Linux丢包问题排查思路
判断问题与网络丢包有关
通过抓tcpdump,通过wireshark提示查看数据包状态。比如客户端重传多次失败,服务端提示丢包等错误,均是可能由于丢包导致的异常。

丢包可能存在的位置
网络丢包在交互过程中的每一个环节都有可能出现。主要环节如下:
- 两端服务器:主要表现在网卡异常、服务器资源限制(负载,TCP连接数等)、软件异常、服务器配置等导致的丢包
- 网络链路(包括链路层、网络层、传输层):主要是TCP/UDP传输过程中出现异常导致,比如:arp表溢出、路由过滤、防火墙拦截、tcp分片重组超时重组异常失败、MTU丢包、限速限流、带宽占满等导致的丢包。
- 应用层:主要表现在应用在处理socket连接时的异常。
丢包原因分析
网络链路丢包
网络链路的丢包主要通过网络链路的监控、以及客户端抓包数据完整、但服务端收包内容有截取等判断,需要考虑链路中的防火墙等安全设备的影响,首先排除掉安全设备的原因。
我们在实际生产中有遇到过nginx响应请求返回400/499,经分析,存在WAF过滤报文中部分信息、大包未分片导致超过MTU限值的情况。
应用层丢包
应用层丢包主要出现在应用使用线程池化的模式处理请求连接池,当池化不合理导致池满未释放,无法建立新连接时容易出现。
服务器上的丢包情况
接下来着重讨论应该如何在服务器上排查丢包情况。
请求在服务器内部的流程
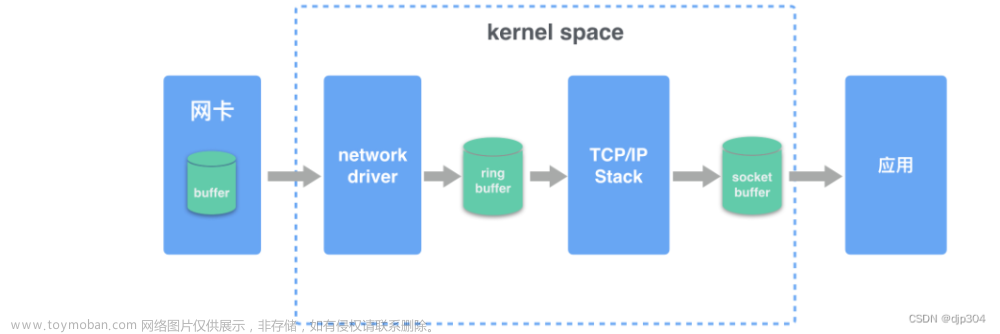
-
首先网络报文通过物理网线发送到网卡
-
网络驱动程序会把网络中的报文读出来放到 ring buffer 中,这个过程使用 DMA(Direct Memory Access),不需要 CPU 参与
-
内核从 ring buffer 中读取报文进行处理,执行 IP 和 TCP/UDP 层的逻辑,最后把报文放到应用程序的 socket buffer 中
-
应用程序从 socket buffer 中读取报文进行处理
通过如上图,可看出,在每一个环节都有存在丢包的可能性。接下来逐一分析。
网卡、网卡驱动丢包
首先可通过命令查看,是否网卡有丢包。
# ifconfig
#RX(receive 接收报文):packets 正确的数据包数, bytes 数据量字节,errors 产生错误的数据包数,dropped 丢弃的数据包数, overruns 速度过快丢失的数据包数,frame 发生frame错误而丢失的数据包数。
#TX(transmit 发送报文):packets, bytes ,errors,dropped,overruns 与接收一致。carrier 发生carrier错误而丢失的数据包数。collisions 冲突信息包的数目。
[root@gavin ~] ifconfig ens33
ens33: flags=4163<UP ,BROADCAST,RUNNING,IULTICAST> mtu _1500
inet 192.168.76.3 netmask 255.255.255.0 broadcast 192.168.76.255
inet6 fe80::3dc2:5ebd:8970:475a prefixlen 64scopeid 0x20<link>
ether 00:0c:29:d0:ef:9e txqueuelen 1000 (Ethernet)
RX packets 3001 bytes 3447676(3.2 MiB)
Rx errors 0 dropped 0 overruns 0 frame 0
TX packets 949 bytes 62837(61.3 KiB)
TX errors dropped 0 overruns 0 carrier 0 collisions 0
#netstat
#netstat -i 打印网卡信息
#Iface:网卡名
#MTU:最大传输单元
#RX-OK:接收时,正确的数据包数
#RX-ERR:接收时,产生错误的数据包数
#RX-DRP:接收时,丢弃的数据包数
#RX-OVR:接收时,由于过速而丢失的数据包数
#TX-OK:发送时,正确的数据包数
#TX-ERR:发送时,产生错误的数据包数
#TX-DRP:发送时,丢弃的数据包数
#TX-OVR:发送时,由于过速而丢失的数据包数
[root@gavin ~]# netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
ens33 1500 14586 0 0 0 7943 0 0 0 BMRU
ens37 1500 400 0 0 0 64 0 0 0 BMRU
lo 65536 50 0 0 0 50 0 0 0 LRU
privbr0 1500 399 0 0 0 64 0 0 0 BMRU
virbr0 1500 0 0 0 0 0 0 0 0 BMU
#netstat -s 统计个协议信息
[root@gavin ~]# netstat -s
Ip:
Forwarding: 1
16333 total packets received
15 with invalid addresses
0 forwarded
0 incoming packets discarded
15955 incoming packets delivered
9039 requests sent out
139 dropped because of missing route
Icmp:
2 ICMP messages received
0 input ICMP message failed
