为了在不重新启动 Flink 作业的情况下处理主题扩展或主题创建等场景,可以将 Kafka 源配置为在提供的主题分区订阅模式下定期发现新分区。要启用分区发现,请为属性partition.discovery.interval.ms设置一个非负值。
一、动态发现新增分区
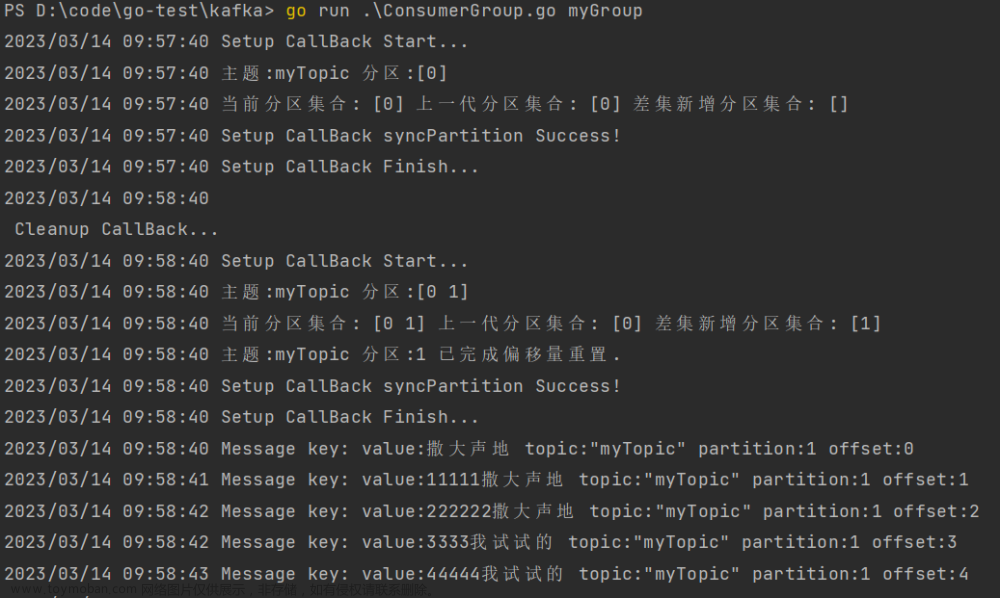
flink程序增加自动发现分区参数:
- flink.partition-discovery.interval-millis是一个配置属性,用于设置Flink作业中的分区发现间隔时间(以毫秒为单位)。
- 在Flink作业中,数据源(例如Kafka或文件系统)的分区可能会发生变化。为了及时感知分区的变化情况,并根据变化进行相应的处理,Flink提供了分区发现机制。
- flink.partition-discovery.interval-millis配置属性用于设置Flink作业在进行分区发现时的间隔时间。Flink作业会定期检查数据源的分区情况,如果发现分区发生了变化(例如增加或减少了分区),Flink会相应地调整作业的并行度或重新分配任务来适应新的分区情况。
- 通过调整flink.partition-discovery.interval-millis的值,可以控制Flink作业进行分区发现的频率。较小的间隔时间可以实时感知到分区变化,但可能会增加作业的开销;较大的间隔时间可以减少开销,但可能导致较长时间的延迟。
- 需要注意的是,flink.partition-discovery.interval-millis的默认值是5分钟(300000毫秒),可以根据具体需求进行调整。
二、Flink SQL动态发现新增分区
参数:scan.topic-partition-discovery.interval
CREATE TABLE KafkaTable (
`event_time` TIMESTAMP(3) METADATA FROM 'timestamp',
`partition` BIGINT METADATA VIRTUAL,
`offset` BIGINT METADATA VIRTUAL,
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
);
Connector Options:
| Option | Required | Default | Type | Description |
|---|---|---|---|---|
| scan.topic-partition-discovery.interval | optional | (none) | Duration | 消费者定期发现动态创建的Kafka主题和分区的时间间隔。 |
三、Flink API动态发现新增分区
参数:partition.discovery.interval.ms
Java文章来源:https://www.toymoban.com/news/detail-647384.html
KafkaSource.builder()
.setProperty("partition.discovery.interval.ms", "10000");
// discover new partitions per 10 seconds
Python文章来源地址https://www.toymoban.com/news/detail-647384.html
KafkaSource.builder() \
.set_property("partition.discovery.interval.ms", "10000")
# discover new partitions per 10 seconds
到了这里,关于Flink系列之:动态发现新增分区的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!