Linux搭建ELK日志收集系统构建:Filebeat+Redis+Logstash+Elasticse
一、ELK概述:
ELK是一组开源软件的简称,其包括Elasticsearch、Logstash 和 Kibana。ELK最近几年发展迅速,已经成为目前最流行的集中式日志解决方案。
Elasticsearch: 能对大容量的数据进行接近实时的存储,搜索和分析操作。 本项目中主要通过Elasticsearch存储所有获取的日志。
Logstash: 数据收集引擎,它支持动态的的从各种数据源获取数据,并对数据进行过滤,分析,丰富,统一格式等操作,然后存储到用户指定的位置。
Kibana: 数据分析与可视化平台,对Elasticsearch存储的数据进行可视化分析,通过表格的形式展现出来。
Filebeat: 轻量级的开源日志文件数据搜集器。通常在需要采集数据的客户端安装Filebeat,并指定目录与日志格式,Filebeat就能快速收集数据,并发送给logstash进行解析,或是直接发给Elasticsearch存储。
Redis:NoSQL数据库(key-value),也数据轻型消息队列,不仅可以对高并发日志进行削峰还可以对整个架构进行解耦。
二、新型ELK框架

三、部署过程
1、客户端安装filebeat
早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计。
Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash进行索引。
(2)filebeat的工作原理
启动Filebeat时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。对于Filebeat所找到的每个日志,Filebeat都会启动收集器。每个收集器都读取单个日志以获取新内容,并将新日志数据发送到libbeat,libbeat将聚集事件,并将聚集的数据发送到为Filebeat配置的输出。
工作流程图如下。

从图中所示,filebeat结构:由两个组件构成,分别是inputs(输入)和harvesters(收集器),这些组件一起工作来跟踪文件并将事件数据发送到您指定的输出,harvester负责读取单个文件的内容。harvester逐行读取每个文件,并将内容发送到输出。为每个文件启动一个harvester。harvester负责打开和关闭文件,这意味着文件描述符在harvester运行时保持打开状态。如果在收集文件时删除或重命名文件,Filebeat将继续读取该文件。这样做的副作用是,磁盘上的空间一直保留到harvester关闭。默认情况下,Filebeat保持文件打开,直到达到close_inactive。
关闭harvester可以会产生的结果:
文件处理程序关闭,如果harvester仍在读取文件时被删除,则释放底层资源。
只有在scan_frequency结束之后,才会再次启动文件的收集。
如果该文件在harvester关闭时被移动或删除,该文件的收集将不会继续。
(3)filebeat的安装
通过wget获取filebeat的tar.gz包。
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.6.2-linux-x86_64.tar.gz
命令执行结果如下。

在/home目录下建立filebeat目录,然后把filebeat的压缩包解压到目录filebeat下。

解压后,在/usr/filebeat的对应版本filebeat目录下,编辑file--beat.yml文件。
修改的内容有加几个字段。
enabled:true
paths:程序日志路径
output.redis:日志输出地方
hosts:redis所在服务器IP
port:redis端口
key:redis中的key
①filebeat.input中的enabled改为true
②注意input的paths:-/var/log/*.log,其目的监控var中的log日志。
③将output.elasticsearch内容注释。将输出内容输出到redis中,redis数据的key值是filebeat,输出参数中的db是写入redis数据库中是哪一个库。
内容如下。

接下来停止防火墙。
systemctl disable firewalld.service
systemctl stop firewalld.service

再关闭selinux。
进入到etc,再进入到selinux目录下,编辑config文件,注释掉SELINUX相关内容。

2、安装redis
yum install -y redis

安装成功后,如下图。

然后,进入etc目录下,编辑redis.conf文件。

将地址绑定设定为0.0.0.0,即任何地址IP都可以登录redis。

启动filebeat。
在filebeat的目录下执行:
./filebeat -e -c filebeat.yml
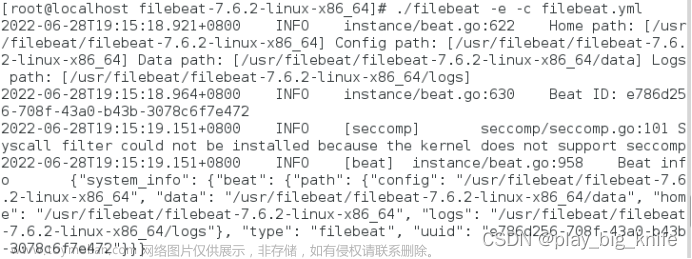
然后启动redis,主要是查看filebeat的log数据是否被redis接收。

redis-cli进入redis 的命令行方式。

进入redis查看是否有数据
keys *可以看看所有key,此操作为慢查询,若redis跑了大量线上业务请不要进行此操作。

lrange filebeat 0 -1 查询key所有的数据,若filebeat启动时间过长请勿进行此操作。

3、安装jdk
首先在/usr中创建目录java。如下图所示。

然后在/home/soft目录下将jdk的tar包解压到/usr的java目录下。

在/etc目录下编辑profile文件,设置环境变量。

接下来,source一下profile文件,使设置生效。

4、安装elasticsearch
在/home/soft 目录下拷贝elasticsearch文件夹,将文件夹拷贝到/usr目录下并重命名elasticsearch。

