分区的分配以及再平衡

1、kafka有四种主流的分区策略:Range,RoundRobin,Sticky,CooperativeSticky。可以通过配置参数partition.assignment.strategy,修改分区的分配策略。默认策略是Ranage+CooperativeSticky。Kafka可以同事使用多个分区分配策略。
| 参数 | 描述 |
|---|---|
| heartbeat.interval.ms | Kafka消费者和coordinator之间的心跳时间,默认3s。该条目的值必须小于session.timeout.ms,也不应该高于session.timeoyt.ms的1/3 |
| session.timeout.ms | Kafka消费者和coordinator之间连接超时时间,默认45s。超过该值,该消费者被移除,消费者执行再平衡 |
| max.poll.interval.ms | 消费者处理消息的最大时长,默认是5分钟,超过该值被移除,消费者执行再平衡 |
| partition.assignment.strategy | 消费者分区分配策略,默认策略是Range+CooperativeStickt。Kafka可以同事使用多个分区分配策略。可以选择策略包括:Range,RoundRobin,sticky,CooperativeSticky |
Range以及再平衡

Range分区策略原理
Range是对每个topic而言
首先对同一个topic里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。
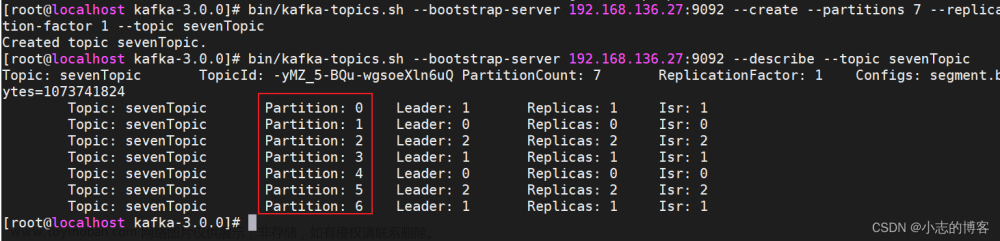
加入现在有7个分区,3个消费者,排序后的分区将会是0,1,2,3,4,5,6消费者排序完之后将会是C0,C1,C2
通过partitions数/consumer数来决定每个消费者应该消费几个分区,如果除不尽,那么前面几个消费者将会多消费一个分区。
例如。7/3=2余1,除不尽,那么消费者C0便会多消费者1个分区。8/3=2余2,除不尽,那么C0和C1分别多消费一个。
注意:如果只是针对一个topic而言,C0消费者多一个分区影响不是很大,但是如果有N个topic,那么针对每个topic,消费者C0都将多消费一个分区,topic越多,C0消费的分区会比其他消费者明显多消费N个分区
容易尝试数据倾斜
测试代码
package com.longer.range;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
/**
* 测试指定分区(partition)
*/
public class Producer {
public static void main(String[] args) throws InterruptedException {
//1、创建kafka生产者得配置对象
Properties properties=new Properties();
//2、给kafka配置对象添加配置信息
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop100:9092");
//3、key value 序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//4、创建kafka生产者对象
KafkaProducer<String,String> producer=new KafkaProducer<String, String>(properties);
for (int i = 0; i < 500; i++) {
//指定数据发送到1号分区,key为空(IDEA中,ctrl+p查看参数)
producer.send(new ProducerRecord<>("two", "longer " + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception e) {
if(e==null){
System.out.println(String.format("主题:%s,分区:%s",metadata.topic(),metadata.partition()));
return;
}
e.printStackTrace();
}
});
Thread.sleep(1000);
}
//关闭资源
producer.close();
}
}
package com.longer.range;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;
public class CustomConsumer1 {
public static void main(String[] args) {
//创建消费者的配置对象
Properties properties=new Properties();
//2、给消费者配置对象添加参数
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop100:9092");
//配置序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
//配置消费者组(组名任意起名)必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");
//创建消费者对象
KafkaConsumer<String,String> kafkaConsumer=new KafkaConsumer<String, String>(properties);
//注册要消费的主题
ArrayList<String> topics=new ArrayList<>();
topics.add("two");
kafkaConsumer.subscribe(topics);
while (true){
//设置1s中消费一批数据
ConsumerRecords<String,String> consumerRecords=kafkaConsumer.poll(Duration.ofSeconds(1));
//打印消费到的数据
for(ConsumerRecord<String,String> record:consumerRecords){
System.out.println(record);
}
}
}
}
用一个消费者每一秒发送一条信息,三个消费者接收。观察打印情况。再停止其中一个消费者,再观察情况。
(1)停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)。
1 号消费者:消费到 3、4 号分区数据。
2 号消费者:消费到 5、6 号分区数据。
0 号消费者的任务会整体被分配到 1 号消费者或者 2 号消费者。
说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需
要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
(2)再次重新发送消息观看结果(45s 以后)。
1 号消费者:消费到 0、1、2、3 号分区数据。
2 号消费者:消费到 4、5、6 号分区数据。
说明:消费者 0 已经被踢出消费者组,所以重新按照 range 方式分配。
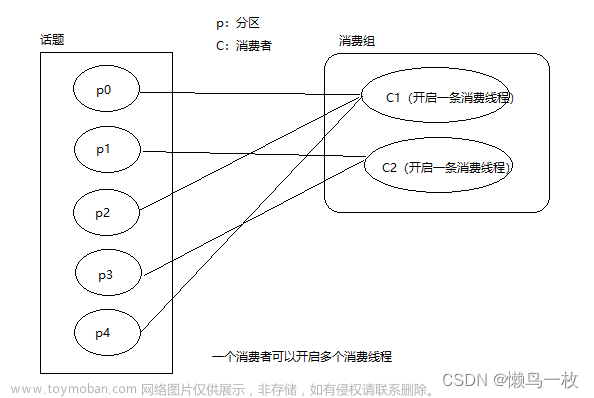
RoundRobin 以及再平衡

