01、TransBigData简介
TransBigData是一个为交通时空大数据处理、分析和可视化而开发的Python包。TransBigData为处理常见的交通时空大数据(如出租车GPS数据、共享单车数据和公交车GPS数据等)提供了快速而简洁的方法。TransBigData为交通时空大数据分析的各个阶段提供了多种处理方法,代码简洁、高效、灵活、易用,可以用简洁的代码实现复杂的数据任务。
目前,TransBigData主要提供以下方法:
❖数据预处理:对数据集提供快速计算数据量、时间段、采样间隔等基本信息的方法,也针对多种数据噪声提供了相应的清洗方法。
❖数据栅格化:提供在研究区域内生成、匹配多种类型的地理栅格(矩形、三角形、六边形及geohash栅格)的方法体系,能够以向量化的方式快速算法将空间点数据映射到地理栅格上。
❖数据可视化:基于可视化包keplergl,用简单的代码即可在Jupyter Notebook上交互式地可视化展示数据。
❖轨迹处理:从轨迹数据GPS点生成轨迹线型,轨迹点增密、稀疏化等。
❖地图底图、坐标转换与计算:加载显示地图底图与各类特殊坐标系之间的坐标转换。
❖特定处理方法:针对各类特定数据提供相应处理方法,如从出租车GPS数据中提取订单起讫点,从手机信令数据中识别居住地与工作地,从地铁网络GIS数据构建网络拓扑结构并计算最短路径等。
TransBigData可以通过pip或者conda安装,在命令提示符中运行下面代码即可安装:
pip install -U transbigdata安装完成后,在Python中运行如下代码即可导入TransBigData包。
In [1]:
import transbigdata as tbd02、数据预处理
TransBigData与数据处理中常用的Pandas和GeoPandas包能够无缝衔接。首先我们引入Pandas包并读取出租车GPS数据:
In [2]:
import pandas as pd
#读取数据
data = pd.read_csv('TaxiData-Sample.csv',header = None)
data.columns = ['VehicleNum','time','lon','lat','OpenStatus','Speed']
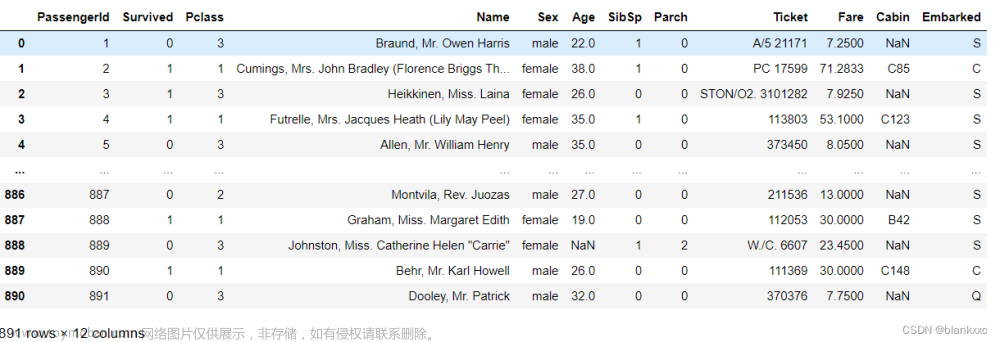
data.head()结果如图1所示。

■ 图1 出租车GPS数据
然后,引入GeoPandas包,读取研究范围的区域信息并展示:
In [3]:
import geopandas as gpd
#读取研究范围区域信息
sz = gpd.read_file(r'sz/sz.shp')
sz.plot()结果如图2所示。

