语言模型类似,LLaMA包括一个嵌入层、多个transformer块和一个语言模型head层。它还包含了各种改进:如预归一化、SwiGLU激活和Rotary Embeddings等等。LLaMA的参数总数在7B到65B之间。实验数据表明:LLaMA在保持更小模型尺寸的同时,与其它大语言模型(如GPT-3)相比具有相当的竞争性。
LLaMA已经在公开可用的语料库中预训练了1T到1.4T个token,其中大多数数据为英语,因此LLaMA理解和生成中文的能力受到限制。为了解决这个问题,该项目建议在中文语料库上对LLaMA模型进行预训练,以增强其基本的中文理解和生成能力。
然而,在中文语料库上对LLaMA进行预训练也存在相应的挑战:
- 原始
LLaMAtokenizer词汇表中只有不到一千个中文字符,虽然LLaMAtokenizer可以通过回退到字节来支持所有的中文字符,但这种回退策略会显著增加序列长度,并降低处理中文文本的效率。 - 字节标记不仅用于表示中文字符,还用于表示其它
UTF-8标记,这使得字节标记难以学习中文字符的语义含义。
为了解决这些问题,研究人员提出了以下两个解决方案来扩展LLaMA tokenizer中的中文词汇:
- 在中文语料库上使用
SentencePiece训练一个中文tokenizer,使用20000个词汇大小。然后将中文tokenizer与原始LLaMAtokenizer合并,通过组合它们的词汇表,最终获得一个合并的tokenizer,称为Chinese LLaMA tokenizer,词汇表大小为49,953 - 为了适应新的tokenizer,研究人员将词嵌入和语言模型头从V × H调整为V’× H的形状,其中V = 32,000代表原始词汇表的大小,而V’ = 49,953则是Chinese LLaMA tokenizer的词汇表大小。新行附加到原始嵌入矩阵的末尾,确保原始词汇表中的标记的嵌入不受影响。
该技术报告指出,使用中文LLaMA分词器相对于原始LLaMA分词器生成的token数减少了一半左右。 对比了原始LLaMA分词器和中文LLaMA分词器,使用中文LLaMA分词器相对于原始的编码长度有明显的减少。这表明该项目提出的方法在提高LLaMA模型的中文理解和生成能力方面是有效的。通过在标准的自然语言模型训练任务中,使用中文LLaMA分词器对中文LLaMA模型进行预训练,以自回归的方式预测下一个标记,从而进一步提高了LLaMA模型的中文理解和生成能力。
