🏡博客主页: virobotics的CSDN博客:LabVIEW深度学习、人工智能博主
🎄所属专栏:『LabVIEW深度学习实战』
🍻上期文章:『LabVIEW深度相机与三维定位实战(上)』
📰如觉得博主文章写的不错或对你有所帮助的话,还望大家多多支持呀! 欢迎大家✌关注、👍点赞、✌收藏、👍订阅专栏
前言
Hello,大家好,这里是virobotics。今天给大家分享在LabVIEW中实现深度相机与三维定位:立体匹配与ACV算法。关于双目相机基础支持可查看上一篇博文『LabVIEW深度相机与三维定位实战(上)』
一、立体匹配与ACV算法
1.1 立体匹配
-
基本思路
如上一篇博文所述,如果已知左右相机画面中的两个像素来源于空间中的同一个点,那么就可以通过视差来计算出该点到基线的距离(深度)。
如果有一种算法:针对左目画面中的每一个像素,能够分别找到它们在右目画面中对应空间中同一点的像素(假如存在的话),那么就可以计算出单目画面中每一个点的深度,从而形成立体视觉。
-
立体匹配的任务
立体匹配的目标,就是从不同视点图像中找到匹配的对应点。该模型的输入为若干不同视角的相机采集的图像,输出是这些图像上的点的对应关系。
立体匹配是目前机器视觉领域的一个难点,近年来不断有人发明或改良出新的方法,以求提高效率和准确性。本文接下来将介绍其中一种方法——ACV。
1.2 ACV算法
-
简介
该算法来源于今年(2022)发表于CVPR上的一篇论文:
Attention Concatenation Volume for Accurate and Efficient Stereo Matching
原文下载地址: https://arxiv.org/abs/2203.02146ACV,即 Attention Concatenation Volume,意为:注意力连接(代价)体。它是文章提出的一种新的立体匹配“代价体”的构建方法。
“该方法利用相关线索生成注意力权重,以抑制冗余信息,增强连接体积中的匹配相关信息。为了产生可靠的注意力权重,本文提出了多级自适应补丁匹配,以提高不同视差下匹配成本的显著性,即使是无纹理区域。”
-
ACVNet网络结构
如下图所示,首先通过CNN分别提取左右画面的特征图,然后上下“兵分两路”:
1、下边将左右特征图,按照一定规律拼接,生成初始连接代价体(Concat volume);
2、上边将(不同层的)左右特征图,进行多级自适应补丁匹配(MAPM),最终生成注意力权重 (Attention Weights);
3、用注意力权重 对Concat volume进行过滤,以增强相关抑制冗余,得到注意力连接代价体(Attention concat volume);
4、最后ACV通过一个代价聚合网络(Cost Aggregation),输出最终结果(Left画面每一点的视差预测)。
-
初始连接代价体的构建
给定一个尺寸为H×W×3的输入立体图像对,对于每个图像,我们通过CNN特征提取,分别得到左、右图像的一元特征图fl和fr。特征图的大小为Nc×H/4×W/4(Nc=32)。然后通过连接每个视差水平的fl和fr形成初始连接体,即为

Cconcat 的尺寸为2Nc ×D/4×H/4×W/4 ,其中D为最大视差。
🔍 帮助理解:
1、左右特征图都是Nc通道。并且经过多次卷积之后,尺寸已经缩小为原来的1/4。那么原图最大视差D,就对应特征图的最大视差为D/4;
2、通俗地讲解拼接过程:
把Nc通道的右特征图的所有像素,沿X轴向右平移1个像素,然后拼接在Nc通道的左特征图的后面,得到第1组2Nc通道的拼接特征图。
平移2个像素拼接得到第2组、平移3个像素拼接得到第3组……直到平移D/4,一共D/4组2Nc通道的拼接特征图。因此Cconcat 的尺寸为2Nc ×D/4×H/4×W/43、这种连接体的构建,实际是在列举所有视差匹配的可能性。理想双目只在X方向有视差,即同源点必然位于左右特征图的同一条水平线上,且XL一定大于XR。因此我们对右侧特征图沿X向右平移1到D/4个单位,再分别与左侧特征图叠加,就能让所有同源点得到一次“左右重合”的机会。重合时对应的平移距离,反映了该点的视差大小,进而反映该点的深度。
-
多级自适应补丁匹配(MAPM)
从特征提取模块得到3个不同层次的特征图l1、l2、l3,其通道数分别为64、128、128。对于每一个处于特定水平的像素,我们利用一个具有预定尺寸和自适应学习权重的atrous patch来计算匹配成本。通过控制膨胀率,我们确保patch的范围与特征图层有关,同时在计算中心像素的相似度时保持相同的像素数量。然后,两个相应的像素的相似性是patch内相应像素之间的相关性的加权和。
🔍 帮助理解:
1、虽然算法复杂,但是目的简单,就是在估计左右特征图上的两个点是空间同一点的可能性(权重);
2、估算可能性的方法,是选取该点及其周围点,参与加权计算。这个选取范围叫做patch,是个会膨胀的自适应范围。但无论怎么膨胀,参与计算的点数是恒定的9个,就是图中红色和橙色的点。白色的点是膨胀产生的空洞,不参与计算。
将l1、l2和l3的三级特征图连接起来,形成Nf个通道的单级特征图(Nf=320)。将Nf通道平均分成Ng组(Ng=40),前8组来自l1,中间16组来自l2,最后16组来自l3。不同级别的特征图不会相互干扰。我们把第g个特征组表示为 
,多级补丁匹配量Cpatch的计算方法为:
-
注意力权重过滤
在得到注意权重A后,我们用它来消除初始连接代价体中的冗余信息,进而提高其表示能力。
通道 i 处的注意力连接代价体(ACV)计算为:
⊙表示对应像素点乘,注意力权重 A 应用于初始连接代价体的所有通道的过滤。 -
代价聚合与视差预测
用一个预沙漏模块来处理ACV,它由4个3D卷积组成(包括批归一化、ReLU)、2个3D堆叠沙漏网络,堆叠在一个 encoder-decoder结构。由代价聚合获得3个输出,对于每个输出,使用2个3D卷积得到单通道4D volume,然后上采样并通过softmax转化为置信体。3个预测的视差图表示为d0、d1、d2。最终,预测值就是每一层视差与置信度乘积求和。(k表示视差层级,pk表示对应的置信度)

