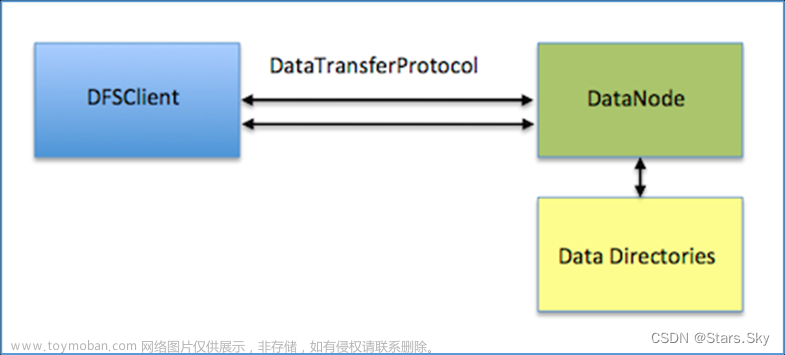
DFSClient和DN在一个节点 —— local reads,远程阅读 Remote reads。 处理方式是一样的
- DN读数据
- 通过RPC(TCP协议)把数据给DFSClient。DN在中间会做中转,处理简单但是性能收影响 (Local read的情况下,会希望绕过DN直接读取Data,这就是 短路
短路本地读取
- DFSClient自行打开文件读取数据,需要配置白名单定义可读取数据的User —— 安全漏洞,不建议使用
- 两个进程socket方式通讯,普通数据甚至是文件描述符传递给B,B读取文件内容({即使B没有权限)
3. A为DN,B为DFSClient,读取文件 安全性稍微好点
负载平衡器 Balancer
让block放信息,在整个DN节点之间平衡数据 (无法在单个DN的各个卷之间平衡
命令
hdfs balancer
设置平衡数据传输带宽
hdfs dfsadmin -setBlancerBandwidth newbandwidth
修改阈值
hdfs balancer -threshold 5
表示阈值为5%,默认10%,每个DN磁盘使用率与cluster总体使用了相差不超过5%。 EXM: 所有DN总体使用率是集群磁盘容量的40%,program要确保每个DN磁盘使用率在这个DN磁盘存储容量的35%到45%之间
磁盘均衡器 HDFS disk balancer
对比个人PC, server可以通过挂在对磁盘扩大单机存储能力
- DN负责数据block存储,在机器上磁盘之间分配数据块。写入新的block的时候,DN根据选择策略选择block磁盘
** 循环策略**:新的block均匀分布在可用磁盘上(默认
可用空间策略: 数据写入有更多空间磁盘(按百分比
如果基于可用空间的策略:新写入会放入空磁盘 —— 其他磁盘idle, 新磁盘有瓶颈 —— 需要intra DataNode Balancing机制解除 DataNode偏斜 —— 磁盘更换, 随机写入 删除发生的
功能
报告、平衡
比较数据在节点不同卷的分布情况:密度允许在节点之间比较 —— 根据used / capcity保存容量,最好保持70%
指令plan
hdfs diskbalancer -plan <datanode>
| -out | 输出位置 |
| -bandwidth | 最大带宽 默认带宽10 MB/s |
| -thresholPercentage | 定义磁盘开始参与数据重新分配或平衡操作的值。默认的thresholdPercentage值为10%,这意味着仅当磁盘包含的数据比理想存储值多10%或更少时,磁盘才用于平衡操作 |
| -maxerror | 它允许用户在中止移动步骤之前为两个磁盘之间的移动操作指定要忽略的错误数。 |
| -v | 详细模式,指定此选项将强制plan命令在stdout上显示计划的摘要。 |
| -fs | 此选项指定要使用的NameNode。如果未指定,则Disk Balancer将使用配置中的默认NameNode。 |
设定好计划后,execute
hdfs diskbalancer -execute <JSON file path>
对DN执行计划
查询
hdfs diskbalancer -query <datanode>
cancel取消计划文章来源:https://www.toymoban.com/news/detail-535970.html
EC 纠删码技术
添加链接描述文章来源地址https://www.toymoban.com/news/detail-535970.html
优化方案
- 动态扩容 —— 原有cluster加新的DN节点
- 缩容,cluster停止某些机器的HDFS服务
到了这里,关于hadoop生态圈-- 个人笔记学习05 HDFS优化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!