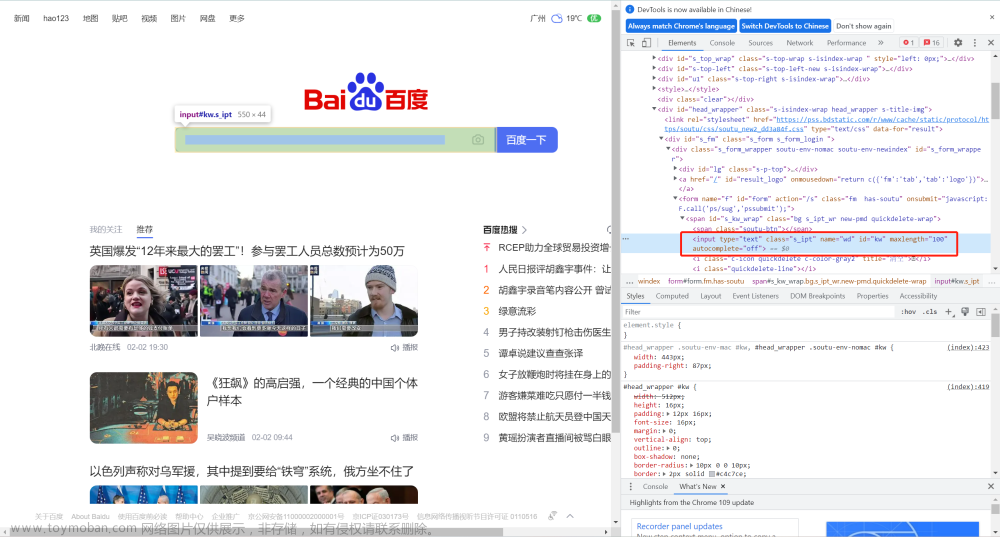
selenium元素定位
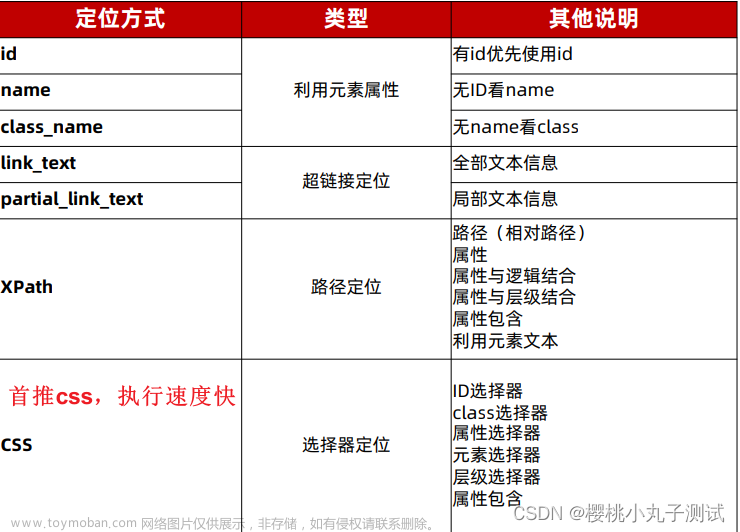
selenium定位元素的方式有8种。
fild_element(by,value):by表示使用的定位方式,定位方式可以参见By类。value表示值,例如:根据id定位
By.ID,value=id属性的值。该方法返回元素对象,返回值如下:
<selenium.webdriver.remote.webelement.WebElement (session="b9c957076ccceb820ad3b873f1292d35", element="f5a68c75-fa74-4613-809a-cda1b3198d94")>
这个返回结果说明:返回值为WebElement类的对象,元素在使用方法时,应该调用的就是WebElement类的方法
By类提供的定位方法
-
By.ID:根据标签的id属性的值定位元素
from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get("https://www.baidu.com") driver.find_element(By.ID,'kw').send_keys('hello python')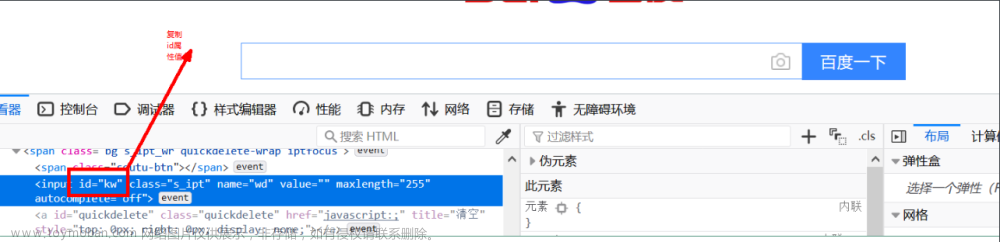
-
By.NAME :根据标签的name属性值定位元素
from selenium import webdriver driver = webdriver.Firefox() driver.get('https://www.baidu.com') driver.find_element(By.NAME,'wd').send_keys('百度')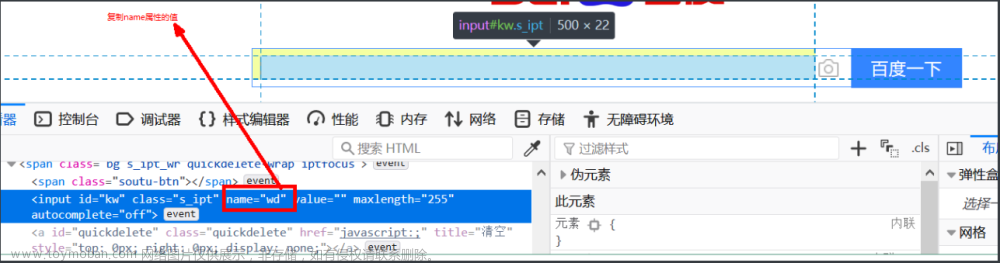
-
By.CLASS_NAME:根据class属性值定位元素,需要注意,尽量不要用class定位,因为一个页面中,往往会出现多个元素的class属性值相同,所以在定位的时候,如果有多个属性值相同的元素,自动会定位第一个元素。
from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get("https://www.baidu.com") driver.find_element(By.CLASS_NAME,'s_ipt').send_keys('hello python')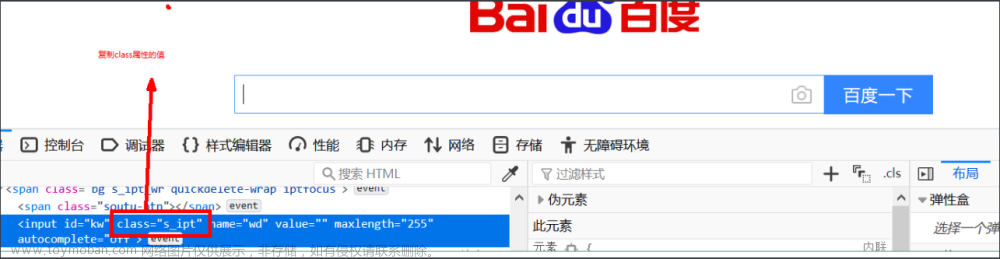
-
By.LINK_TEXT:根据超链接文本内容定位元素
from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get('https://www.baidu.com') driver.find_element(By.LINK_TEXT,'新闻').click()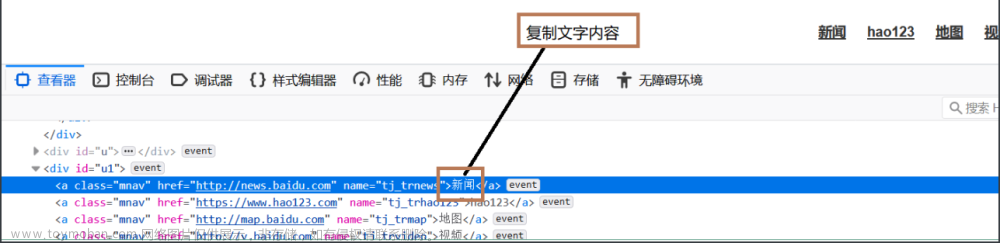
-
By.PARTIAL_LINK_TEXT:根据部分连接文本内容定位元素
from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get('https://www.baidu.com') driver.find_element(By.PARTIAL_LINK_TEXT,'hao').click()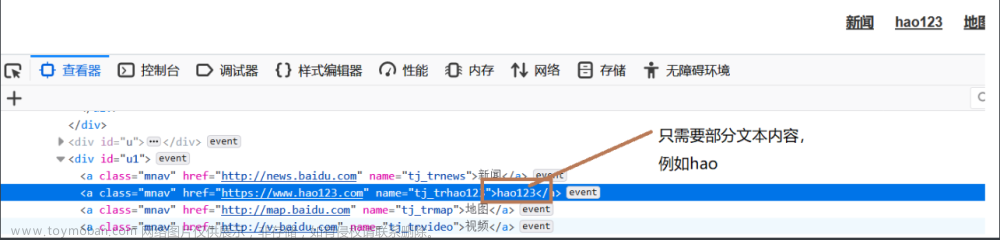
