1.kafka能不能发送null消息?
能!

2 flink能不能发送null消息到kafka?
不能!
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment
.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"9.135.68.201:9092" );
FlinkKafkaProducer<String> flinkKafkaProducer = new FlinkKafkaProducer<>( "cc_test",new SimpleStringSchema(),properties);
env.fromCollection(Lists.newArrayList("111", "222", "333"))
.map(s->{return s.equals("222")?null:s;})
.addSink(flinkKafkaProducer);
env.execute("ContractLabelJob");
}
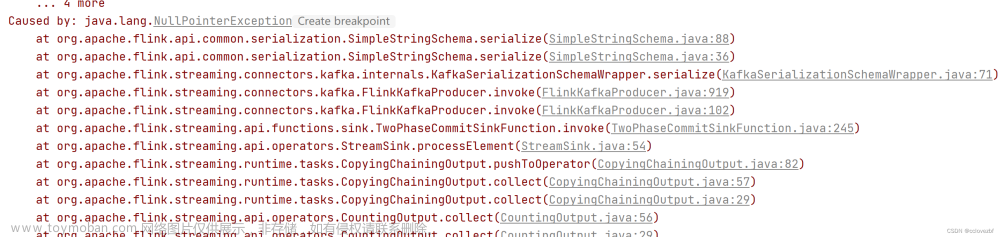
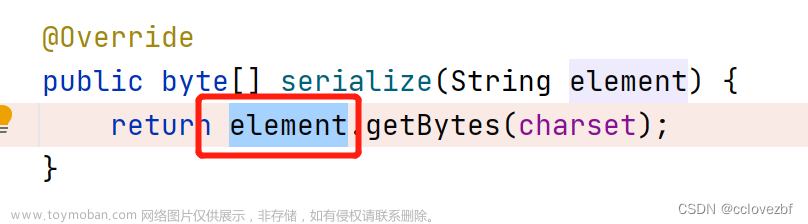
这里就报了java的最常见错误 空指针,原因就是flink要把kafka的消息getbytes。所以flink不能发送null到kafka。
这种问题会造成什么后果?
flink直接挂掉。
如果我们采取了失败重试机制会怎样?
env.setRestartStrategy( RestartStrategies.fixedDelayRestart(3, Time.seconds(5)) );
数据重复或者丢失。

还有此时kafka的offset由flink在管理, 消费的offset 一直没有被commit,所以一直重复消费。
来个demo
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment
.getExecutionEnvironment();
env.enableCheckpointing(6000);
// env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000);
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"9.135.68.201:9092" );
FlinkKafkaProducer<String> sink = new FlinkKafkaProducer<>( "cc_test2",new SimpleStringSchema(),properties);
KafkaSource<String> source = KafkaSource.<String>builder()
.setTopics("cc_test")
.setGroupId("cc_test1234")
.setBootstrapServers("9.135.68.201:9092")
.setValueOnlyDeserializer(new SimpleStringSchema())
.setStartingOffsets(OffsetsInitializer.earliest())
.build();
DataStreamSource<String> stringDataStreamSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "kafka");
// stringDataStreamSource.print("kafka msg");
stringDataStreamSource
.addSink(sink);
env.execute("test");从topic cc_test消费 然后写到cc_test2里面去
cc_test里的数据

cc_test_2里写入的数据
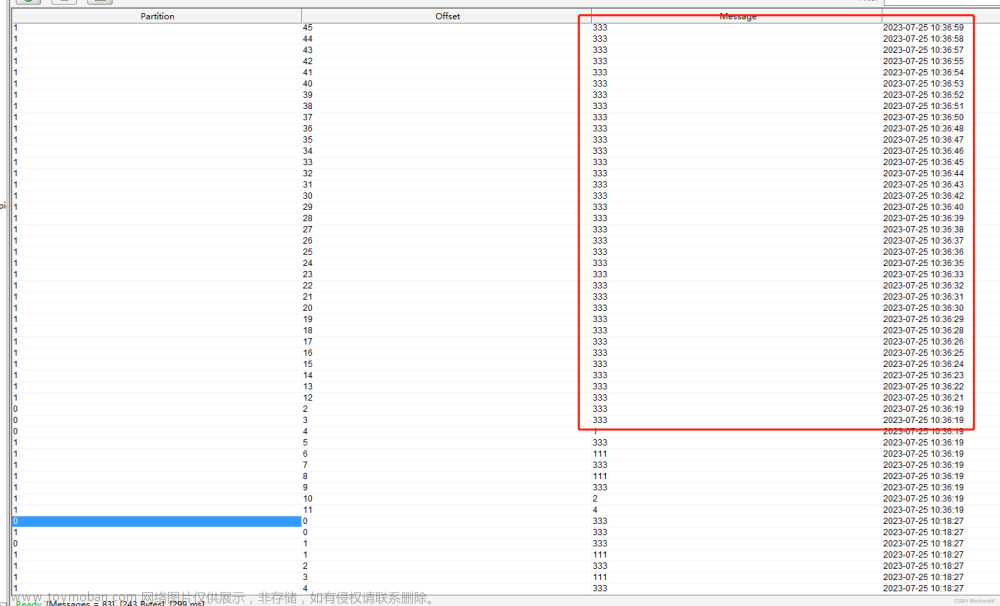
可以看到一个null 报错了,然后它分区的333就会一直被提交。
总之大家小心这个问题。
不加检查点 flink报错后就会直接停掉。。
加了检查点env.enableCheckpointing(6000); flink失败后会一直重试
加了重试机制 env.setRestartStrategy(RestartStrategies.failureRateRestart(3,Time.of(5000, TimeUnit.SECONDS),Time.of(5000,TimeUnit.SECONDS))); 失败的任务只会重试几次。文章来源:https://www.toymoban.com/news/detail-613593.html
还是得熟悉源码呀。文章来源地址https://www.toymoban.com/news/detail-613593.html
到了这里,关于flink写入到kafka 大坑解析。的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!