因为root用户不能启动,所以需要创建一个ES用户。
创建用户使用
useradd es
如下图。

给用户添加密码使用
passwd es
如下图。

给用户授权。
chown -R es:es elasticsearch

接下来切换用户。
su es

在elasticsearch目录下编辑文件elasticsearch.yml
将xpack.security.enabled和xpack.security.http.ssl设为false
如下图。
#ES监听地址任意IP都可访问
network.host: 0.0.0.0
http.port: 9200
#若是集群,可在里面引号中添加,逗号隔开
discovery.zen.ping.unicast.hosts: [“192.168.3.205”]
# enable cors,保证_site类的插件可以访问es
http.cors.enabled: true #手动添加
http.cors.allow-origin: “*” #手动添加
进入elasticsearch的文件夹,启动elasticsearch,需要注意的是启动elasticsearch需要注意bin下面elasticsearch文件的执行权限。
两点:
(1)切换到es用户。su es
(2)为elasticsearch添加执行权限
Chmod +X elasticsearch

接下来,启动elasticsearch就可以启动elasticsearch程序了。

不过启动时,报错。

其原因在于虚拟机内存太小。需要设置etc下的文件sysctl.conf文件。

在文件的最后一行添加内容,vm.maxmapcount=262144
设置虚拟机内存的大小后,再次重启机器,启动./elasticsearch,最终启动elasticsearch的结果如下图所示。
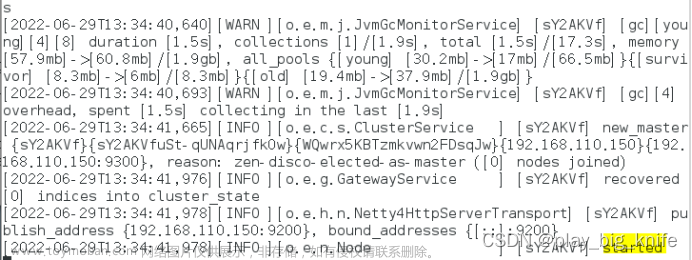
至此,elasticsearch已启动成功。
5、安装logstash
首先在usr的目录下建立文件夹logstash

把home目录下soft目录下的logstash的压缩包解压到/usr/logstash目录下。

解压后可以测试logstash,测试脚本如下。
logstash -e “input {stdin{}} output {stdout{}}”
Stdin是基本的输入,stdout是基本的输出。
注意,logstash也需要jdk8.0的支持。在centos中的logstash目录的bin目录下,执行./logstash。执行测试指令如下。

此时输入任何一个语句,输出当前时间及后面的语句。如下图。

这里可以将输出限定为指定的格式。
logstash -e “iniput{stdin{}} output {stdout{codec=>rubydebug}}”
这里的输出code=>rubydebug指出了一种特定的输出格式。
如下图所示。

从图中所示,logstash已经显示Successfully started,表示logstash已经启动成功。
输入”this is a book”,输出会有一定的格式,如下图所示。

设定logstash的输入为Redis,输出为ES,将此设置存储成文件,文件内容如下。
input{
redis{
port=>”6379”
host=>”192.168.110.150”,
data_type=>”list”,
type=>”log”,
key=>”filebeat”
}
}
output{
elasticsearch{
host=>”192.168.110.150:9200”
index=>”logstash1-%{+YYYY.MM.dd}”
}
}
logstash加载文件可以通过-f来实现。具体执行指令如下。

最终显示started,如下图所示。

6、检查redis中的keys值,是否被logstash取走。
打开终端,进入redis-cli,在命令行中输入keys *,可以查看log日志是否被logstash取走。如下图所示。

可以发现,redis终端中的“filebeat”键已经被logstash取走。
7、验证ES是否接收到数据。
使用curl指令查看ES中是否已接收到数据。
curl http://192.168.110.150:9200/_search?pretty
如下图所示。

从结果上看,logstash已经把数据推送到ES中。
8、安装node.
安装node是安装elasticsearch-head的前提条件。
安装node可以使用yum install -y nodejs,如下图。

安装后,可以使用node -v查看安装是否成功。

安装nodejs后,安装npm
yum install -y npm

安装后,可以验证npm的版本号
npm -v

9、安装elasticsearch-head插件
进入home/soft中的elasticsearch-head-master的文件夹。

然后执行npm install方法,安装elasticsearch-head插件。
安装结束后,npm run start启动elasticsearch-head的服务。
10、安装kibana
解压目录文件,把home/soft目录中的kibana压缩文件解压到/usr的kibana目录下。

解压成功后,在usr/kibana目录下有一个文件kibana-5.3.1-x86_64,在其目录下有一个配置目录config。编辑其下面的配置文件kibana.yml。
在kabana.yml打开一些配置前的#号,并修改内容如下。



注意配置文件中,每个“:”号后面有空格。
最后启动kibana服务,进入到/usr/kibana目录下,再进入kibana-5.3.1-linux-x86_64,再进入bin目录中,使用./kibana命令,启动kibana。

访问http://192.168.110.150:5601,出现kibaba的界面如下。
过一阵,kibana页面发生变化。如下图所示。

在Index name or pattern中输入与ES中索引相匹配的ES数据。同时选择Time-fileld-name,Time-field-name会存在默认项。点击“create”进入下一项。

通过地址http://192.168.110.150:5601/status可以查看kibana的运行情况。

正常情况下,点击Discover可以显示具体的图像。

异常情况如下图。
 文章来源:https://www.toymoban.com/news/detail-527581.html
文章来源:https://www.toymoban.com/news/detail-527581.html
至此,设置结束。 文章来源地址https://www.toymoban.com/news/detail-527581.html
到了这里,关于Linux搭建ELK日志收集系统构建:Filebeat+Redis+Logstash+Elasticse的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![搭建EFK(Elasticsearch+Filebeat+Kibana)日志收集系统[windows]](https://imgs.yssmx.com/Uploads/2024/02/475312-1.png)