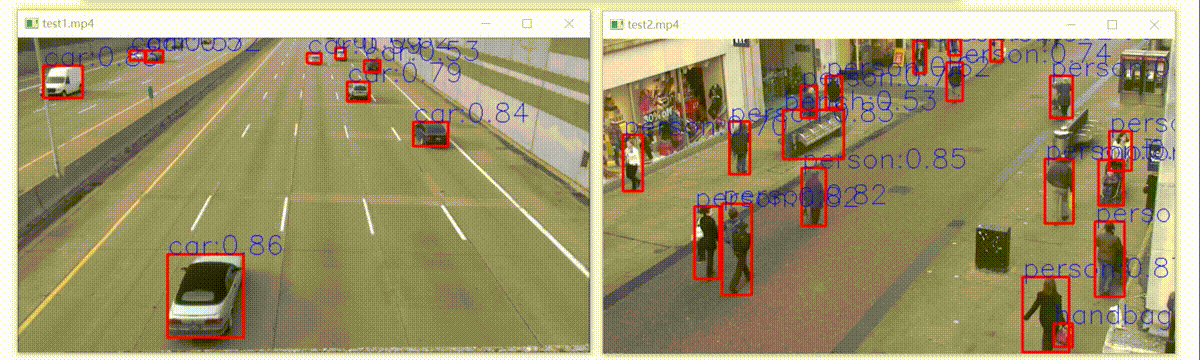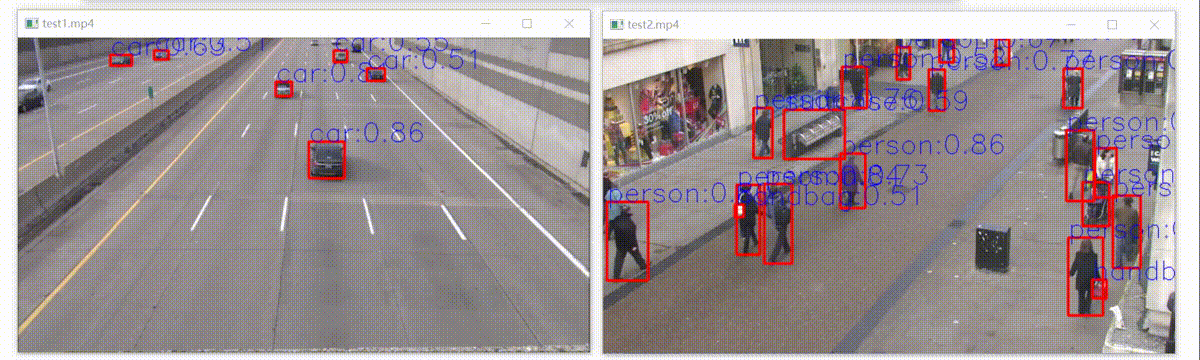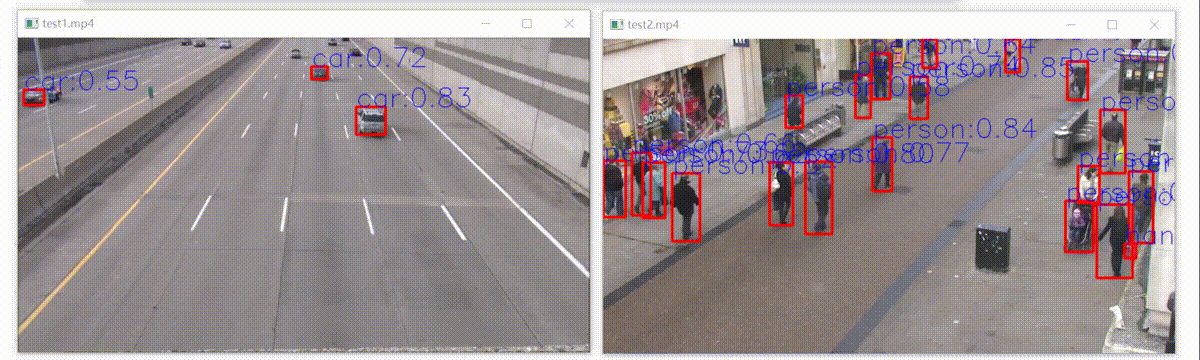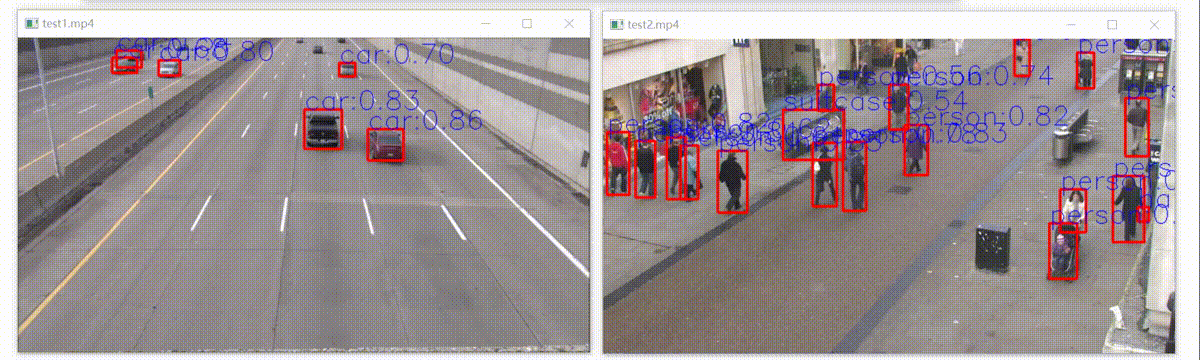
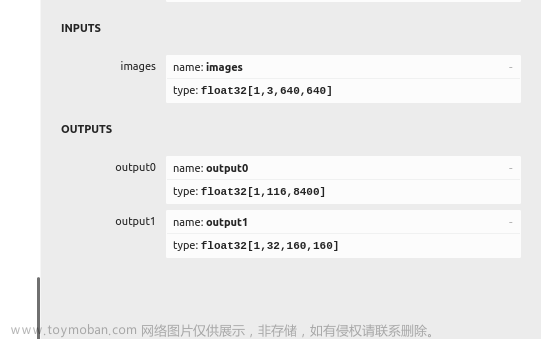
这里使用的yolov5 6.2,使用export.py很方便地得到onnx格式的模型。然后用onnxruntime推理框架在Python上进行部署。主要是为了测试模型的准确,模型部署的最终是用 C++ 部署,从而部署在嵌入式设备等。
整个代码分为四个部分:1、对输入进行预处理; 2、onnxruntime推理得到输出; 3、对输出进行后处理 4、画预测框
代码的难点是nms处理。代码尚存在的缺陷是,将输入图像处理至模型输入尺寸大小时没有使用等比例缩放,对效果可能有点影响。
代码中有详细注释,不懂的可以在下面留言。
import sys
import onnx
import onnxruntime as ort
import cv2
import numpy as np
CLASSES = ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush'] # coco80类别
class Yolov5ONNX(object):
def __init__(self, onnx_path):
# 检查模型
onnx_model = onnx.load(onnx_path)
try:
onnx.checker.check_model(onnx_model)
except Exception:
print("Model incorrect")
else:
print("Model correct")
# 使用GPU
# options = ort.SessionOptions()
# options.enable_profiling = True
# self.onnx_session = ort.InferenceSession(onnx_path, sess_options=options,
# providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
# 加载模型
self.onnx_session = ort.InferenceSession(onnx_path)