ICMP input histogram:
destination unreachable: 2
2 ICMP messages sent
0 ICMP messages failed
ICMP output histogram:
destination unreachable: 2
IcmpMsg:
InType3: 2
OutType3: 2
Tcp:
46 active connection openings
2 passive connection openings
28 failed connection attempts
3 connection resets received
3 connections established
15484 segments received
8871 segments sent out
0 segments retransmitted
0 bad segments received
30 resets sent
Udp:
251 packets received
2 packets to unknown port received
0 packet receive errors
194 packets sent
0 receive buffer errors
0 send buffer errors
IgnoredMulti: 250
UdpLite:
TcpExt:
8 TCP sockets finished time wait in fast timer
17 delayed acks sent
Quick ack mode was activated 2 times
15228 packet headers predicted
24 acknowledgments not containing data payload received
58 predicted acknowledgments
2 connections reset due to early user close
IPReversePathFilter: 304
TCPRcvCoalesce: 36
TCPAutoCorking: 4
TCPOrigDataSent: 89
TCPDelivered: 105
IpExt:
InMcastPkts: 141
OutMcastPkts: 81
InBcastPkts: 250
InOctets: 17680346
OutOctets: 385931
InMcastOctets: 13407
OutMcastOctets: 9914
InBcastOctets: 72750
InNoECTPkts: 18122
MPTcpExt:
#ethtool
# 有错误说明有丢包
[root@gavin ~]# ethtool -S ens33 | grep rx_ | grep errors
rx_errors: 0
rx_length_errors: 0
rx_over_errors: 0
rx_crc_errors: 0
rx_frame_errors: 0
rx_missed_errors: 0
rx_long_length_errors: 0
rx_short_length_errors: 0
rx_align_errors: 0
rx_csum_offload_errors: 0
buffer满导致的丢包
主要是ring buffer 和socket buffer满导致的丢包
ring buffer:环形缓冲器,在通信程序中,经常使用环形缓冲器作为数据结构来存放通信中发送和接收的数据。环形缓冲区是一个先进先出的循环缓冲区,可以向通信程序提供对缓冲区的互斥访问。
socket buffer:套接字缓存,Linux网络核心数据结构。它代表一个要发送或处理的报文,并贯穿于整个协议栈。
#查看是否因ring buffer 满导致的丢包
#ethtool 或 /proc/net/dev
[root@gavin ~]# ethtool -S ens33|grep rx_fifo
[root@gavin ~]# cat /proc/net/dev
Inter-| Receive | Transmit
face |bytes packets errs drop fifo frame compressed multicast|bytes packets errs drop fifo colls carrier compressed
lo: 46780 774 0 0 0 0 0 0 46780 774 0 0 0 0 0 0
ens33: 18909713 22098 0 0 0 0 0 0 697617 9849 0 0 0 0 0 0
ens37: 1125961 3788 0 3 0 0 0 0 8591 68 0 0 0 0 0 0
privbr0: 1069444 3768 0 0 0 0 0 635 8363 68 0 0 0 0 0 0
virbr0: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
virbr0-nic: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
#查看ring buffer 设置
[root@gavin ~]# ethtool -g ens33
Ring parameters for ens33:
Pre-set maximums:
RX: 4096
RX Mini: n/a
RX Jumbo: n/a