-
By.TAG_NAME:根据标签名定位元素
from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get('https://www.baidu.com') driver.find_element(By.TAG_NAME,'area').click()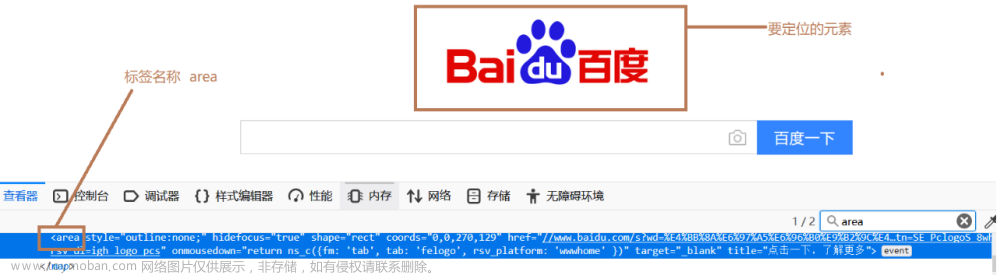
-
By.CSS_SELECTOR:根据css选择器定位元素,如果你要定位的元素,没有id、没有name、没有class,tagname也不唯一、又不是超链接。此时如何定位
from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get('https://www.baidu.com') driver.find_element(By.CSS_SELECTOR,'#su').click()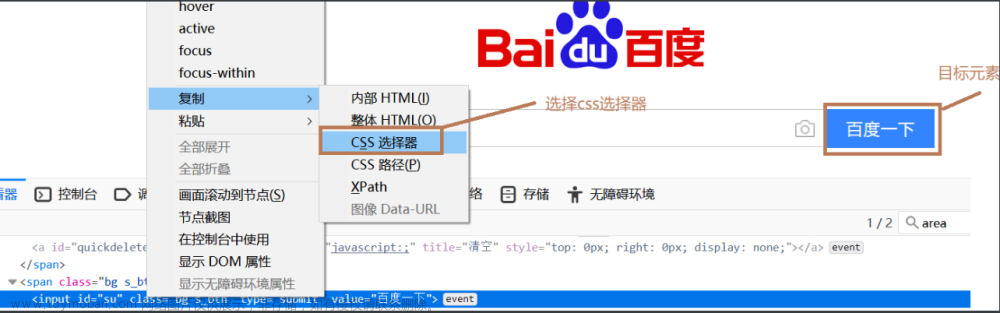
-
By.XPATH:根据xpath路径定位元素
from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get('https://www.baidu.com') driver.find_element(By.XPATH,'//*[@id="kw"]').click()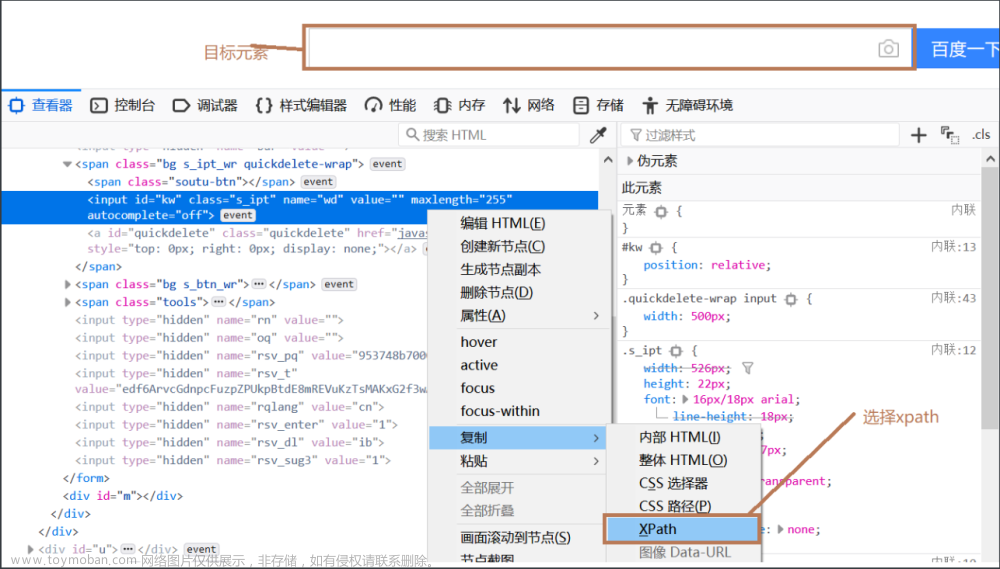
注:xpath有两种表示方式:
1、绝对路径:
从html标签开始,顺序向下,逐层向下,直到目标元素,形成的最后的路径就是xpath路径,如果元素有多个相同的同级标签(兄弟标签),则可以在标签后加[数字],数字表示为第几个标签,数字从1开始。
示例:从下面的html代码中,定位name属性为输入的输入框,xpath路径表示为:
/html/body/div/table/tr/td[1]/input
<!DOCTYPE html> <html> <head> <title>hello</title> </head> <body> <div> <table> <tr> <td> <input type="text" name="输入"> </td> <td> <button>登录</button> </td> </tr> </table> </div> </body> </html> 2、相对路径:
从目标元素定位时,无法确认唯一标识,从该元素开始向上,直到找到一个能唯一定位的父级标签,再从该父级标签向下定位。不从html开始。
示例:在这个案例中,想要定位第一个input标签,通过xpath相对路径定位方式:
首先:在目标input上如果无法唯一定位,可以向上查找他的父级标签是否可以唯一定位,如果不行,可以继续向上查找,直到找了id为in1的这个div标签,开始从该标签向下定位,先定位到这个div标签"//div[@id='in1']",再向下定位,如果不能确定id为in1的标签是div,可以用*代替。这个路径可以表示为:
1、 //div[@id='in1']/table/tr/td[1]/input
2、 //*[@id='in1']/table/tr/td[1]/input
语法:
//标签名[@属性=“属性值”]
