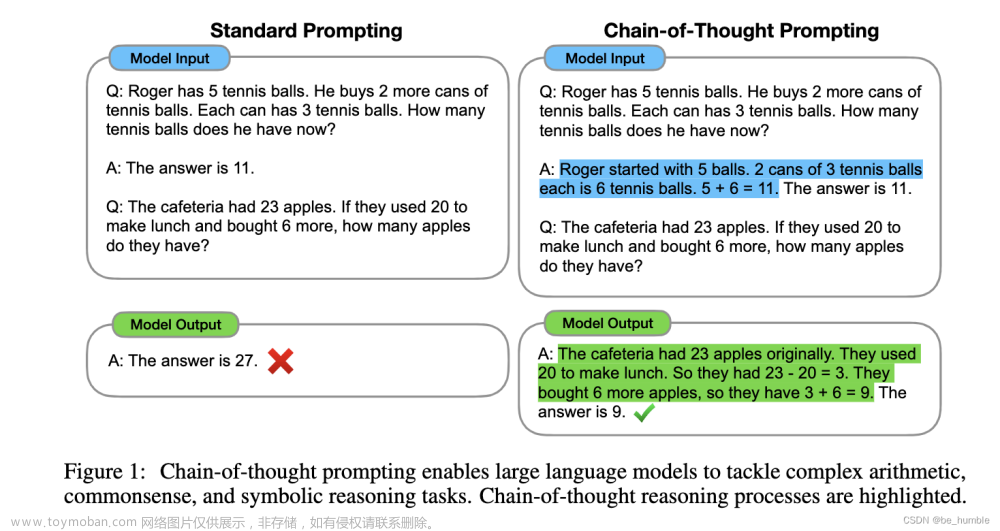
前一章思维链基础和进阶玩法我们介绍了如何写Chain-of-thought Prompt来激活生成逐步推理,并提高模型解决复杂问题的能力,这一章我们追本溯源,讨论下COT的哪些元素是提升模型表现的核心?
要进行因果分析,需要把思维链中的不同元素拆解开来,然后通过控制变量实验,来研究不同元素对COT效果的影响。以下两篇论文的核心差异就在于: COT的变量拆解,以及控制变量的实验方式。
结合两篇论文的实验结论,可能导致思维链比常规推理拥有更高准确率的因素有
- 思维链的推理过程会重复问题中的核心实体,例如数字,人物,数字等
- 思维链正确逻辑推理顺序的引入
友情提示:以下论文的实验依赖反事实因果推断,这种因果分析方式本身可能存在有偏性进而得到一些错误结论,读论文有风险,迷信论文需谨慎哈哈~
TEXT AND PATTERNS: FOR EFFECTIVE CHAIN OF THOUGHT IT TAKES TWO TO TANGO
- 测试模型:PaLM-62B,GPT3,CODEX
google这篇论文比较早,按个人阅读舒适度来划分个人更推荐第二篇论文哟~
COT元素
论文把影响元素拆分成了Text,Symbol和Pattern三个部分, 如下

论文给出了symbol和pattern的定义,剩下的token全是Text
- symbol:是数据集的核心主体,数学问题就是数字,SPORT数据集就是运动员和运动项目, DATE数据集就是时间,这里的symbol类似实体的概念
- pattern: 可以是symbol的组合,连接符(公式)或者帮助模型理解任务的表述结构。这里允许pattern和symbol重合,也就是整个公式是pattern,但公式中的数字同样是symbol。但在非数学问题上我个人觉得pattern的定义有点迷幻...
实验
论文针对以上3个元素分别进行了实验,通过改变COT few-shot prompt中特定元素的取值,来分析该元素对COT效果的贡献
观点1.Symbol的形式和取值本身对COT影响不大
这里论文用了两种控制变量的方式:symbol随机采样和特殊符号替换
- 特殊符号替换(symb_abs)
abstract symbol就是用特殊符号来替换symbol,这里作者同时替换了question,prompt和answer里面的symbol如下

- 随机替换(symb_ood)
OOD类似随机替换,不过论文的替换方式有些迷幻。对于GSM8k数学问题,作者用一一对应的数学数字替换了文字数字;对于体育常识问题的替换比较常规作者用随机的人名和赛事进行替换;对于时间常识问题作者用未来时间替换了当前时间?? 注意这里的替换作者保证了推理逻辑的一致性,包括同一数字用同一symbol替换,替换实体也符合推理逻辑,以及对问题中的答案也进行了替换。所以这里纯纯只能论证symbol本身的取值和类型(例如数字1和一)是否对COT有影响
abstract symbol就是用特殊符号来替换symbol,这里作者同时替换了question,prompt和answer里面的symbol如下

这种替换方式下的实验结果如下,除了体育问题中的随机实体替换,其余symbol的替换对COT的效果影响都非常有限。这让我想到了一篇关于NER模型的泛化性主要来自模型学会了不同类型的实体会出现在哪些上下文中,而不仅是对实体本身的形式进行了记忆。他们的实验方式和作者替换symbol的操作其实很类似,这种替换并不大幅影响下文对上文的Attention。

