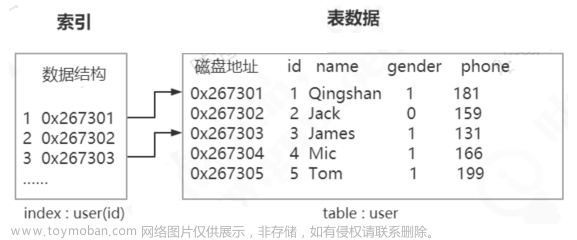
1. 全表遍历
- 将磁盘中存储的所有数据记录依次加载,与给定条件对比,直到找到目标记录;
- 类比数组结构的线性查找,效率较低;
2. 哈希结构
- 结合数组和链表结构(或者树结构)存储数据;
- 通过哈希函数(散列函数)计算哈希地址,相同输入在固定函数下输出保持不变;
- 哈希结构会发生哈希冲突,使用哈希桶或者红黑树可缓解哈希冲突;
- 哈希结构查找效率较高,为O(1);
- InnoDB和MyISAM存储引擎均不支持哈希索引,而Memory存储引擎支持哈希索引;
2.1 使用哈希结构创建索引的缺点
- 哈希索引可满足等值查询(==、!=、IN),对于范围查询,效率较低;
- 哈希索引下数据存储无序,对于排序查询效率较低;
- 对于联合索引,哈希索引将多个列结合进行哈希计算,因此对于单独的列无法进行查询;
- 哈希索引容易发生哈希冲突,此时查找效率降低;
2.2 哈希索引的适用性
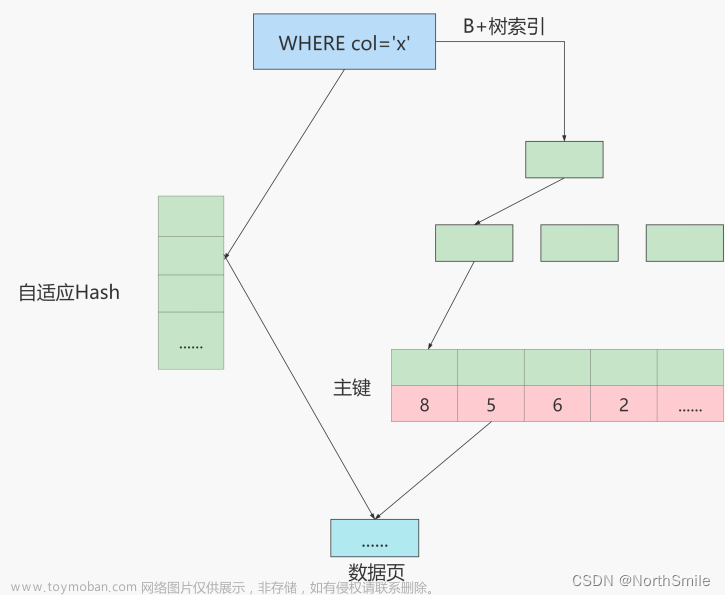
- InnoDB存储引擎不支持哈希索引,但提供了自适应哈希索引(Adaptive Hash Index)提高数据检索效率;
- 可通过
show variables like '%adaptive_hash_index';查看MySQL是否开启了自适应哈希索引; - 自适应哈希索引(Adaptive Hash Index):如果某个数据页被频繁访问,则当满足一定条件时将该数据页对应地址存储在哈希表中,如此下次访问该数据页时可直接由哈希表中的地址获取,而不用在B+树中检索;
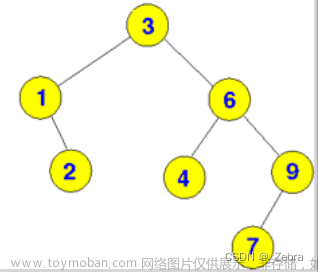
3. 二叉搜索树
- 本质是二叉树;
- 限制条件:左<根<右,即任意一颗子树,其根节点的值大于左子树所有节点的值,同时小于右子树所有节点的值;
- 二叉搜索树一般查找效率较高,时间复杂度为O(log2n);