self.input_name = self.get_input_name() # ['images']
self.output_name = self.get_output_name() # ['output0']
def get_input_name(self):
"""获取输入节点名称"""
input_name = []
for node in self.onnx_session.get_inputs():
input_name.append(node.name)
return input_name
def get_output_name(self):
"""获取输出节点名称"""
output_name = []
for node in self.onnx_session.get_outputs():
output_name.append(node.name)
return output_name
def get_input_fedd(self, image_numpy):
"""获取输入numpy
得到这样形式的输入:
dict:{ input_name: input_value }
"""
input_feed = {}
for name in self.input_name:
input_feed[name] = image_numpy
return input_feed
def inference(self,img_path):
""" 1.cv2读取图像并resize
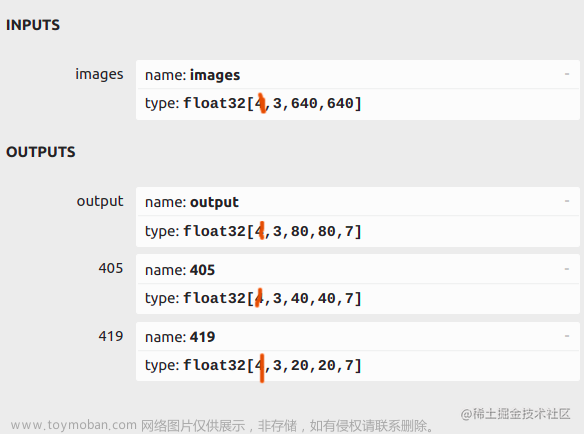
2.图像转BGR2RGB和HWC2CHW(因为yolov5的onnx模型输入为 RGB:1 × 3 × 640 × 640)
3.图像归一化
4.图像增加维度
5.onnx_session 推理 """
img = cv2.imread(img_path)
org_img = cv2.resize(img, [640, 640]) # resize后的原图 (640, 640, 3)
# img = org_img[:,:,::-1].transpose(2, 0, 1) # BGR2RGB和HWC2CHW
img = cv2.cvtColor(org_img, cv2.COLOR_BGR2RGB).transpose(2, 0, 1)
img = img.astype(dtype=np.float32) # onnx模型的类型是type: float32[ , , , ]
img /= 255.0;
img = np.expand_dims(img, axis=0) # [3, 640, 640]扩展为[1, 3, 640, 640]
