一、准备环境
docker search hadoop
docker pull sequenceiq/hadoop-docker
docker images
二、Hadoop集群搭建
1. 运行hadoop102容器
docker run --name hadoop102 -d -h hadoop102 -p 9870:9870 -p 19888:19888 -v /opt/data/hadoop:/opt/data/hadoop sequenceiq/hadoop-docker
docker exec -it hadoop102 bash #进入该容器
ssh-keygen -t rsa #生成密钥,一直回车,有一个根据提示输入y
cd /root/.ssh/ && cat id_rsa.pub > authorized_keys #复制公钥到authorized_keys中
cat authorized_keys #复制到其他文档中保存
2. 运行hadoop103容器
docker run --name hadoop103 -d -h hadoop103 -p 8088:8088 sequenceiq/hadoop-docker
docker exec -it hadoop103 bash #进入该容器
ssh-keygen -t rsa #生成密钥
cd /root/.ssh/ && cat id_rsa.pub > authorized_keys #复制公钥到authorized_keys中
cat authorized_keys #复制到其他文档中保存
3. 运行hadoop104容器
docker run --name hadoop104 -d -h hadoop104 sequenceiq/hadoop-docker
docker exec -it hadoop104 bash #进入该容器
ssh-keygen -t rsa #生成密钥
cd /root/.ssh/ && cat id_rsa.pub > authorized_keys #复制公钥到authorized_keys中
cat authorized_keys #复制到其他文档中保存
4.将三个密钥全部复制到authorized_keys文件
vi authorized_keys #将hadoop102 hadoop103 hadoop104复制到这一个文件中,在hadoop102 hadoop103 hadoop104中都保存起来
cat > authorized_keys << EOF
ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAx01kz5PaWIU/oV7AuBZkiwQ52EVO61GDgRCsNUQd7GgdFKpCENCbDIRP9IvAumN0rdxloxQd2WMaEWTycHfeu8tsECihb4iIywDSx1XiQHrik+CUBPggCWdzJknZQgNSmMGRd4129r1bJO8lra100QoK/YpSYQY7Odapd1dg3dhrcEf2D59a/gvX8yHnYkBAuFNAm/HXijTNHq5TezoIOo63WT9BCWTQ4DLBmLdIZsOrZzHkNJCFpRgHTbEGX+h0vzqXhGXlkA9IMdrwFuAc5lTuazK9wwXgjmAq9M38Zh3ithr/LYB2VaHyUCXzNB44e1fGQ8+O946XerO8IO8r9w== root@hadoop102
ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAyctJZBLE1pktU8jv2983inSZazyV0v49Dpzt6+z9K3E5JlBuNvM806mMzLhvta+eXnu7Th70fE20vUNukrjRCpZUv/zxzuKKadSLr76xQEsjP/ZnmUVsJfJU4Q/ThRR32TiDRDdnCf0nM/pi/eXePrbgZLxMNd2+r0o65++th6mDMV8Y/lGAxGBYIAsI3xJwEx+6/Ok9h5AlvtEezKWkI6JhpEjpTwncVEdk16vR8WJ51JsnYwszSenRmyOFmcT+O7qU0phpy/FvwlDzDen54nrssqj1vB+yhlkCdlfLN5PQ5nJIPE0sAwTxaFOLqEbLf1mLrtO9iTx+UwboGCxoRQ== root@hadoop103
ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAz7cQxzbxJoFMWVchuFdcCDY3nD8jb4lRZPTH+5+J4iFP1vEIADj18rMlfQy/d+c+v3XrFfNVvlrawKFVals5LcfVd97eEEX1g2KRxsM07aqPibVYGwturFpiu3pFKwI9j2hYwa4uWVM+5VCR49sgAxHce4jmlf/ZpLz5FxxqVYyRvQ3GoN8KsqDH7CwDyqnbgnrgJw7RE0d7nVOdfgXif1VXPPjPTzRUxMJKtyP1Ja+Sym/sxRJwOuEGEqNCg6WHYZ4OFArtWKMliDv3hRCUvJK9LlWu9+aeCHGrA6qJApaQ/vAOdzsSBj1IGzgDttYO4uxNkQavwazw/DHtRA9swQ== root@hadoop104
