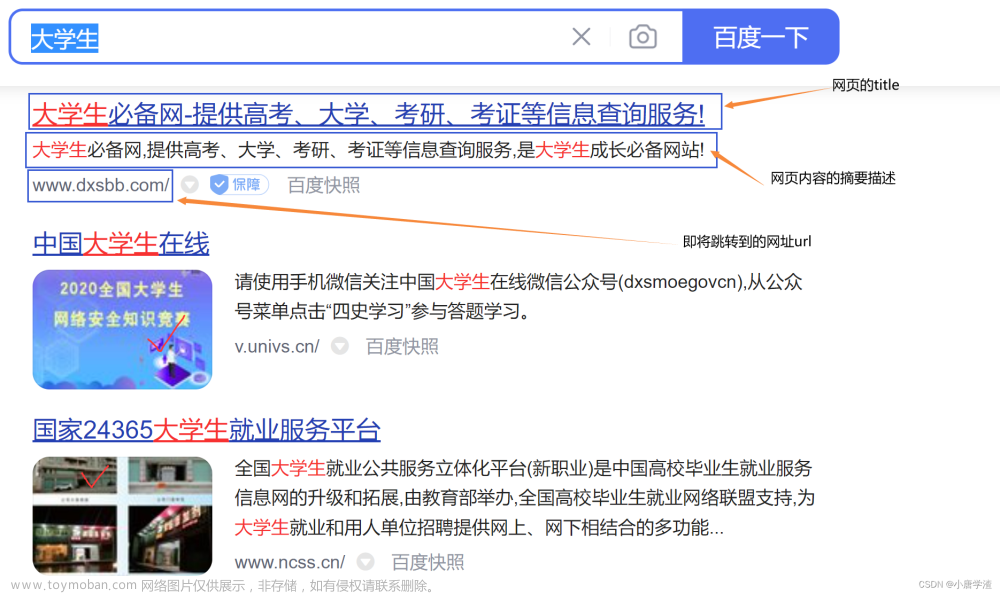
开源搜索引擎框架和产品有很多,例如elasticsearch,sphinx,xapian,lucence,typesense,MeiliSearch 等,分别用不同的语言实现,具有类似但不完全相同的功能。准确来说不属于通用的搜索引擎,而是属于一种基于索引的文字检索系统。
考虑到方便将这种检索系统通过代码开发的形式集成到自己的项目种,而不是单独部署一个完整的系统使用,这里推荐使用C++语言编写的xapian,作为依赖库的形式,调用C++ api在工程中使用。
以下基于一个简单的demo来延时如何使用xapian来构建索引和发起检索。
项目结构
xapian_starter
- xapian-core-1.4.22
- src
|- main.cpp
- CMakeLists.txt
注意
- xapian官网仅提供了unix系统下的编译指南,这里的demo仅支持unix下编译运行
- 在部分环境中编译还需要额外引入zlib库的头文件和库文件
CMakeLists.txt
cmake_minimum_required(VERSION 3.0)
# this only works for unix, xapian source code not support compile in windows yet
project(xapian_demo)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
include_directories(
${CMAKE_CURRENT_SOURCE_DIR}/xapian-core-1.4.22/include
)
link_directories(
${CMAKE_CURRENT_SOURCE_DIR}/xapian-core-1.4.22/.libs
)
file(GLOB SRC
src/*.h
src/*.cpp
)
add_executable(${PROJECT_NAME} ${SRC})
target_link_libraries(${PROJECT_NAME}
xapian
)
main.cpp
#include <iostream>
#include <string>
#include "xapian.h"
const std::string index_data_path = "./index_data";
const std::string doc_id1 = "doc1";
const std::string doc_title1 = "How to build self search engine";
const std::string doc_content1 = "What is the search engine?\nMaybe you should ask baidu or google.\nBut I want to develop my own app.\nThen you may need the xapian source code.";
const std::string doc_id2 = "doc2";
const std::string doc_title2 = "Nex generation search platform";
const std::string doc_content2 = "Every one know search is use full\nIt can be done just by a PC or phone.\nPlatform is very important";
const int DOC_ID_FIELD = 101;
void save_data()
{
std::cout << "--- save_data" << std::endl;
Xapian::WritableDatabase db(index_data_path, Xapian::DB_CREATE_OR_OPEN);
Xapian::TermGenerator indexer;
Xapian::Document doc1;
doc1.add_value(DOC_ID_FIELD, doc_id1); // custom property
doc1.set_data(doc_content1); // payload
indexer.set_document(doc1);
indexer.index_text(doc_title1); // could use space seperated text line like terms or article
db.add_document(doc1);
Xapian::Document doc2;
doc2.add_value(DOC_ID_FIELD, doc_id2); // custom property
doc2.set_data(doc_content2);
indexer.set_document(doc2);
indexer.index_text(doc_title2);
db.add_document(doc2);
db.commit();
}
void search_data1()
{
std::cout << "--- search_data1" << std::endl;
Xapian::Database db(index_data_path);
Xapian::Enquire enquire(db);
Xapian::QueryParser qp;
// std::string query_str = "search engine";
// Xapian::Query query = qp.parse_query(query_str);
Xapian::Query term1("search");
Xapian::Query term2("engine");