<!DOCTYPE html> <html> <head> <title>hello</title> </head> <body> <div></div> <div></div> <div id="in1"> <table> <tr> <td> <input type="text" name=""> </td> <td> <input type="submit" name=""> </td> </tr> </table> </div> </body> </html>
定位方法:
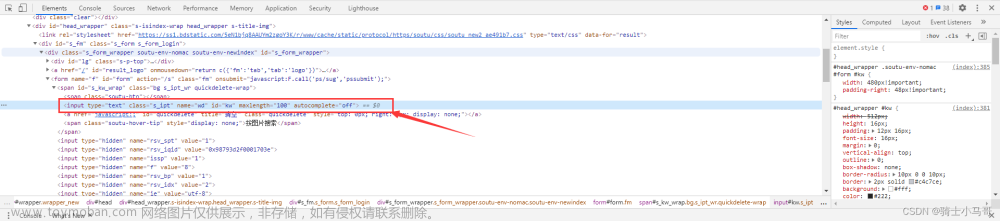
在firefox浏览器中,将鼠标放到目标元素上,右键选择“查看元素”(Chrome浏览器叫检查),会在开发者模式中显示你要定位目标元素。
在目标元素上,可以查看目标元素有哪些属性,如果有id或name属性,可以使用by_id或by_name定位元素。
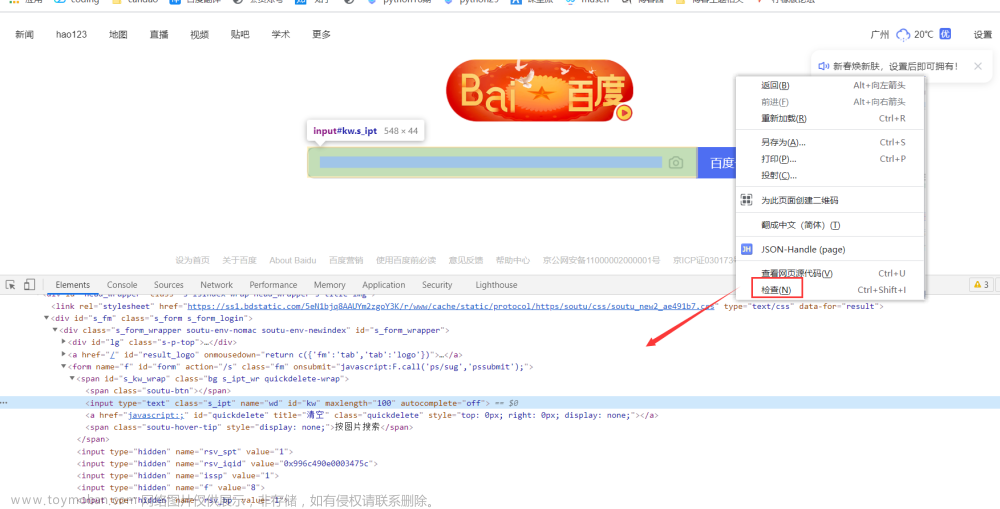
如果上述方式不能帮助你定位元素,可以采用css选择器方式定位,在目标元素上,右键——>复制——>css选择器
在常用元素定位方式中,最常用的css和xpath两种,因为这两中定位方式基本可以定位所有的页面元素,也可以使用这两种方式实现父子元素定位或兄弟元素定位。
css和xpath区别css比xpath要快一些xpath要遍历整个html文件
组元素定位
使用方法:
find_elements方法,与find_element方法一样。
区别是该方法以列表形式返回一组元素。如果需要其中一个元素,可以使用列表的下表方式获取,或则是使用for循环遍历所有的元素。
示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
all_a = driver.find_elements(By.TAG_NAME,'a')
# 获取列表的长度,那么就能知道a标签的元素有多少个
print(len(all_a))
selenium执行JS代码
在selenium中,可以直接将js代码执行。方法为execute_script,接收要执行的js代码,如果需要获取js代码的执行结果,js代码中,需要使用return返回
execute_script(js代码)
示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
drver = webdriver.Chrome()
drver.get('https://www.baidu.com')
# return表示将元素定位后,返回元素信息
js = 'return document.getElementById("kw")'
ele = drver.execute_script(js)
print(ele)
使用js代码操作滚动条
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.maximize_window()
driver.get('https://python.org')
js = 'scrollBy(0,1000)'
driver.execute_script(js)
修改元素的属性
1、在很多窗口中,在点击元素时,会跳转到一个新的窗口,在selenium中,往往需要切换窗口才能继续操作,那么可以使用js代码将它改成在当前窗口打开。
#coding=utf-8
__author__ = 'jia'
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.maximize_window()
