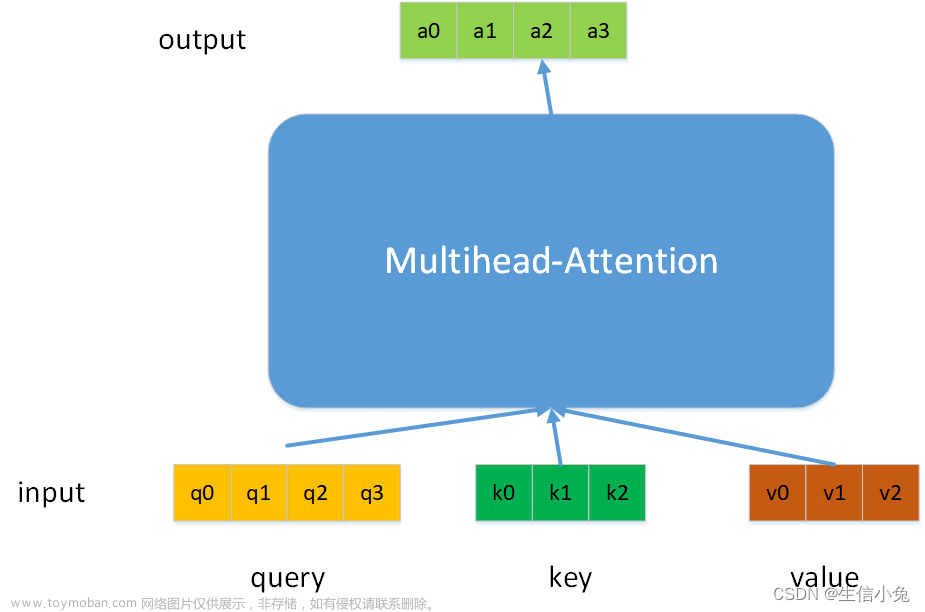
😄 额,本想学学XLNet的,然后XLNet又是以transformer-XL为主要结构,然后transformer-XL做了两个改进:一个是结构上做了segment-level的循环机制,一个是在attention机制里引入了相对位置编码信息来避免不同segment的同一位置采用相同的绝对位置编码的不合理。但无奈看到相对位置编码这里我懵住了,只好乖乖追溯回去原始论文来学习学习嘿嘿🐶。
🦄 本文将以公式原理+举例的方式让你秒懂,放心食用。
🚀 RPR这论文就5页,方法部分就2页,看完结合网上理解下就ok了。
🚀 论文链接:https://arxiv.org/pdf/1803.02155.pdf文章来源:https://www.toymoban.com/news/detail-581928.html
👀 三位谷歌大佬的作品: 文章来源地址https://www.toymoban.com/news/detail-581928.html
文章来源地址https://www.toymoban.com/news/detail-581928.html
🚀 导航
| ID | 内容 |
|---|---|
| NO.1 | 1、简单背景介绍+提出动机 |
| NO.2 |
到了这里,关于相对位置编码之RPR式:《Self-Attention with Relative Position Representations》论文笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!