Xapian::Query query = Xapian::Query(Xapian::Query::OP_OR, term1, term2);
std::cout << "query is: " << query.get_description() << std::endl;
enquire.set_query(query);
Xapian::MSet matches = enquire.get_mset(0, 10); // find top 10 results
std::cout << matches.get_matches_estimated() << " results found" << std::endl;
std::cout << "matches 1-" << matches.size() << std::endl;
for (Xapian::MSetIterator it = matches.begin(); it != matches.end(); ++it)
{
Xapian::Document doc = it.get_document();
std::string doc_id = doc.get_value(DOC_ID_FIELD);
// FIXME: not every record will show field value, should do filter later
std::cout << "rank: " << it.get_rank() + 1 << ", weight: " << it.get_weight() << ", match_ratio: " << it.get_percent() << "%, match_no: " << *it << ", doc_id: " << doc_id << ", doc content: [" << doc.get_data() << "]\n" << std::endl;
}
}
void search_data2()
{
std::cout << "--- search_data2" << std::endl;
Xapian::Database db(index_data_path);
Xapian::Enquire enquire(db);
Xapian::QueryParser qp;
Xapian::Query term1("search");
Xapian::Query term2("platform");
Xapian::Query query = Xapian::Query(Xapian::Query::OP_AND, term1, term2);
std::cout << "query is: " << query.get_description() << std::endl;
enquire.set_query(query);
Xapian::MSet matches = enquire.get_mset(0, 10); // find top 10 results, like split page
std::cout << matches.get_matches_estimated() << " results found" << std::endl;
std::cout << "matches 1-" << matches.size() << std::endl;
for (Xapian::MSetIterator it = matches.begin(); it != matches.end(); ++it)
{
Xapian::Document doc = it.get_document();
std::string doc_id = doc.get_value(DOC_ID_FIELD);
// FIXME: not every record will show field value, should do filter later
std::cout << "rank: " << it.get_rank() + 1 << ", weight: " << it.get_weight() << ", match_ratio: " << it.get_percent() << "%, match_no: " << *it << ", doc_id: " << doc_id << ", doc content: [" << doc.get_data() << "]\n" << std::endl;
}
}
int main(int argc, char** argv)
{
std::cout << "hello xapian" << std::endl;
save_data();
search_data1();
search_data2();
return 0;
}
其中文章来源:https://www.toymoban.com/news/detail-525626.html
- 任何文件或者数据都需要体检构建索引进入xapian的本地存储系统
- 构建索引可以利用文章标题或者文章内容的分词列表,默认识别空格分隔的字符串,英文天然支持,中文需要提前用其他的代码预先做分词再传入
- 为了便于跟数据库结合使用,可以在构建索引阶段给文本关联一个属性值,方便检索完的结果可以利用属性值取实际的业务数据库中精准获取完整的数据
- 检索的结果中可能存在部分结果没有属性值,所以建议检索完后再做过滤
运行结果
--- save_data
--- search_data1
query is: Query((search OR engine))
19 results found
matches 1-10
rank: 1, weight: 0.354232, match_ratio: 100%, match_no: 4, doc_id: , doc content: [What is the search engine?