对于给定的输入token序列 x = ( x 0 , x 1 , x 2 , . . . ) x =(x_0,x_1,x_2,...) x=(x0,x1,x2,...),模型以自回归的方式训练以预测下一个token,目标是最小化以下负对数似然:
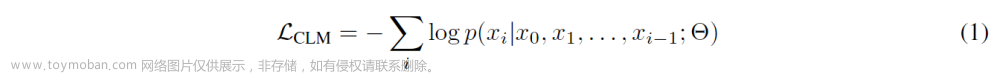
这里,符号Θ表示模型参数, x i x_i xi表示待预测的token,而 x 0 x_0 x0, x 1 x_1 x1, . . . , x i − 1 x_{i-1} xi−1则表示上下文。在这个任务中,模型会自动地根据已经看到的上下文信息来预测下一个token的概率分布,并通过最小化负对数似然函数来学习模型参数。
Chinese Alpaca
在获得预训练的中文LLaMA模型之后,我们采用Alpaca中使用的方法来应用指令微调的方式来继续训练该模型。每个训练sample由一个指令和一个输出组成,sample构成模板如下展示:

实验设置
Pre-training阶段
首先使用了类似于中文BERT-wwm、MacBERT、LERT 等预训练模型使用的大规模中文语料库,总共约有20GB。预训练分为两个阶段:
- 固定模型中的
transformer编码器参数,只训练词嵌入embeddings,适应新添加的中文词向量,同时最小化对原模型的干扰 - 添加
LoRA权重adapters到注意力机制中,训练词嵌入、语言模型头以及新添加的LoRA参数
Instruction Fine-tuning阶段
使用了self-instruction方法从ChatGPT(gpt-3.5-turbo API)中自动获取训练数据,另外这段描述中提供了超参数(hyperparameters)的列表,并在Table 3中提供了微调数据的详细信息。作者在GitHub上公开了模板和代码细节。
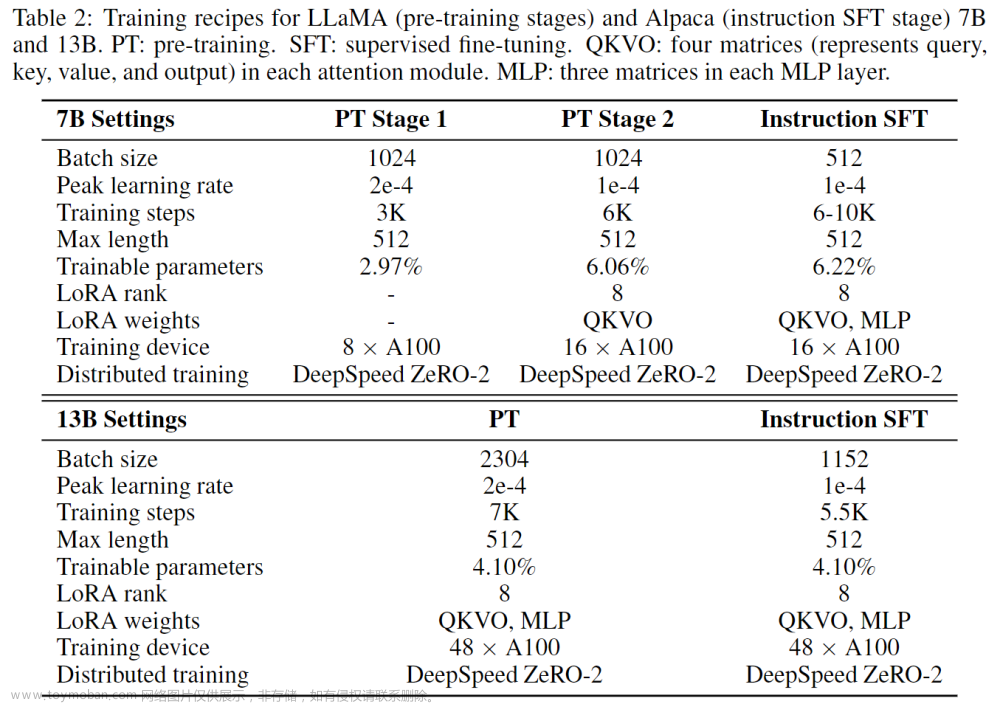
下表2展示了训练7B与13B模型的相关超参数列表
实验评估方法
本项目采用GPT-4作为评分工具。然而,GPT-4并不总是提供准确的分数,所以作者对其评分进行人工检查并在必要时进行调整,手动检查确保分数一致并反映所评估的模型的真实性能。作者使用以下评估模板输入到GPT-4进行评分:

采用了GPT-4作为评分方法,并结合人工检查可建立了一个可靠的评估框架,以有效地衡量中文Alpaca模型在各种自然语言理解和生成任务上的表现。评估集包括 160 个样本,涵盖了10个不同的任务,包括问答、推理、文学、娱乐、翻译、多轮对话、编码和伦理等等。每个任务的总分是该任务内所有样本的分数之和,并将总分标准化为100分。
实验结果

上述结果表明,中文Alpaca-13B模型在各项任务中均表现优于7B模型,凸显了模型容量增加的好处。在回答问题任务中,中文Alpaca-13B模型得分77,而7B模型得分53。在开放式问答方面,13B模型得分73,7B模型得分64。在数值推理任务中,13B模型的得分为50,而7B模型的得分仅为23。
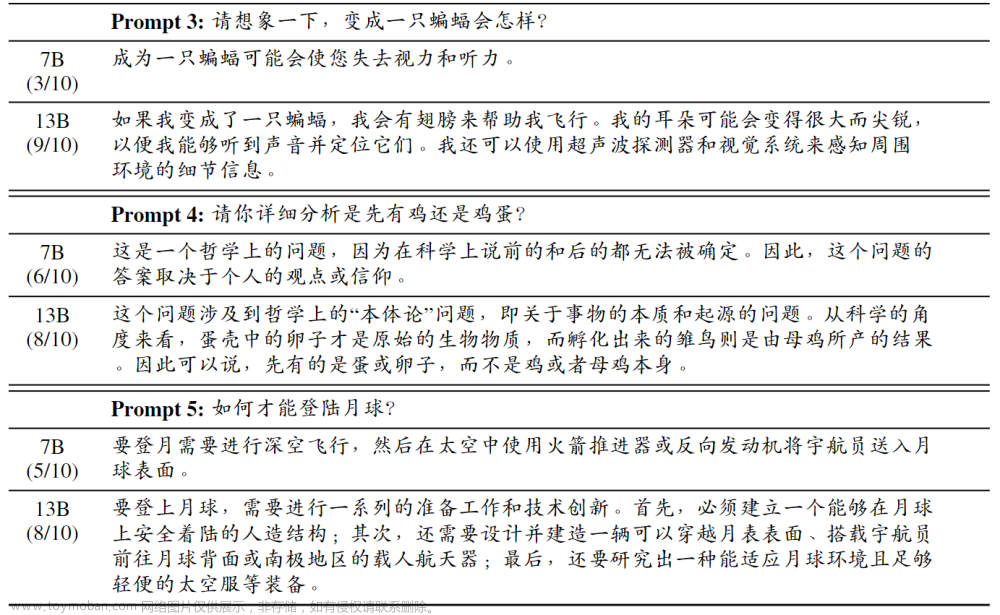
下方例子展示了7B与13B中文LLama模型在同一个prompt下的对比结果:


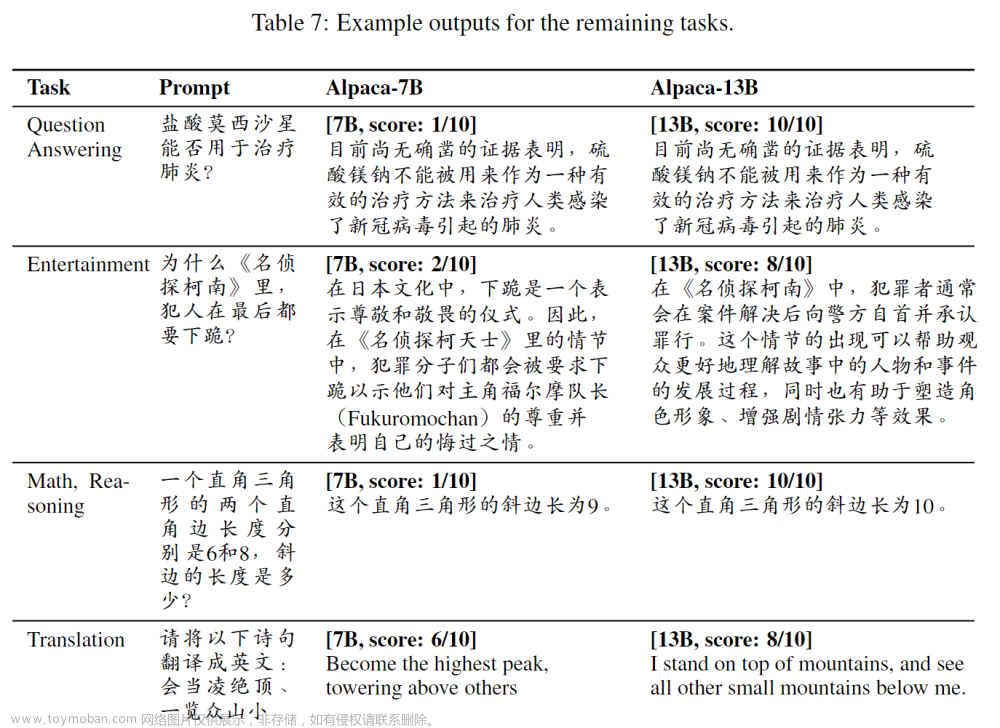
结论
本文开源了专门针对中文的LLaMA和Alpaca大语言模型,通过增加20K个中文token扩展了原始LLaMA的中文词汇表,使用中文LLaMA分词器相对于原始LLaMA分词器生成的token数减少了一半左右,进一步增加了中文编码效率并提高了中文基础语义理解能力。有中文LLaMA大语言模型训练需求的同学可以借鉴一下。文章来源:https://www.toymoban.com/news/detail-491070.html
如果您也对人工智能和计算机视觉全栈领域感兴趣,强烈推荐您关注有料、有趣、有爱的公众号『CVHub』,每日为大家带来精品原创、多领域、有深度的前沿科技论文解读及工业成熟解决方案!欢迎添加小编微信号: cv_huber,备注"CSDN",加入 CVHub 官方学术&技术交流群,一起探讨更多有趣的话题!文章来源地址https://www.toymoban.com/news/detail-491070.html
到了这里,关于中文LLaMa和Alpaca大语言模型开源方案 | 扩充中文词表 & 针对中文语料进行高效编码的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!