■ 图2 研究范围的区域信息
TransBigData包集成了交通时空数据的一些常用预处理方法。其中,tbd.clean_outofshape方法输入数据和研究范围区域信息,能够剔除研究范围外的数据。而tbd.clean_taxi_status方法则可以剔除出租车GPS数据中载客状态瞬间变化的记录。在使用预处理方法时需要传入数据表中重要信息列所对应的列名,代码如下:
In [4]:
#数据预处理
#剔除研究范围外的数据,计算原理是在方法中先栅格化后栅格匹配研究范围后实现对应。因此这里需要同时定义栅格大小,越小则精度越高
data = tbd.clean_outofshape(data, sz, col=['lon', 'lat'], accuracy=500)
#剔除出租车数据中载客状态瞬间变化的数据
data = tbd.clean_taxi_status(data, col=['VehicleNum', 'time', 'OpenStatus'])经过上面代码的处理,我们就已经将出租车GPS数据中研究范围以外的数据和载客状态瞬间变化的数据予以剔除。
03、数据栅格化
栅格形式(地理空间上相同大小的网格)是表达数据分布最基本的方法,GPS数据经过栅格化后,每个数据点都含有其所在的栅格信息。采用栅格表达数据的分布时,其表示的分布情况与真实情况接近。
TransBigData工具为我们提供了一套完整、快速、便捷的栅格处理体系。用TransBigData进行栅格划分时,首先需要确定栅格化的参数(可以理解为定义了一个栅格坐标系),参数可以帮助我们快速进行栅格化:
In [5]:
#定义研究范围边界
bounds = [113.75, 22.4, 114.62, 22.86]
#通过边界获取栅格化参数
params = tbd.area_to_params(bounds,accuracy = 1000)
params
Out [5]:
{'slon': 113.75,
'slat': 22.4,
'deltalon': 0.00974336289289822,
'deltalat': 0.008993210412845813,
'theta': 0,
'method': 'rect',
'gridsize': 1000}此时输出的栅格化参数params的内容存储了栅格坐标系的原点坐标(slon、slat)、单个栅格的经纬度长宽 (deltalon、deltalat)、栅格的旋转角度(theta)、栅格的形状(method参数,其值可以是方形rect、三角形tri和六边形hexa)以及栅格的大小(gridsize参数,单位为米)。
取得栅格化参数后,我们便可以用TransBigData中提供的方法对GPS数据进行栅格匹配、生成等操作。完整的栅格处理方法体系如图3所示。

■ 图3 TransBigData所提供的栅格处理体系
使用tbd.GPS_to_grid方法能够为每一个出租车GPS点生成,该方法会生成编号列 LONCOL与 LATCOL,由这两列共同指定所在的栅格:
In [6]:
#将GPS数据对应至栅格,将生成的栅格编号列赋值到数据表上作为新的两列
data['LONCOL'],data['LATCOL'] = tbd.GPS_to_grids(data['lon'],data['lat'],params)下一步,聚合集计每一栅格内的数据量,并为栅格生成地理几何图形,构建GeoDataFrame:
In [7]:
#聚合集计栅格内数据量
grid_agg = data.groupby(['LONCOL','LATCOL'])['VehicleNum'].count().reset_index()
#生成栅格的几何图形
grid_agg['geometry'] = tbd.grid_to_polygon([grid_agg['LONCOL'],grid_agg['LATCOL']],params)
#转换为GeoDataFrame
grid_agg = gpd.GeoDataFrame(grid_agg)
#绘制栅格
grid_agg.plot(column = 'VehicleNum',cmap = 'autumn_r') 结果如图4所示。

■ 图 5数据栅格化的结果
对于一个正式的数据可视化图来说,我们还需要添加底图、色条、指北针和比例尺。TransBigData也提供了相应的功能,代码如下:
In [8]:
import matplotlib.pyplot as plt
fig =plt.figure(1,(8,8),dpi=300)
ax =plt.subplot(111)
plt.sca(ax)
#添加行政区划边界作为底图
sz.plot(ax = ax,edgecolor = (0,0,0,0),facecolor = (0,0,0,0.1),linewidths=0.5)
#定义色条位置
cax = plt.axes([0.04, 0.33, 0.02, 0.3])
plt.title('Data count')
plt.sca(ax)
#绘制数据
grid_agg.plot(column = 'VehicleNum',cmap = 'autumn_r',ax = ax,cax = cax,legend = True)
#添加指北针和比例尺
tbd.plotscale(ax,bounds = bounds,textsize = 10,compasssize = 1,accuracy = 2000,rect = [0.06,0.03],zorder = 10)
plt.axis('off')
plt.xlim(bounds[0],bounds[2])
plt.ylim(bounds[1],bounds[3])
plt.show() 结果如图5所示。

■ 图5 tbd包绘制的出租车GPS数据分布
04、订单起讫点OD提取与聚合集计
针对出租车GPS数据,TransBigData提供了直接从数据中提取出出租车订单起讫点(OD)信息的方法,代码如下:
In [9]:
#从GPS数据提取OD
oddata = tbd.taxigps_to_od(data,col = ['VehicleNum','time','Lng','Lat','OpenStatus'])
oddata 结果如图6所示。

■ 图6 tbd包提取的出租车OD
TransBigData包提供的栅格化方法可以让我们快速地进行栅格化定义,只需要修改accuracy参数,即可快速定义不同大小粒度的栅格。我们重新定义一个2km*2km的栅格坐标系,将其参数传入tbd.odagg_grid方法对OD进行栅格化聚合集计并生成GeoDataFrame:
In [10]:
#重新定义栅格,获取栅格化参数
params = tbd.area_to_params(bounds,accuracy = 2000)
#栅格化OD并集计
od_gdf = tbd.odagg_grid(oddata,params)
od_gdf.plot(column = 'count') 结果如图7所示。

