nested
嵌套类型
数据的某个值是json、object对象;不再是简单的数据类型,或者简单数据类型的数组;那么还用之前的查询方式就有问题了。因为ES在存储复杂类型的时候会把对象的复杂层次结果扁平化为一个键值对列表 。此时,需要用nested进行查询
扁平化存储

用法
使用nested查询的时候,在设置mapping的时候,也要指定字段类型为nested
PUT <index_name>
{
"mappings": {
"properties": {
"<nested_field_name>": {
"type": "nested"
}
}
}
}查询
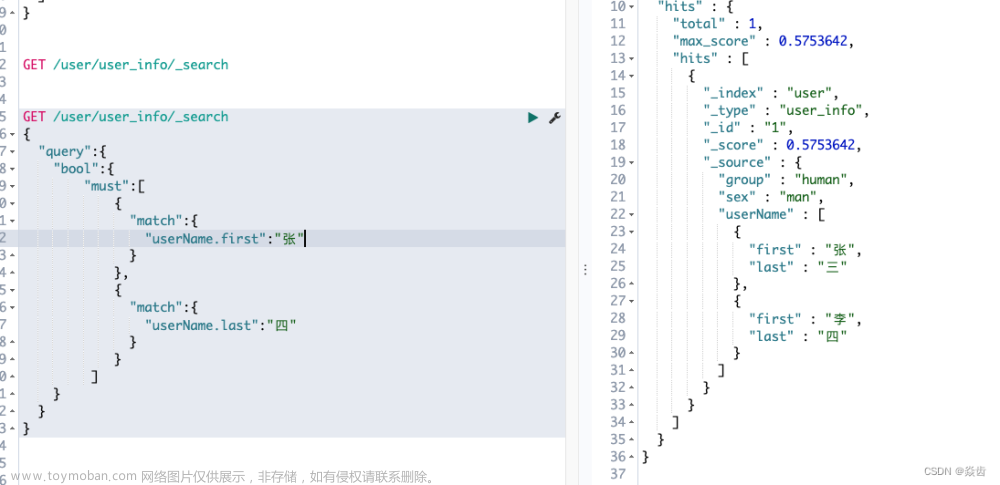
GET /my-index-000001/_search
{
"query": {
"nested": {
"path": "obj1",
"query": {
"bool": {
"must": [
{ "match": { "obj1.name": "blue" } },
{ "range": { "obj1.count": { "gt": 5 } } }
]
}
},
"score_mode": "avg"
}
}
}
path:nested对象的查询深度
score_mode:评分计算方式
avg (默认):使用所有匹配的子对象的平均相关性得分。
max:使用所有匹配的子对象中的最高相关性得分。
min:使用所有匹配的子对象中最低的相关性得分。
none:不要使用匹配的子对象的相关性分数。该查询为父文档分配得分为0。
sum:将所有匹配的子对象的相关性得分相加。
Join
父子级关系
join和nested一样,需要在设置mapping的时候,设置字段类型
mapping
PUT msb_depart
{
"mappings": {
"properties": {
"msb_join_field": {
"type": "join",
"relations": {
"depart": "employee"
}
},
"my_id": {
"type": "keyword"
}
}
}
}插入父级数据
PUT msb_depart/_doc/1
{
"my_id": 1,
"name":"教学部",
"msb_join_field":{
"name":"depart"
}
}
PUT msb_depart/_doc/2
{
"my_id": 2,
"name":"咨询部",
"msb_join_field":{
"name":"depart"
}
}连接数据类型是一个特殊字段,它在同一索引的文档中创建父/子关系。关系部分在文档中定义了一组可能的关系,每个关系是一个父名和一个子名
插入子级数据需要指定routing路由,因为父文档和子文档必须在同一个分片建立索引
插入子级数据
PUT msb_depart/_doc/3?routing=1&refresh
{
"my_id": 3,
"name":"马老师",
"msb_join_field":{
"name":"employee",
"parent":1
}
}
PUT msb_depart/_doc/4?routing=1&refresh
{
"my_id": 4,
"name":"周老师",
"msb_join_field":{
"name":"employee",
"parent":1
}
}搜索所有父级数据
GET msb_depart/_search
{
"query": {
"has_child": {
"type": "employee",
"query": {
"match_all": {}
}
}
}
}搜索所有子级
{
"query": {
"has_parent": {
"parent_type": "depart",
"query": {
"match": {
"name.keyword": "咨询部"
}
}
}
}
}join类型不能像关系数据库中的表链接那样去用,不论是has_child或者是has_parent查询都会对索引的查询性能有严重的负面影响。并且会触发global ordinals
join唯一合适应用场景是:当索引数据包含一对多的关系,并且其中一个实体的数量远远超过另一个的时候。
关联关系处理优先级
Object>nested>join
Object类型
通俗点就是通过字段冗余,以一张大宽表来实现粗粒度的index,这样可以充分发挥扁平化的优势。但是这是以牺牲索引性能及灵活度为代价的。
使用的前提:冗余的字段应该是很少改变的;比较适合与一对少量关系的处理。
当业务数据库并非采用非规范化设计时,这时要将数据同步到作为二级索引库的ES中,就很难使用上述增量同步方案,必须进行定制化开发,基于特定业务进行应用开发来处理join关联和实体拼接
嵌套对象
索引性能和查询性能二者不可兼得,必须进行取舍。嵌套文档将实体关系嵌套组合在单文档内部(类似与json的一对多层级结构)
这种方式牺牲索引性能(文档内任一属性变化都需要重新索引该文档)来换取查询性能,可以同时返回关系实体,比较适合于一对少量的关系处理。当使用嵌套文档时,使用通用的查询方式是无法访问到的,必须使用合适的查询方式(nested query、nested filter、nested facet等),很多场景下,使用嵌套文档的复杂度在于索引阶段对关联关系的组织拼装
父子级关系
父子文档牺牲了一定的查询性能来换取索引性能,适用于一对多的关系处理。其通过两种type的文档来表示父子实体,父子文档的索引是独立的。父-子文档ID映射存储在 Doc Values 中。当映射完全在内存中时, Doc Values 提供对映射的快速处理能力,另一方面当映射非常大时,可以通过溢出到磁盘提供足够的扩展能力。 在查询parent-child替代方案时,发现了一种filter-terms的语法,要求某一字段里有关联实体的ID列表。基本的原理是在terms的时候,对于多项取值,如果在另外的index或者type里已知主键id的情况下,某一字段有这些值,可以直接嵌套查询。文章来源:https://www.toymoban.com/news/detail-593513.html
具体可参考官方文档的示例:通过用户里的粉丝关系,微博和用户的关系,来查询某个用户的粉丝发表的微博列表。文章来源地址https://www.toymoban.com/news/detail-593513.html
到了这里,关于Elasticsearch--查询(nested、join)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!