RoundRobin针对集群所有Topic而言
RoundRobin沦陷分区策略,是把所有的partition和所有的consumer都列出来,然后按照hashcode而进行排序,最后通过沦陷算法来分配partition给各个消费者。
修改分区策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.RoundRobinAssignor");
测试代码
public class CustomConsumer1 {
public static void main(String[] args) {
//创建消费者的配置对象
Properties properties=new Properties();
//2、给消费者配置对象添加参数
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop100:9092");
//配置序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
//配置消费者组(组名任意起名)必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");
//修改分区策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.RoundRobinAssignor");
//创建消费者对象
KafkaConsumer<String,String> kafkaConsumer=new KafkaConsumer<String, String>(properties);
//注册要消费的主题
ArrayList<String> topics=new ArrayList<>();
topics.add("two");
kafkaConsumer.subscribe(topics);
while (true){
//设置1s中消费一批数据
ConsumerRecords<String,String> consumerRecords=kafkaConsumer.poll(Duration.ofSeconds(1));
//打印消费到的数据
for(ConsumerRecord<String,String> record:consumerRecords){
System.out.println(record);
}
}
}
}
(1)停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)。
1 号消费者:消费到 2、5 号分区数据
2 号消费者:消费到 4、1 号分区数据
0 号消费者的任务会按照 RoundRobin 的方式,把数据轮询分成 0 、6 和 3 号分区数据,
分别由 1 号消费者或者 2 号消费者消费。
说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需
要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
(2)再次重新发送消息观看结果(45s 以后)。
1 号消费者:消费到 0、2、4、6 号分区数据
2 号消费者:消费到 1、3、5 号分区数据
说明:消费者 0 已经被踢出消费者组,所以重新按照 RoundRobin 方式分配。
Sticky 以及再平衡
粘性分区定义:可以理解为分配的结果带有”粘性的“,即再执行一次新的分配之前,考虑上一次分配的结果,尽量少的调整分配变动,可以节省大量的开销。
粘性分区时Kafka从0.11.x版本开始引入这种分配策略,首先会尽量保持原有分配的分区不变化
测试代码
package com.longer.sticky;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;
public class CustomConsumer1 {
public static void main(String[] args) {
//创建消费者的配置对象
Properties properties=new Properties();
//2、给消费者配置对象添加参数
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop100:9092");
//配置序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
//配置消费者组(组名任意起名)必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");
//修改分区策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.StickyAssignor");
//创建消费者对象
KafkaConsumer<String,String> kafkaConsumer=new KafkaConsumer<String, String>(properties);
//注册要消费的主题
ArrayList<String> topics=new ArrayList<>();
topics.add("two");
kafkaConsumer.subscribe(topics);
while (true){
//设置1s中消费一批数据
ConsumerRecords<String,String> consumerRecords=kafkaConsumer.poll(Duration.ofSeconds(1));
//打印消费到的数据
for(ConsumerRecord<String,String> record:consumerRecords){
System.out.println(record);
}
}
}
}
(1)停止掉 0 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)。
1 号消费者:消费到 2、5、3 号分区数据。
2 号消费者:消费到 4、6 号分区数据。
0 号消费者的任务会按照粘性规则,尽可能均衡的随机分成 0 和 1 号分区数据,分别
由 1 号消费者或者 2 号消费者消费。
说明:0 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需
要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行。
(2)再次重新发送消息观看结果(45s 以后)。
1 号消费者:消费到 2、3、5 号分区数据。
2 号消费者:消费到 0、1、4、6 号分区数据。
说明:消费者 0 已经被踢出消费者组,所以重新按照粘性方式分配文章来源:https://www.toymoban.com/news/detail-528969.html
总结
range会造成数据倾斜,RoundRobin不会造成,但是分区调整不会考虑最小变动。sticky,尽量少的调整分配变动,可以节省大量的开销。文章来源地址https://www.toymoban.com/news/detail-528969.html
到了这里,关于Kafka入门,分区的分配再平衡(二十)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!