TX: 4096
Current hardware settings:
RX: 256
RX Mini: n/a
RX Jumbo: n/a
TX: 256
#修改大小
ethtool -G ens33 rx 4096 tx 4096
# socket buffer 丢包一般由于系统高负载,导致 socket buffer占满丢包
#可通过命令判断
[root@gavin ~]# netstat -s | grep "buffer errors"
0 receive buffer errors
0 send buffer errors
#socket buffer 调整需要通过修改内核参数的方式
net.ipv4.tcp_wmem
net.ipv4.tcp_rmem
net.ipv4.tcp_mem
net.core.rmem_default
net.core.rmem_max
net.core.wmem_max
服务器TCP连接、连接数限制等导致建连失败丢包
此情况一般是查看TCP连接数和状态,确认服务器最大文件打开数,tcp 线程数限制等。
#统计TCP各连接状态的数量
netstat -an | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
#修改limit 限制、最大文件打开数,最大进程数、最大连接数,针对用户。非针对系统服务的资源
/etc/security/limits.conf
# - core - limits the core file size (KB) 限制内核文件的大小。
# - data - max data size (KB) 最大数据大小
# - fsize - maximum filesize (KB) 最大文件大小
# - memlock - max locked-in-memory address space (KB) 最大锁定内存地址空间
# - nofile - max number of open file descriptors 最大打开的文件数(以文件描叙符,file descripter计数)
# - rss - max resident set size (KB) 最大持久设置大小
# - stack - max stack size (KB) 最大栈大小
# - cpu - max CPU time (MIN) 最多CPU占用时间,单位为MIN分钟
# - nproc - max number of processes 进程的最大数目
# - as - address space limit (KB) 地址空间限制
# - maxlogins - max number of logins for this user 此用户允许登录的最大数目
# - maxsyslogins - max number of logins on the system 系统最大同时在线用户数
# - priority - the priority to run user process with 运行用户进程的优先级
# - locks - max number of file locks the user can hold 用户可以持有的文件锁的最大数量
# - sigpending - max number of pending signals
# - msgqueue - max memory used by POSIX message queues (bytes)
# - nice - max nice priority allowed to raise to values: [-20, 19] max nice优先级允许提升到值
#设置内核最大的文件句柄数
/proc/sys/fs/file-max
#设置进程最大的文件句柄数,不能超过1
/proc/sys/fs/nr_open
时间戳和TCP连接复用配置导致的连接丢包
主要是 tcp_tw_recycle,tcp_timestamps造成的影响。
-
net.ipv4.tcp_tw_recycle:用于快速回收处于TIME_WAIT 状态的socket 连接;(通常在开启net.ipv4.tcp_timestamps 时有效,1代表开启,0代表关闭)
-
net.ipv4.tcp_timestamps:启用时间戳,默认缺省值为1,开启;该值必须为单调递增,否则接受到的包可能会被丢掉。
TCP协议中有一种机制,缓存了每个主机(即ip)过来的连接最新的timestamp值。这个缓存的值可以用于PAWS(Protect Against Wrapped Sequence numbers,是一个简单的防止重复报文的机制)中,来丢弃当前连接中可能的旧的重复报文。在tcp_tw_recycle/tcp_timestamps都开启的条件下,60s内同一源ip主机的tcp 链接请求中的timestamp必须是递增的。文章来源:https://www.toymoban.com/news/detail-610726.html
这两个值开启与否需要根据实际情况进行判断,我们在生产中曾经遇到过未开启而导致三次握手中最后一次握手丢包的情况,也存在开启后,导致第一次握手无应答的情况。文章来源地址https://www.toymoban.com/news/detail-610726.html
到了这里,关于Linux丢包问题排查思路的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!