Maybe you should ask baidu or google.
But I want to develop my own app.
Then you may need the xapian source code.]
rank: 2, weight: 0.354232, match_ratio: 100%, match_no: 6, doc_id: , doc content: [What is the search engine?
Maybe you should ask baidu or google.
But I want to develop my own app.
Then you may need the xapian source code.]
rank: 3, weight: 0.354232, match_ratio: 100%, match_no: 8, doc_id: , doc content: [What is the search engine?
Maybe you should ask baidu or google.
But I want to develop my own app.
Then you may need the xapian source code.]
rank: 4, weight: 0.354232, match_ratio: 100%, match_no: 10, doc_id: doc1, doc content: [What is the search engine?
Maybe you should ask baidu or google.
But I want to develop my own app.
Then you may need the xapian source code.]
rank: 5, weight: 0.354232, match_ratio: 100%, match_no: 12, doc_id: doc1, doc content: [What is the search engine?
Maybe you should ask baidu or google.
But I want to develop my own app.
Then you may need the xapian source code.]
rank: 6, weight: 0.354232, match_ratio: 100%, match_no: 14, doc_id: doc1, doc content: [What is the search engine?
Maybe you should ask baidu or google.
But I want to develop my own app.
Then you may need the xapian source code.]
rank: 7, weight: 0.354232, match_ratio: 100%, match_no: 16, doc_id: doc1, doc content: [What is the search engine?
Maybe you should ask baidu or google.
But I want to develop my own app.
Then you may need the xapian source code.]
rank: 8, weight: 0.354232, match_ratio: 100%, match_no: 18, doc_id: doc1, doc content: [What is the search engine?
Maybe you should ask baidu or google.
But I want to develop my own app.
Then you may need the xapian source code.]
rank: 9, weight: 0.209633, match_ratio: 59%, match_no: 1, doc_id: , doc content: [What is the search engine?
Maybe you should ask baidu or google.
But I want to develop my own app.
Then you may need the xapian source code.]
rank: 10, weight: 0.209633, match_ratio: 59%, match_no: 2, doc_id: , doc content: [What is the search engine?
Maybe you should ask baidu or google.
But I want to develop my own app.
Then you may need the xapian source code.]
--- search_data2
query is: Query((search AND platform))
8 results found
matches 1-8
rank: 1, weight: 0.605063, match_ratio: 100%, match_no: 5, doc_id: , doc content: [Every one know search is use full
It can be done just by a PC or phone.
Platform is very important]
rank: 2, weight: 0.605063, match_ratio: 100%, match_no: 7, doc_id: , doc content: [Every one know search is use full
It can be done just by a PC or phone.
Platform is very important]
rank: 3, weight: 0.605063, match_ratio: 100%, match_no: 9, doc_id: , doc content: [Every one know search is use full
It can be done just by a PC or phone.
Platform is very important]
rank: 4, weight: 0.605063, match_ratio: 100%, match_no: 11, doc_id: doc2, doc content: [Every one know search is use full
It can be done just by a PC or phone.
Platform is very important]
rank: 5, weight: 0.605063, match_ratio: 100%, match_no: 13, doc_id: doc2, doc content: [Every one know search is use full
It can be done just by a PC or phone.
Platform is very important]
rank: 6, weight: 0.605063, match_ratio: 100%, match_no: 15, doc_id: doc2, doc content: [Every one know search is use full
It can be done just by a PC or phone.
Platform is very important]
rank: 7, weight: 0.605063, match_ratio: 100%, match_no: 17, doc_id: doc2, doc content: [Every one know search is use full
It can be done just by a PC or phone.
Platform is very important]
rank: 8, weight: 0.605063, match_ratio: 100%, match_no: 19, doc_id: doc2, doc content: [Every one know search is use full
It can be done just by a PC or phone.
Platform is very important]
源码
xiapian_starter文章来源地址https://www.toymoban.com/news/detail-525626.html
到了这里,关于C++开源搜索引擎xapian开发入门的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!