观点2. pattern是COT生效的必要不充分条件
对于Pattern作者更换了实验方式,控制变量采用了只保留pattern,和只剔除pattern这两种实验类型。
以数学问题为例,只保留pattern就是推理过程只保留数学公式,只剔除pattern就是整个推理过程只把公式剔除。其余问题类型,考虑在前面的pattern定义阶段个人就感觉有些迷幻,... 所以我们直接跳到实验结论吧
- 只有pattern的COT效果很差,和直接推理差不多,说明只有patten肯定是不够的,这和上一篇博客提到COT小王子尝试过的只有数学公式的COT效果不好的结论是一致的。
- 剔除pattern的COT效果受到影响,因此pattern对COT有显著影响,但很显然还有别的因素

观点3. 推理出现问题中的关键实体且和问题保持格式一致很重要
最后针对Text部分,作者采用了实体替换和语法替换
- 实体替换(text_diff_entities):把推理中的实体随机替换成和问题中不一样的实体,包括数学问题中的数字,常识问题中的时间,地点和任务。个人感觉这应该是symbol的实验??


效果上,随机实体替换对所有任务的COT效果影响非常大, 所以在推理阶段使用Question中的核心实体很重要。其次推理和question在语法上的不一致会影响COT在部分任务上的表现。

Towards Understanding Chain-of-Thought Prompting: An Empirical Study of What Matters
- 测试模型:text-davinci-002, text-davinci-003
整体上第二篇论文的思路更简单清晰,在拆解元素的同时还定义了关系。
COT元素
论文首先定义了思维链中的两种核心元素
- Bridge Object: 模型解决问题所需的核心和必须元素。例如数学问题中的数字和公式,QA问题中的实体,有点类似把论文1中pattern和symbol和在了一起,感觉定义更清晰了
- Language Template:除去Bridge Object剩余的部分基本都是Language Template

其次定义了思维链的两种核心关系
- 一致性(Coherence): 推理步骤之间的逻辑顺序, 先说什么后说什么
- 相关性(Relevance): Question中核心元素是否在推理中出现
实验
论文的消融实验通过人工修改few-shot COT中的few-shot样本,来验证思维链中不同元素的贡献,这里我们以一个数学问题问题为例,看下实验的两个阶段
观点1. 完全正确的COT并非必要
第一步作者证明了完全正确的In-Context样本并不是必须的,用的什么方法嘞?
如下图所示,作者手工把正确的In-Context COT样本改写成错误的,改写方式是在保留部分推理顺序,和部分bridge object的前提下,随机的把推理改成错误的推理逻辑。作者发现魔改后错误的few-shot的样本,对比正确的few-shot-cot保留了80%+的水平,只有小幅的下降。

观点2.推理顺序和核心元素的出现更重要
既然完全正确的COT样本并非必须,那究竟思维链的哪些元素对效果的影响最大呢?针对以上两种元素和两种关系,作者用了数据增强的方式来对few-shot样本进行修改,得到破坏某一种元素/关系后的few-shot样本
- 破坏相关性: 这里使用了Random Substitution; 针对Bridge Obejct,就是固定文字模板,把数学问题中出现的数字在COT里面(32/42/35)随机替换成其他数字,这里为了保持上下文一致性相同的数字会用相同的随机数字来替换; 针对template,就固定Bridge Object,从样本中随机采样其他的COT推理模板来进行替换。
- 破坏一致性: 这里使用了Random Shuffle;针对Bridge Object,就是把COT中不同位置的Bridge Obejct随机打乱顺序;针对Template,就固定Bridge Object,把文字模板的句子随机改变位置。
整体效果如下图

论文正文用的是text-davinci-002,附录里也补充了text-davinci-003的效果,看起来003的结果单调性更好,二者结论是基本一致的,因此这里我们只看下003的消融实验效果,可以得到以下几个核心结论
- 对比COT推理的正确性,相关性和一致性更加重要,尤其是相关性。也就是在推理过程中复述question中的关键信息可以有效提高模型推理准确率。个人猜测是核心元素的复述可以帮助模型更好理解指令识别指令中的关键信息,并提高该信息对应的知识召回【这一点我们在下游难度较高的多项选择SFT中也做过验证,我们在多项选择的推理模板的最后加入了题干的复述,效果会有一定提升,进一步把选项的结果完形填空放到题干中,效果会有更进一步的提升】
- Language Template的一致性贡献度较高。也就是正确的逻辑推理顺序有助于模型推理效果的提升。这一点更好理解主要和decoder需要依赖上文的解码方式相关。【还是多项选择的指令微调,我们对比了把选项答案放在推理的最前面和放在复述题干之前的效果,都显著差于先推理分析,复述题干并填入选项答案,最后给出选项答案这个推理顺序】
 文章来源:https://www.toymoban.com/news/detail-513014.html
文章来源:https://www.toymoban.com/news/detail-513014.html
想看更全的大模型相关论文梳理·微调及预训练数据和框架·AIGC应用,移步Github >> DecryptPropmt文章来源地址https://www.toymoban.com/news/detail-513014.html
到了这里,关于解密Prompt系列10. 思维链COT原理探究的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!