driver.get('https://www.baidu.com')
# 找到新闻这个超链接,删除它的target属性
js = 'document.querySelector("#s-top-left > a:nth-child(1)").removeAttribute("target")'
driver.execute_script(js)
driver.find_element(By.CSS_SELECTOR,'#s-top-left > a:nth-child(1)').click()
2、在处理一些特殊的操作时,例如时间控件中,无法输入时间,只能操作时间控件来选择时间,这个操作相对比较麻烦,那么我们可以使用js将时间输入框改变成可输入,那么就可以直接输入时间即可,不用操作时间控件。
#coding=utf-8
__author__ = 'jia'
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.maximize_window()
driver.get('https://www.baidu.com')
# 找到新闻这个超链接,删除它的readonlin属性
js = 'document.querySelector("#s-top-left > a:nth-child(1)").removeAttribute("readonlin")'
driver.execute_script(js)
selenium的元素操作
send_keys(内容):向元素中输入内容
click():点击元素
text:获取元素中的文本内容,返回文本内容
title:获取当前窗口的title,返回title
is_displayed(): 如果元素可见,返回True,不可见返回False,不存在则产生NoSuchElementException,一个元素在网页中的状态有存在并可见、存在但不可见、不存在
current_url:返回当前窗口的URL地址
window_handles:获取所有窗口的句柄,获取所有已经打开的窗口
current_window_handle:获取当前窗口的句柄。
clear():清空文本框中的内容
等待:
在做自动化测试时,难免会碰到一些问题,比如你在脚本中操作某个对象时,页面还没有加载出来,你的操作语句已经被执行,从而导致脚本执行失败,针对这样的问题webdriver提供了等待操作,等待一定的时间,或在一个时间段内发现对象,则继续操作。Webdriver提供了隐式等待和显示等待,当然,我们也可以借助包的模块,实现强制等待。
为了解决这些问题,我们可以在脚本中适当加入等待时间,以确保目标元素能够被定位到。
sleep等待
sleep是等待多少秒后,再继续执行后面的代码,要想使用sleep,必须先导入time模块。
示例:在百度页面中,输入test,点击百度一下,必须要等待一段时间,才能点击元素
from selenium import webdriver
from time import sleep
driver = webdriver.Firefox()
driver.get('https://www.baidu.com')
driver.find_element_by_id('kw').send_keys('test')
driver.find_element_by_id('su').click()
#等待2秒,再点击后面的操作
sleep(2)
driver.find_element_by_css_selector('#\31 > h3:nth-child(1) > a:nth-child(1)').click()
