前言
HBase是一个分布式、可扩展的、非关系型的NoSQL数据库。它是建立在Hadoop HDFS上的一个开源的数据库管理系统。HBase的设计目标是提供高可靠性、高可扩展性、高性能、高延迟、高容错性和高可用性。
HBase是一种面向列的数据库,可以处理海量的结构化和半结构化数据。它可以存储大量的数据,并能够快速索引和检索数据,适用于需要高速在线访问大量数据的应用程序。
在HBase中,数据按照表格的形式进行存储,类似于关系型数据库中的表。每个表格都具有一个行键和多个列族。行键是一个唯一标识符,用于在表格中定位一行数据。列族是相关列的集合,每个列族都由一个标识符和多个列组成。
HBase具有众多的特性,包括高可用性、自动分片、支持多版本数据、支持复杂的数据类型、支持MapReduce计算等。它还具有良好的扩展性,可以根据需要添加新的节点来扩展集群的规模,以满足更高的数据处理需求。
总的来说,HBase是一个高性能、高可扩展性的NoSQL数据库,适用于需要处理大量结构化和半结构化数据的分布式应用程序。它可以通过灵活的数据模型和支持复杂数据类型的功能,帮助开发人员快速构建可扩展的应用程序。
一、shell创建
Hbase命令:
进入shell:
hbase shell

使用help "COMMAND"命令获取特定命令的帮助信息,例如help "get"将显示关于get命令的帮助信息(注意需要使用引号)。
命令分组:命令被分组管理。使用help "COMMAND_GROUP"命令获取特定命令组的帮助信息,例如help "general"将显示关于general命令组的帮助信息。
常见的命令组包括:general、ddl、namespace、dml、tools、replication、snapshots、configuration、quotas、security、procedures、visibility labels、rsgroup和storefiletracker。
你可以执行各种命令来进行表的操作、数据的增删改查、配置管理、权限管理等。
HBase Shell提供了一些常用命令示例:
create:创建表。
disable:禁用表。
enable:启用表。
describe:显示表的结构和属性。
get:获取指定行的数据。
put:插入或更新数据。
scan:扫描表中的数据。
delete:删除指定行或列的数据。
list:列出所有表或命名空间。
alter:修改表的结构或属性。
count:统计表中的行数。
二、操作
创建命名空间类似于Mysql中的数据库:create_namespace
创建ns1,ns2命名空间
hbase:005:0> create_namespace 'ns1'
Took 0.2768 seconds
hbase:006:0> create_namespace 'ns2'
Took 0.1402 seconds

查看一下创建的命令空间列表:list_namespace
这里的default,hbase是hbase自带的命名空间
hbase:008:0> list_namespace
NAMESPACE
default
hbase
ns1
ns2
4 row(s)
Took 0.0132 seconds
#正则方式查看以ns开头命名空间
hbase:009:0> list_namespace "ns*"
NAMESPACE
ns1
ns2
2 row(s)
Took 0.0156 seconds

查看命名空间属性:describe_namespace
因为没有设置这里没有,需要在创建命名空间时设置
hbase:010:0> describe_namespace 'ns1'
DESCRIPTION
{NAME => 'ns1'}
Quota is disabled
Took 0.1844 seconds

创建一个表t1包含三列f1,f2,f3:create
hbase:011:0> create 't1','f1','f2','f3'
Created table t1
Took 1.2317 seconds
=> Hbase::Table - t1

查看我们创建的表:list
在我们的web端也是能够看到的:http://HbaseIP:16010/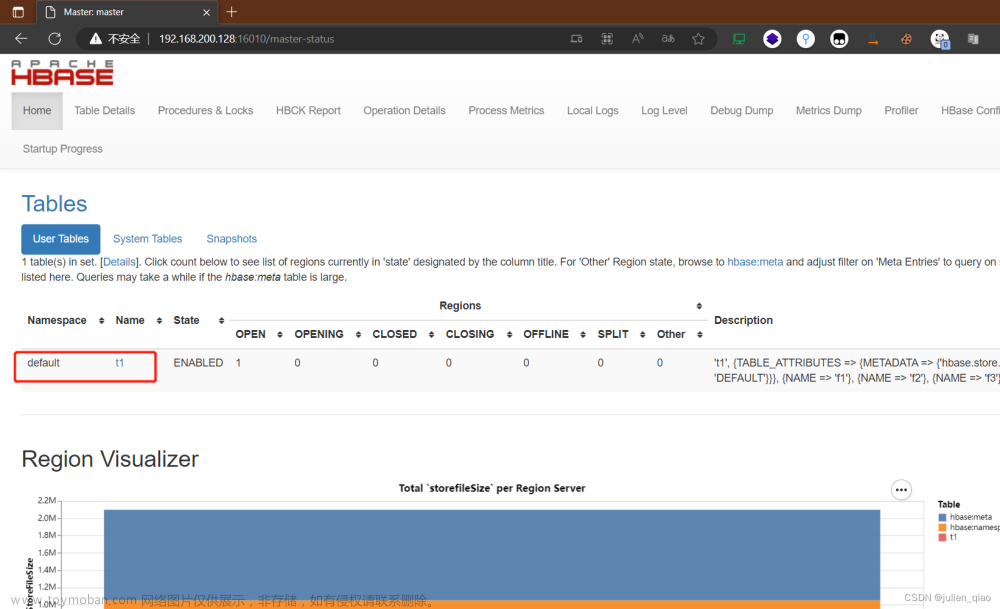
现在我们做一个实例做一个学生表:

添加数据:put
put 't1', 'row1', 'f1:name', 'tom'
put 't1', 'row1', 'f1:age', 18
put 't1', 'row1', 'f1:height', 172
put 't1', 'row2', 'f1:name', 'jack'
put 't1', 'row2', 'f1:age', 19
put 't1', 'row2', 'f1:height', 180

查看插入的数据(用于数据量较少情况):scan ‘t1’
注意:数据量少情况不然卡死
scan 't1'

使用get命令获取某单元格数据:get
get 't1','row1','f1:name'
get 't1','row1','f1:age'
get 't1','row1','f1:height'
get 't1','row2','f1:name'
get 't1','row2','f1:age'
get 't1','row2','f1:height'


这样创建的表存在一个致命问题:版本只能存在一个,因为我们创建t1时并没有做属性
可以通过:alter ‘t1’,{NAME => ‘f1’,VERSIONS => 3}修改我们的表
我们这直接新建一个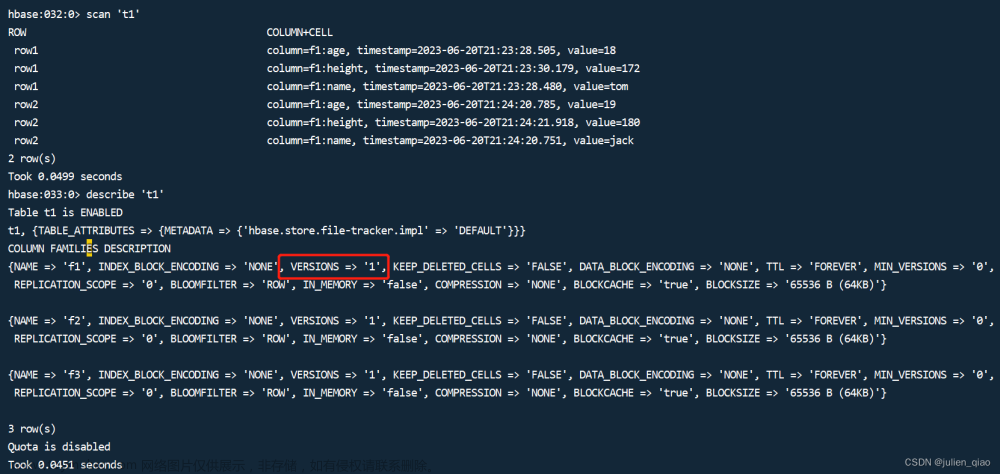
我们重新创建一个可以保存多版本的表:create
创建一个可以保存三个版本的student表
create 'student',{NAME => 'f1',VERSIONS => 3}

再次写入数据到student表:
put 'student', 'row1', 'f1:name', 'tom'
put 'student', 'row1', 'f1:age', 18
put 'student', 'row1', 'f1:height', 172
put 'student', 'row2', 'f1:name', 'jack'
put 'student', 'row2', 'f1:age', 19
put 'student', 'row2', 'f1:height', 180

修改一个数据再次查看版本:
put 'student', 'row1', 'f1:name', 'julein'
get 'student','row1',{COLUMN => 'f1:name',VERSIONS => 2}

删除行数据:deleteall
删除行数据:deleteall 't1','row1'
只剩下row2数据
删除一个单元格数据:delete
delete 't1','row2','f1:name'
删除后:
删除表:disable+drop文章来源:https://www.toymoban.com/news/detail-493551.html
disable 't1'
drop 't1'
t1被删除了
一个简单的shell操作完成。文章来源地址https://www.toymoban.com/news/detail-493551.html
到了这里,关于【云计算】HBase表操作的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!