- 缺点:极端情况下会退化为单链表,查找效率降低;

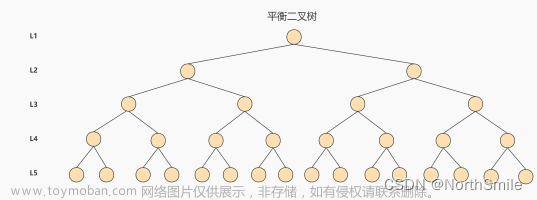
4. AVL树
- AVL树即平衡二叉搜索树;
- 限制条件:二叉搜索树的任意子树的左右子树高度差绝对值不能超过1;
- 优点:解决了二叉搜索树退化为单链表的问题;
- 缺点:虽然二叉树实现简单,但如果数据量巨大,会导致二叉树高度过大,查找效率降低;
5. B树
- 本质是多叉平衡搜索树,可解决AVL树高度过高的问题,提高查找效率;
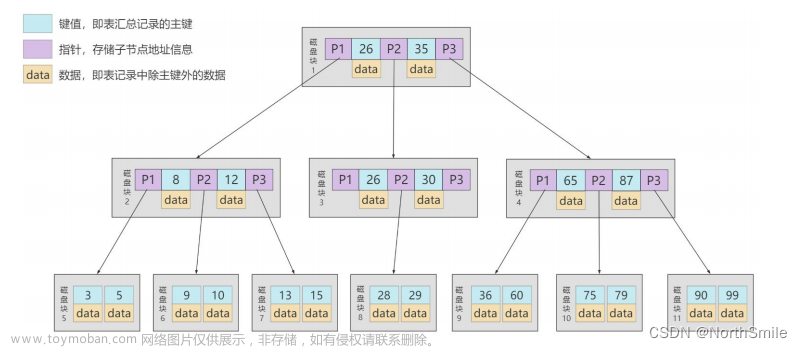
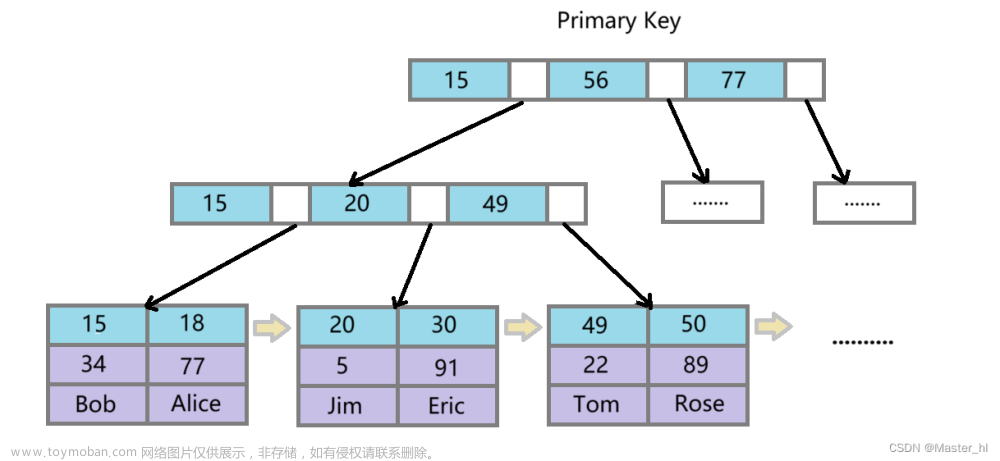
6. B+树
- 本质是多叉平衡搜索树,基于B树做了一定改进,更适合于文件索引系统;
- B+树非叶节点中不存储真实数据,只存储索引;
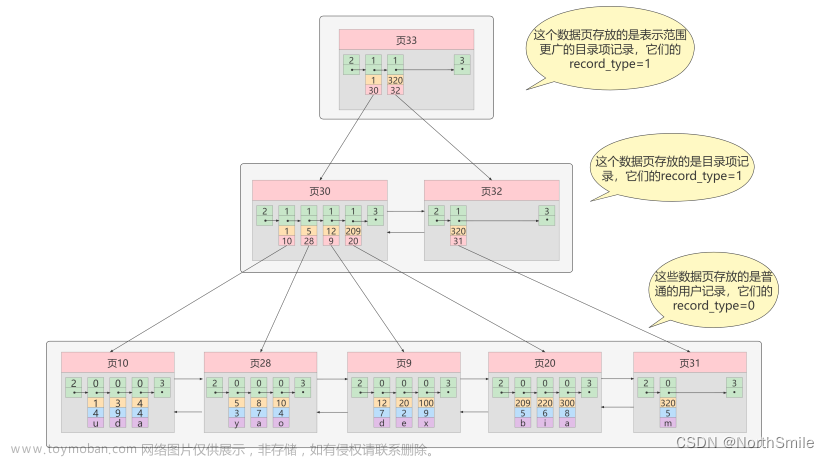
6.1 B+ 树和 B 树的差异
- 有 k 个孩子的节点就有 k 个关键字。也就是孩子数量 = 关键字数,而 B 树中,孩子数量 = 关键字数
+1; - 非叶子节点的关键字也会同时存在在子节点中,并且是在子节点中所有关键字的最大(或最小);
- 非叶子节点仅用于索引,不保存数据记录,跟记录有关的信息都放在叶子节点中。而 B 树中, 非
叶子节点既保存索引,也保存数据记录; - 所有关键字都在叶子节点出现,叶子节点构成一个有序链表,而且叶子节点本身按照关键字的大小从小到大顺序链接;
6.2 采用B+树创建索引的优势
- B+树的内节点不存储真实数据记录,而B树内节点会存储部分真实数据;
- B+树查询效率更加稳定;
- B+树高度更低,查询效率更高;
- 对于范围查询,B+树只有叶子结点存储有序的真实数据,因此查询效率更高;
6.3 一些需要注意的问题
1)为了减少IO,索引树会一次性加载吗?
- 如果数据表存储的数据量非常大,则对应的索引文件可能也会很大,如果一次性加载到内存,对于内存要求较高;