注:sleep是强制等待,必须等到达到等待时间,才会继续执行下一步操作。时间如果设置的太长,会导致用例执行时间长,脚本执行效率底,等待时间短,依然可能发生元素没有加载成功。
智能等待:
隐式等待:implicitly_wait
from selenium import webdriver
driver = webdriver.Firefox()
driver.get('https://www.baidu.com')
driver.find_element_by_id('kw').send_keys('test')
driver.find_element_by_id('su').click()
#智能等待30秒
driver.implicitly_wait(30)
driver.find_element_by_css_selector('#\31 > h3:nth-child(1) > a:nth-child(1)').click()
隐式等待30秒,是总的等待时间,在这30内,如果任意一个时间上页面加载完成,那么等待将不再继续等待,直接执行后面的操作。implicitly_wait每0.5秒判断页面是否加载成功。如果30秒任然没有加载完成,则产生超时。
隐式等待适合在页面加载时使用,整个页面的加载。
显示等待:
WebDriverWait
显式等待:WebDriverWait()
在界面操作时,如果使用等待,需要明确知道等待多长时间,如果时间太短,则容易产生超时,未能找到操作元素,如果时间太长,则容易浪费时间。如果使用sleep,则是全局等待。可以配合的实现针对某个元素的等待操作。
示例:
#coding=utf-8
__author__ = 'jia'
'''
显示等待:
等待指定的元素在页面中显示出来,与隐式等待不同,隐式等待不指定等待的主体,而是将整个页面作为等待
对象
显示等待可以设置等待指定的页面元素
'''
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
driver = webdriver.Chrome()
driver.get("https://www.sina.com.cn")
# 等待页面中,“军事”这个元素
# 1、示例化WebDriverWait对象
wait = WebDriverWait(driver,20)
# 编写一个定位元素的函数
# def fun(driver):
# print('等待元素')
# return driver.find_element(By.LINK_TEXT,'军事')
# 调用等待方法
wait.until(lambda x:x.find_element(By.LINK_TEXT,'军事'))
driver.find_element(By.LINK_TEXT,'军事').click()
2、使用ec模块来实现等待
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
driver = webdriver.Chrome()
driver.get("https://www.sina.com.cn")
WebDriverWait(driver,20).until(ec.visibility_of_element_located((By.LINK_TEXT,'军事')))
driver.find_element(By.LINK_TEXT,'军事').click()
