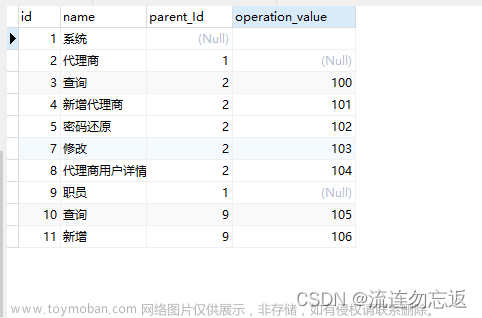
ClickHouse的优化需要结合实际的数据特点和查询场景,从多个方面进行综合优化,以提高系统的性能和可靠性。
数据模型设计:在使用ClickHouse之前,需要充分考虑数据模型的设计,因为数据模型的设计对查询性能有很大的影响。通常来说,ClickHouse适合存储大量的、高维度的、宽表格式的数据,尽量避免使用嵌套数据结构和频繁的JOIN操作。
数据预处理:在数据写入ClickHouse之前,需要对数据进行预处理,包括去重、数据清洗、数据格式转换等操作。同时,在进行批量写入时,可以使用管道插入方式(pipeline insert)和批量写入方式(bulk insert)来提高写入性能。
索引设计:ClickHouse的索引方式与传统的B树索引不同,它采用了基于跳表的LSM-tree索引和Bloom Filter过滤器。为了提高查询性能,需要针对实际的查询场景进行索引的设计,尽量避免使用不必要的索引,以减少数据写入和查询时的开销。
配置优化:ClickHouse的性能和可靠性受到配置参数的影响,需要根据实际的硬件环境和数据规模进行调优。例如,可以调整缓存大小、线程池大小、并发度等参数,以最大限度地利用系统资源和提高查询性能。
查询优化:在进行查询时,需要注意避免全表扫描和跨分区查询等操作,可以通过预聚合、分区剪枝、数据分片等方式来优化查询。同时,ClickHouse提供了多种查询优化工具和语法,例如对于多表查询可以使用查询优化器(query optimizer)来提高查询性能。
总之,ClickHouse的优化需要结合实际的数据特点和查询场景,从多个方面进行综合优化,以提高系统的性能和可靠性。
建表方面的优化:
1.使用最小的数据类型:在定义列时,应尽可能使用最小的数据类型。例如,使用UInt8而不是UInt64,可以降低内存使用和提高查询速度。
2.使用分区:将表按照时间或其他相关维度进行分区,可以提高查询速度和降低查询成本。分区可以使得查询只需要扫描部分数据而不是整个表。
3.选择合适的引擎:ClickHouse 支持多种存储引擎,如 MergeTree、ReplacingMergeTree、SummingMergeTree 等。不同的引擎适用于不同的场景,根据数据的读写特性选择合适的引擎可以提高性能。
4.使用压缩:ClickHouse 支持对数据进行压缩存储,可以降低磁盘和网络的 IO 成本,并提高查询速度。
5.分片:选择数据粒度细的列分片。可以将数据均匀的分布在集群节点中,可以将查询任务分配给多台机器进行分布式查询
6.索引:数据重复率少的,查询频率高的在前
7.不使用nullable:每个列字段会被存储在一个.bin中,如果声明为nullable则需要单独建一个.NULL.BIN文件来保存null值,意味着读写会多出一倍的额外操作
8.在建表时,可以通过设置 max_rows_to_group_by 和 group_by_overflow_mode 参数来预分配空间,以避免数据写入时频繁进行内存分配。
9.合理设置 TTL:如果数据具有时效性,可以设置 TTL 参数来自动删除过期数据,以避免数据占用过多存储空间。
10.调整查询并发度:ClickHouse 支持调整查询并发度,可以通过调整 max_threads 参数来提高查询速度。当查询较慢时,可以适当增加并发度来提高查询速度。
11.使用预编译查询:ClickHouse 支持预编译查询,可以将查询语句缓存起来,避免重复编译查询语句,从而提高查询速度。文章来源:https://www.toymoban.com/news/detail-594224.html
查询优化:
1.select:1)不使用select * 2)指定分区 3)预计算 4)拒绝子查询
2.where 1)谓词下推(把外层的查询条件移到内层,比如把分区从外层下推到内层) 2)prewhere(开启prewhere后,只有prewhere中的列会被全部读取,其余列只会读取prewhere表达式中=true的部分)
3.join查询 1)左大右小(在join的时候右表会被全部加载到内存中和左表比较) 2)谓词下推 3)避免多表join 4)global join (global关键字可以使右表只在接收查询请求的那个节点查询一次,将其分发到其他节点上,如果不加的话每个节点都会请求一次,造成很大的开销)文章来源地址https://www.toymoban.com/news/detail-594224.html
到了这里,关于大数据场景下clickhouse查询时长优化sop的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![java八股文面试[数据库]——慢查询优化](https://imgs.yssmx.com/Uploads/2024/02/684602-1.png)