- 实际情况下,对于索引文件的加载是逐一进行的;
2)B+树的存储能力如何?为何说一般查找行记录,最多只需1~3次磁盘IO?
- B+树为多叉平衡搜索树,每个节点对应一个真实数据页,每个数据页默认大小为16KB;
- 主键类型一般采用INT(4B)或BIGINT(8B),指针类型一般也占据4B或8B ,最大情况下一个数据页可以存储16KB/(8B+8B)≈1000条记录;
- 对于目录项记录页,每个数据页假设可存储1000条记录,则当B+树高度为3时,可存储约109条记录,数据量非常庞大;
- 实际情况中,B+树上面三层可能不会完全填充,因此实际B+树一般设计为2~4层,也就是磁盘I/O次数为2~4次。但InnoDB存储引擎设计时将根节点常驻在内存,所以实际磁盘I/O次数为1~3次;
3)为什么说B+树比B-树更适合实际应用中操作系统的文件索引和数据库索引?
B+树只有叶子结点存储真实数据,查询效率更高更稳定,磁盘占用更少;
4)Hash 索引与 B+ 树索引的区别?
- InnoDB存储引擎不支持Hash索引;
- Hash索引数据存储无序,不支持ORDER BY排序,也不支持模糊查询;
- Hash索引数据存储无序,不能进行范围查询;
- Hash索引不支持联合索引的最左侧原则,即联合索引的部分索引无法使用;
5)Hash 索引与 B+ 树索引是在建索引的时候手动指定的吗?文章来源:https://www.toymoban.com/news/detail-536530.html
- InnoDB、MyISAM存储引擎不支持Hash索引,对于InnoDB提供的自适应哈希索引默认开启,不需要手动指定;
- Memory存储引擎默认采用Hash索引;
参考《尚硅谷》文章来源地址https://www.toymoban.com/news/detail-536530.html
到了这里,关于MySQL为什么选择B+树创建索引的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!