WebDriverWait(driver,20).until(ec.visibility_of_element_located((By.LINK_TEXT,'军事')))
这段代码需要解释,WebDriverWait(driver,20).until(ec.visibility_of_element_located((By.LINK_TEXT,'军事')))。通过文本,检查页面是否有军事这个元素,并且可见,并且该元素的高和宽不为0。总结该句代码的意思为,判断页面是否有军事这个元素,并可见,如果没有完成,则默认每隔0.5秒检查一次,直到20秒后超时,如果在20秒内完成,则继续执行之后的代码。如果20秒内容元素没有找到,则超时。
expected_conditions
presence_of_all_elements_located()类:期望检查是否存在至少一个元素在网页上。返回WebElements列表
visibility_of_any_elements_located()类:期望检查至少有一个元素是可见的在网页上。返回WebElements列表
visibility_of_all_elements_located()类:期望检查所有元素是否存在于a的DOM上页面和可见。用于查找元素一旦找到并可见,就会返回WebElements列表
text_to_be_present_in_element()类:期望检查给定文本是否存在于指定的元素。
text_to_be_present_in_element_value()类:期望检查元素中是否存在给定文本定位器,文本
invisibility_of_element_located()类:用于检查元素是否不可见的期望出现在DOM上。
invisibility_of_element()类:检查元素是否不可见的期望出现在DOM上。
element_to_be_clickable()类:检查元素的期望是可见的并且已启用你可以点击它
staleness_of()类:等到元素不再附加到DOM。element是要等待的元素。如果元素仍附加到DOM,则返回False,否则返回true。
element_to_be_selected()类:选择检查选择的期望。element是WebElement对象
element_located_to_be_selected()类:选择对元素的期望。locator是(by,path)的元组
alert_is_present()类:检查是否出现alter面板
如果文章对你有帮助,记得点赞,收藏,加关注。会不定期分享一些干货哦......
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
这些资料,对于想做【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!凡事要趁早,特别是技术行业,一定要提升技术功底。希望对大家有所帮助……加入我的学习交流群一起学习交流讨论把!!!! 文章来源:https://www.toymoban.com/news/detail-498273.html
 文章来源地址https://www.toymoban.com/news/detail-498273.html
文章来源地址https://www.toymoban.com/news/detail-498273.html
到了这里,关于【selenium自动化测试】如何定位页面元素,及对页面元素的操作方法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!