Kafka简介
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。架构特点是分区、多副本、多生产者、多订阅者,性能特点主要是高吞吐,低时延。
Kafka主要设计特征如下:
-
通过时间复杂度为O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
-
高吞吐量 :即使是非常普通的硬件机器,Kafka也可以支持每秒数百万的消息。
-
支持Kafka 服务间的消息分区,及分布式消费,同时保证每个分区内的消息顺序传输。
-
同时支持离线数据处理和实时数据处理。
-
支持数据水平扩展和副本备份
-
Kafka集群按照主题分类管理,一个主题可以有多个分区,一个分区可以有多个副本分区(分区的容灾手段)
Kafka的消息传递模型使用的是发布-订阅模块,对于消息的消费使用的是消费者主动拉取模型,并不像rocketmq、rabbitmq等主流消息中间件提供服务端推送消息服务。如果要实现类似于推送的效果,只能通过消费者轮询的方式。
Kafka主要有如下几个核心API:
-
Admin API 主要用于管理和检查Topics, brokers和其他kafka对象
-
Producer API:发布消息、事件流到一个或多个kafka主题
-
Consumer API:订阅一个或多个kafka主题,处理producer api发布的事件流消息
-
Streams API:kafka通过流api来实现流处理应用程序和微服务。它提供了处理事件流的高级功能,包括转换、聚合和连接等有状态操作、窗口化、基于事件时间的处理等等。从一个或多个主题中读取输入,以便生成到一个或多个主题的输出,有效地将输入流转换为输出流。
-
Connector API:kafka连接api来构建和运行可重用的数据导入/导出连接器,这些连接器使用(读取)或产生(写)来自外部系统和应用程序的事件流,以便它们可以与kafka集成。例如,像postgresql这样的关系数据库的连接器可能会捕获对一组表的所有更改。然而,在实践中,您通常不需要实现您自己的连接器,因为kafka社区已经提供了数百个现成的连接器。
Kafka优势
-
高吞吐:单机每秒吞吐几十上百万消息
-
高性能:单节点支持上千个客户端,并保证零停机和零数据丢失
-
数据持久化存储:通过将消息持久化到硬盘以及分区副本备份机制防止数据丢失
-
支持分布式水平扩容,集群副本化容灾部署。Producer、Broker和Consumer均支持集群化
-
可靠性:通过主题分区扩容,副本容灾,集群化等手段提供高可靠性
-
客户端状态维护:消息被处理的状态是在Consumer端维护,而不是由server端维护。当失败时能自动平衡
-
提供多种语言的客户端sdk。Kafka支持Java、.NET、PHP、Python等多种语言
Kafka应用场景
Kafka主要应用场景:日志收集系统、消息队列系统、用户活动跟踪等。
-
日志收集:用于收集各种服务的日志
-
消息系统:用于解耦生产者、消费者,缓存消息等场景,
-
用户活动跟踪:如对用户在网站的搜索、点击等行为的实时监控分析
-
运营指标:用于记录运营监控数据
-
流式处理:构建实时的流数据处理程序来转换或处理数据流
Kafka基础架构与核心概念

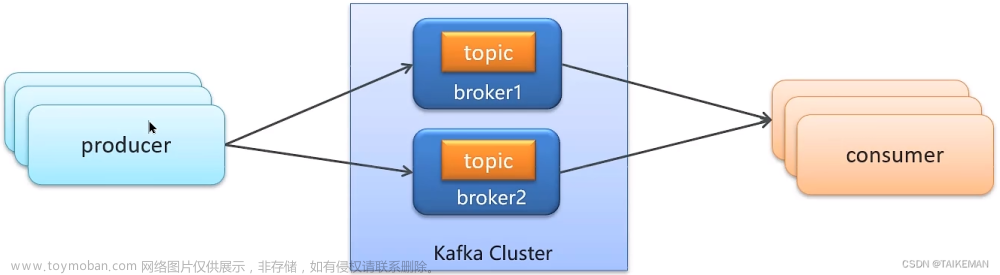
根据如上基础架构图,大致可以看出kafka有如下架构特点:
-
多生产者
-
基于主题对消息进行分类
-
一个主题支持多个分区(数据的水平扩容),分区的容灾是基于Kraft(kafka2.8后不再依赖zookeeper,上图是未引入kraft协议的架构图)数据一致性协议的多副本机制,分Leader副本和Follwer副本
-
多个broker,不同broker可存储不同的分区和分区副本
-
消费者按组进行消费,在同一个消费组内,一个分区消息只能被一个消费者消费,因此对于同一消费组的某个消费者来说,它的消息是有序的,但对于不同消费者来说,它们之间的消息不能做到有序。需要严格顺序的情况下只能设置一个分区来解决。