■ 图7 tbd集计的栅格OD
添加地图底图,色条与比例尺指北针:
In [11]:
#创建图框
import matplotlib.pyplot as plt
fig =plt.figure(1,(8,8),dpi=300)
ax =plt.subplot(111)
plt.sca(ax)
#添加行政区划边界作为底图
sz.plot(ax = ax,edgecolor = (0,0,0,1),facecolor = (0,0,0,0),linewidths=0.5)
#绘制colorbar
cax = plt.axes([0.05, 0.33, 0.02, 0.3])
plt.title('Data count')
plt.sca(ax)
#绘制OD
od_gdf.plot(ax = ax,column = 'count',cmap = 'Blues_r',linewidth = 0.5,vmax = 10,cax = cax,legend = True)
#添加比例尺和指北针
tbd.plotscale(ax,bounds = bounds,textsize = 10,compasssize = 1,accuracy = 2000,rect = [0.06,0.03],zorder = 10)
plt.axis('off')
plt.xlim(bounds[0],bounds[2])
plt.ylim(bounds[1],bounds[3])
plt.show() 结果如图8所示。

■ 图8 TransBigData绘制的栅格OD数据
同时,TransBigData包也提供了将OD直接聚合集计到区域间的方法:
In [12]:
#OD集计到区域
#方法1:在不传入栅格化参数时,直接用经纬度匹配
od_gdf = tbd.odagg_shape(oddata,sz,round_accuracy=6)
#方法2:传入栅格化参数时,程序会先栅格化后匹配以加快运算速度,数据量大时建议使用
od_gdf = tbd.odagg_shape(oddata,sz,params = params)
od_gdf.plot(column = 'count') 结果如图9所示。

■ 图9 tbd集计的小区OD
加载地图底图并调整出图参数:
In [13]:
#创建图框
import matplotlib.pyplot as plt
import plot_map
fig =plt.figure(1,(8,8),dpi=300)
ax =plt.subplot(111)
plt.sca(ax)
#添加行政区划边界作为底图
sz.plot(ax = ax,edgecolor = (0,0,0,0),facecolor = (0,0,0,0.2),linewidths=0.5)
#绘制colorbar
cax = plt.axes([0.05, 0.33, 0.02, 0.3])
plt.title('count')
plt.sca(ax)
#绘制OD
od_gdf.plot(ax = ax,vmax = 100,column = 'count',cax = cax,cmap = 'autumn_r',linewidth = 1,legend = True)
#添加比例尺和指北针
tbd.plotscale(ax,bounds = bounds,textsize = 10,compasssize = 1,accuracy = 2000,rect = [0.06,0.03],zorder = 10)
plt.axis('off')
plt.xlim(bounds[0],bounds[2])
plt.ylim(bounds[1],bounds[3])
plt.show() 结果如图10所示。

■ 图10 区域间OD可视化结果
05、交互可视化
在TransBigData中,我们可以对出租车数据使用简单的代码在jupyter notebook中快速进行交互可视化。这些可视化方法底层依托了keplergl包,可视化的结果不再是静态的图片,而是能够与鼠标响应交互的地图应用。
tbd.visualization_data方法可以实现数据分布的可视化,将数据传入该方法后,TransBigData会首先对数据点进行栅格集计,然后生成数据的栅格,并将数据量映射至颜色上。代码如下:
In [14]:
#可视化数据点分布
tbd.visualization_data(data,col = ['lon','lat'],accuracy=1000,height = 500)结果如图11所示。

■ 图11 数据分布的栅格可视化
对于出租车数据中所提取出的出行OD,也可使用tbd.visualization_od方法实现OD的弧线可视化。该方法也会对OD数据进行栅格聚合集计,生成OD弧线,并将不同大小的OD出行量映射至不同颜色。代码如下:
In [15]:
#可视化数据点分布
tbd.visualization_od(oddata,accuracy=2000,height = 500) 结果如图12所示。

■ 图12 OD分布的弧线可视化
对个体级的连续追踪数据,tbd.visualization_trip方法可以将数据点处理为带有时间戳的轨迹信息并动态地展示,代码如下:
In [16]:
#动态可视化轨迹
tbd.visualization_trip(data,col = ['lon','lat','VehicleNum','time'],height = 500) 结果图13所示。点击其中的播放键,可以看到出租车运行的动态轨迹效果。
 文章来源:https://www.toymoban.com/news/detail-630952.html
文章来源:https://www.toymoban.com/news/detail-630952.html
■ 13 出租车轨迹动态可视化文章来源地址https://www.toymoban.com/news/detail-630952.html
到了这里,关于使用TransBigData快速高效地处理、分析、挖掘出租车GPS数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!