二、环境搭建
2.1 部署本项目时所用环境
- 操作系统:Windows10
- python:3.6及以上
- LabVIEW:2018及以上 64位版本
- AI视觉工具包:techforce_lib_opencv_cpu-1.0.0.98.vip
- onnx工具包:virobotics_lib_onnx_cuda_tensorrt-1.0.0.16.vip【1.0.0.16及以上版本】
2.2 LabVIEW工具包下载及安装
- AI视觉工具包下载与安装参考:
https://blog.csdn.net/virobotics/article/details/123656523 - onnx工具包下载与安装参考:
https://blog.csdn.net/virobotics/article/details/124998746
三、LabVIEW实现ACVNet立体匹配
3.1 获取模型
项目中提供一个onnx格式的ACVNet模型,模型文件位于:“范例\acvnet_maxdisp192_sceneflow_240x320.onnx”
模型的输入为左右两张彩色图,大小均为 3240320,须归一化到(-1~1)之间。
最大视差为maxdisp = 192 。
模型的输出为3个层级下的,左图各个像素的视差预测。通常我们只取其中一个层级下的预测结果。
3.2 测试范例
-
打开“范例\ACVNet_main.vi”;
-
切换到程序框图,检查依赖的模型文件路径、左右图片路径是否正确。
-
切换到前面板,运行VI,观察输出结果。(本范例采用灰度图对预测结果进行后处理,灰度大小与该点的视差大小正相关)
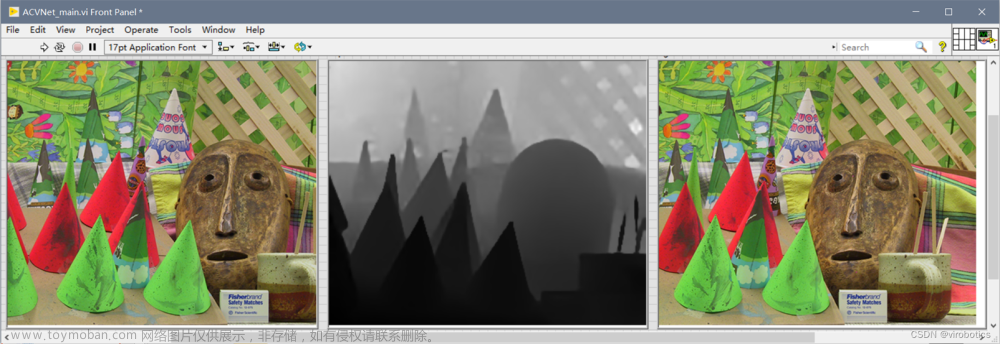
-
修改图片路径,用上一篇博文采集的left.png和right.png图片作为输入,运行测试。

四、项目源码
如需源码,可在一键三连并订阅本专栏后评论区留下邮箱
总结
以上就是今天要给大家分享的内容,希望对大家有用。我是virobotics,我们下篇文章见~
如果文章对你有帮助,欢迎✌关注、👍点赞、✌收藏、👍订阅专栏
推荐阅读
LabVIEW图形化的AI视觉开发平台(非NI Vision),大幅降低人工智能开发门槛
LabVIEW图形化的AI视觉开发平台(非NI Vision)VI简介
LabVIEW AI视觉工具包OpenCV Mat基本用法和属性
手把手教你使用LabVIEW人工智能视觉工具包快速实现图像读取与采集文章来源:https://www.toymoban.com/news/detail-624156.html
👇技术交流 · 一起学习 · 咨询分享,请联系👇文章来源地址https://www.toymoban.com/news/detail-624156.html
到了这里,关于LabVIEW深度相机与三维定位实战(下)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!