消息和批次
Kafka的数据单元称为消息,可以把消息看成是数据库里的一条“记录”。消息主要由消息头、主题、分区、键、值、消息偏移量等信息组成,为提高效率,消息通常是分批写入Kafka,批次就是一组消息,这些消息属于同一个主题和分区。同一批次的消息可以进行压缩以提升网络传输能力,批次越大,消息越多,单次网络传输时间越长,但比起小批次消息来说还是减少了网络开销,因为大批次消息需要传输的次数更少。
主题(Topic)和分区(Partition)
Kafka的消息通过主题进行分类。主题可以被分为若干分区,一个主题通过分区分布于Kafka集群中,提供了横向扩展的能力。主题跟分区,用关系型数据库来类比 的话就是表和数据分片,其本质是一样的,都是存储数据和数据扩容的一种方式。

副本(Replicas)
Kafka 使用主题来组织数据,每个主题被分为若干个分区,每个分区有多个副本。那些副本被保存在broker 上,每个broker 可以保存成百上千个属于不同主题和分区的副本。
副本有两种角色,Leader和Follwer,数据一致性基于Raft协议。master的选举、数据的复制参考raft协议即可。
AR(Assigned Repllicas)
分区中的所有副本统称为AR(Assigned Repllicas)。
ISR(In-Sync Replicas)
所有与leader副本保持一定程度同步的副本(包括Leader)组成ISR(In-Sync Replicas),ISR集合是AR集合中的一个子集。消息会先发送到leader副本,然后follower副本才能从leader副本中拉取消息进行同步,同步期间内follower副本相对于leader副本而言会有一定程度的滞后。
OSR(Out-Sync Relipcas)
与leader副本同步滞后过多的副本(不包括leader)副本,组成OSR(Out-Sync Relipcas)。
AR=ISR+OSR(通常为空)
High Watermak
HW是High Watermak的缩写, 俗称高水位,它表示了一个特定消息的偏移量(offset),消费之只能拉取到这个offset之前的消息。
LEO
LEO是Log End Offset的缩写,它表示了当前日志文件中下一条待写入消息的offset。
生产者(Producer)和消费者(Consumer)
生产者(Producer):向主题发布消息。生产者默认情况下把消息均衡地分布到主题的所有分区上,策略有轮询指定分区、消息key hash值对分区数取模,指定分区。
消费者Consumer):订阅主题消息,消费者通过偏移量来区分已经读过的消息。
消费者群组:一个主题可以有多个分区,一个分区可以被不同的消费者群组消费,但一个分区在同一消费者群组内只能被一个消费者消费(避免重复消费)。群组消费可以加强消费能力,避免消息过度堆积,但同时带来了无法做到严格有序消费问题。
 文章来源:https://www.toymoban.com/news/detail-607899.html
文章来源:https://www.toymoban.com/news/detail-607899.html
broker和集群
broker 是集群的组成部分,broker 集群由一个或多个 broker 组成,每个集群都有一个 broker 同时充当了集群控制器的角色(自动选举)。broker接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。broker为消费者提供服务,对读取分区的请求做出响应,返回已经提交到磁盘上的消息。单个broker可以轻松处理数千个分区以及每秒百万级的消息量。文章来源地址https://www.toymoban.com/news/detail-607899.html
到了这里,关于Kafka基础架构与核心概念的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!