# img尺寸(1, 3, 640, 640)
input_feed = self.get_input_fedd(img) # dict:{ input_name: input_value }
pred = self.onnx_session.run(None,input_feed)[0] # <class 'numpy.ndarray'>(1, 25200, 9)
return pred, org_img
# dets: array [x,6] 6个值分别为x1,y1,x2,y2,score,class
# thresh: 阈值
def nms(dets, thresh):
""" 看不懂注释的看这个博客:https://blog.csdn.net/a1103688841/article/details/89711120"""
#首先数据赋值和计算对应矩形框的面积
#dets的数据格式是dets[[xmin,ymin,xmax,ymax,scores]....]
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
areas = (y2 - y1 + 1) * (x2 - x1 + 1)
scores = dets[:, 4]
#这边的keep用于存放,NMS后剩余的方框
keep = []
#取出分数从大到小排列的索引。.argsort()是从小到大排列,[::-1]是列表头和尾颠倒一下。
index = scores.argsort()[::-1]
# index会剔除遍历过的方框,和合并过的方框。
while index.size > 0:
i = index[0] # 当前index列表第一个box的索引,当前框
# keep保留的是索引值,不是具体的分数。
keep.append(i)
#计算交集的左上角和右下角
#这里要注意,比如x1[i]这个方框的左上角x和所有其他的方框的左上角x的作比较,分别取最大值
x11 = np.maximum(x1[i], x1[index[1:]]) #
y11 = np.maximum(y1[i], y1[index[1:]])
x22 = np.minimum(x2[i], x2[index[1:]])
y22 = np.minimum(y2[i], y2[index[1:]])
#这边要注意,如果两个方框相交,X22-X11和Y22-Y11是正的。
#如果两个方框不相交,X22-X11和Y22-Y11是负的,我们把不相交的W和H设为0.
