一、数据获取
使用PyCharm(引用requests库、lxml库、json库、time库、openpyxl库和pymysql库)爬取京东网页相关数据(品牌、标题、价格、店铺等)
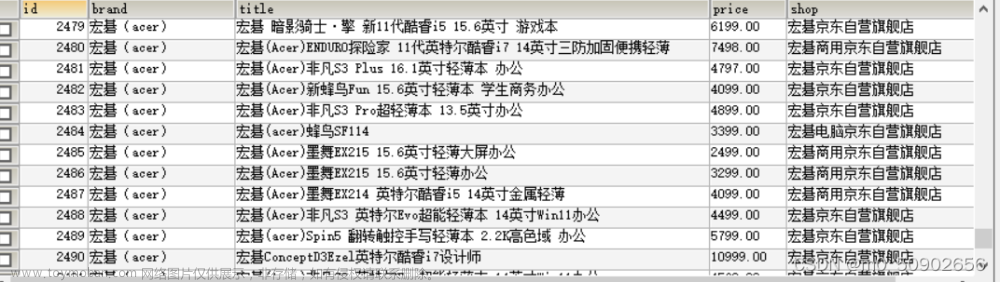
数据展示(片段):
 文章来源:https://www.toymoban.com/news/detail-491655.html
文章来源:https://www.toymoban.com/news/detail-491655.html
京东网页有反爬措施,需要自己在网页登录后,获取cookie,加到请求的header中(必要时引入time库,设置爬取睡眠时间降低封号概率)文章来源地址https://www.toymoban.com/news/detail-491655.html
爬取代码(片段):
###获取每一页的商品数据
def getlist(url,brand):
global count #定义一个全局变量,主要是为了确定写入第几行
# url="https://search.jd.com/search?keyword=笔记本&wq=笔记本&ev=exbrand_联想%5E&page=9&s=241&click=1"
res = requests.get(url,headers=headers)
res.encoding = 'utf-8'
# text = (res.text).replace("")
text = res.text
selector = etree.HTML(text)
list = selector.xpath('//*[@id="J_goodsList"]/ul/li')#获取数据所在
for i in list:
title = i.xpath('.//div[@class="p-name p-name-type-2"]/a/em/text()')[0].strip()#商品名称
price = i.xpath('.//div[@class="p-price"]/strong/i/text()')[0]#商品价格
shop = i.xpath('.//div[@class="p-shop"]/span/a/text()')[0] #获取店铺名称
#获取评论数的id值
# product_id = i.xpath('.//[@class="p-commit"]/strong/a/@id')[0].replace("J_comment_","")
# comment_count = commentcount(product_id)
# print("目前条数="+str(count))到了这里,关于爬虫案例—京东数据爬取、数据处理及数据可视化(效果+代码)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!