w = np.maximum(0, x22 - x11 + 1)
h = np.maximum(0, y22 - y11 + 1)
#计算重叠面积就是上面说的交集面积。不相交因为W和H都是0,所以不相交面积为0
overlaps = w * h
#这个就是IOU公式(交并比)。
#得出来的ious是一个列表,里面拥有当前方框和其他所有方框的IOU结果
ious = overlaps / (areas[i] + areas[index[index[1:]]] - overlaps)
#接下来是合并重叠度最大的方框,也就是合并ious中值大于thresh的方框
#我们合并的操作就是把他们剔除,因为我们合并这些方框只保留下分数最高的。
#我们经过排序当前我们操作的方框就是分数最高的,所以我们剔除其他和当前重叠度最高的方框
#这里np.where(ious<=thresh)[0]是一个固定写法。
idx = np.where(ious <= thresh)[0] # 留下来的框的索引的索引,注意当前框也在里面
#把留下来的框再进行NMS操作
#这边留下的框是去除当前操作的框,和当前操作的框重叠度大于thresh的框
# 每一次都会先去除当前操作框,所以索引的列表就会向前移动移位,要还原就+1,向后移动一位
index = index[idx + 1] # 确定留下的框的索引,并去除当前框的索引
return keep
def xywh2xyxy(x):
# [x, y, w, h] to [xmin, ymin, xmax, ymax]
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2
return y
def filter_box(org_box, conf_thres, iou_thres):
# 删除置信度小于conf_thres的BOX
org_box = np.squeeze(org_box) # 删除数组形状中单维度条目(shape中为1的维度),即batch维度
conf = org_box[..., 4] > conf_thres # # […,4]:代表了取最里边一层的所有第4号元素,…代表了对:,:,:,等所有的的省略。
box = org_box[conf == True]
print('box: 符合conf_thres要求的框')
print(box.shape)
# 每个框最大类别概率的索引(索引相对于80个类别)
cls_cinf = box[..., 5:] # 左闭右开,各类别的概率
cls = []
for i in range(len(cls_cinf)):
cls.append(int(np.argmax(cls_cinf[i]))) # 类别概率最大的索引
# 一共有多少个类别
all_cls = list(set(cls)) #set函数去重复, 可得到共有多少类别
# 每次对一个类别的框作如下操作:
# 1、获得该框的类别索引,即 x y w h score class
# 2、x y w h score class ---> xmin ymin xmax ymax score class
# 3、nms处理
output = []
for i in range(len(all_cls)): # 对于每个类别
curr_cls = all_cls[i]
curr_cls_box = []
curr_out_box = []
for j in range(len(cls)): # 对于每一个框
if cls[j] == curr_cls:
box[j][5] = curr_cls # 类别索引
curr_cls_box.append(box[j][:6]) # x y w h score class
curr_cls_box = np.array(curr_cls_box)
curr_cls_box = xywh2xyxy(curr_cls_box) # xmin ymin xmax ymax score class
curr_out_box = nms(curr_cls_box, iou_thres) # nms处理, 得到是curr_cls_box的索引
for k in curr_out_box:
output.append(curr_cls_box[k])
output = np.array(output)
print('box: nms处理后符合conf_thres要求的框')
print(output.shape)
return output
def draw(image, box_data):
boxes = box_data[...,:4].astype(np.int32) # 坐标取整
scores = box_data[..., 4]
classes = box_data[..., 5].astype(np.int32)
for box, score, cl in zip(boxes, scores, classes):
top , left, right, bottom = box
print('class:{}, score:{}'.format(CLASSES[cl], score))
# print('box coordinate left,top,right,down: [{}, {}, {}, {}]'.format(top, left, right, bottom))
cv2.rectangle(image, (top, left), (right, bottom), (255, 0, 0), 2)
cv2.putText(image, '{0} {1:.2f}'.format(CLASSES[cl], score),
(top, left),
cv2.FONT_HERSHEY_SIMPLEX,
0.6, (0,0,255), 2)
return image
if __name__ == "__main__":
onnx_path = './yolov5n.onnx'
model = Yolov5ONNX(onnx_path)
output, org_img = model.inference('/home/jason/work/01-img/dog2.png')
print(output.shape)
outbox = filter_box(output, 0.5, 0.5)
print('outbox( x1 y1 x2 y2 score class):')
print(outbox)
if len(outbox) == 0:
print("没有发现物体")
sys.exit(0)
org_img = draw(org_img, outbox)
cv2.imshow('result', org_img)
cv2.waitKey(0)
参考:
详细介绍 Yolov5 转 ONNX模型 + 使用ONNX Runtime 的 Python 部署(包含官方文档的介绍)_yolov5转onnx-CSDN博客YOLOV5模型转onnx并推理_yolov5转onnx_江小皮不皮的博客-CSDN博客文章来源:https://www.toymoban.com/news/detail-647405.html
NMS的python实现_nms python_a1103688841的博客-CSDN博客文章来源地址https://www.toymoban.com/news/detail-647405.html
到了这里,关于Yolov5 ONNX Runtime 的 Python 部署的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!