EOF
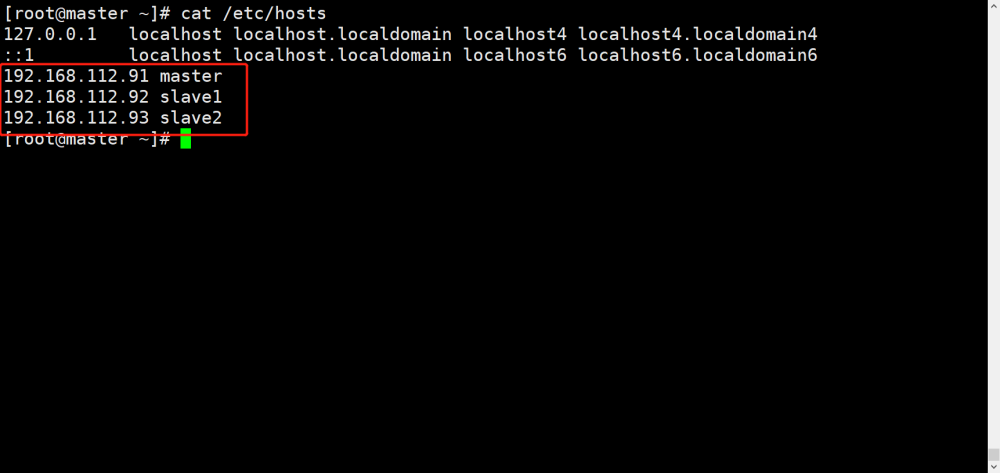
5. 配置地址映射
cat >> /etc/hosts << EOF
172.17.0.2 hadoop102 #ip是容器的IP
172.17.0.3 hadoop103 #ip是容器的IP
172.17.0.4 hadoop104 #ip是容器的IP
EOF
6.检查ssh是否成功
#在hadoop102 hadoop103 hadoop104都测试
ssh hadoop102
ssh hadoop103
ssh hadoop104
三、配置Hadoop
hadoop目录安装在:/usr/local/hadoop-2.7.0/etc/hadoop
1. core-site.xml
#在hadoop102容器中执行
cd /usr/local/hadoop-2.7.0/etc/hadoop
cat > core-site.xml << EOF
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
EOF
2. hdfs-site.xml
#在hadoop102容器中执行
cd /usr/local/hadoop-2.7.0/etc/hadoop
cat > hdfs-site.xml << EOF
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
</configuration>
EOF
3. yarn-site.xml
#在hadoop102容器中执行 注意:还有其他需要编辑
cd /usr/local/hadoop-2.7.0/etc/hadoop
vi yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
4. mapred-site.xml
cd /usr/local/hadoop-2.7.0/etc/hadoop
cat > mapred-site.xml << EOF
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
EOF
5. 分发文件
cd /usr/local/hadoop-2.7.0/etc/hadoop
scp /usr/local/hadoop-2.7.0/etc/hadoop/core-site.xml hadoop103:/usr/local/hadoop-2.7.0/etc/hadoop
scp /usr/local/hadoop-2.7.0/etc/hadoop/hdfs-site.xml hadoop103:/usr/local/hadoop-2.7.0/etc/hadoop
scp /usr/local/hadoop-2.7.0/etc/hadoop/yarn-site.xml hadoop103:/usr/local/hadoop-2.7.0/etc/hadoop
scp /usr/local/hadoop-2.7.0/etc/hadoop/core-site.xml hadoop104:/usr/local/hadoop-2.7.0/etc/hadoop
scp /usr/local/hadoop-2.7.0/etc/hadoop/hdfs-site.xml hadoop104:/usr/local/hadoop-2.7.0/etc/hadoop
scp /usr/local/hadoop-2.7.0/etc/hadoop/yarn-site.xml hadoop104:/usr/local/hadoop-2.7.0/etc/hadoop
四、启动集群
1. 配置slaves文件
cd /usr/local/hadoop-2.7.0/etc/hadoop
cat > slaves << EOF
hadoop102
hadoop103
hadoop104
EOF
2. 发送到其他节点
scp /usr/local/hadoop-2.7.0/etc/hadoop/slaves hadoop103:/usr/local/hadoop-2.7.0/etc/hadoop
scp /usr/local/hadoop-2.7.0/etc/hadoop/slaves hadoop104:/usr/local/hadoop-2.7.0/etc/hadoop
3. 格式化文件系统
cd /usr/local/hadoop-2.7.0/bin
./hadoop namenode -format
4. 在hadoop102启动hdfs
cd /usr/local/hadoop-2.7.0/sbin
./start-all.sh
5. 在hadoop103启动yarn
cd /usr/local/hadoop-2.7.0/sbin
./start-yarn.sh
6.访问验证
#关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
#关闭selinux
sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久
setenforce 0 # 临时
sysctl net.ipv4.ip_forward #启用IP_FORWARD
systemctl restart docker
docker start hadoop102 hadoop103 hadoop104
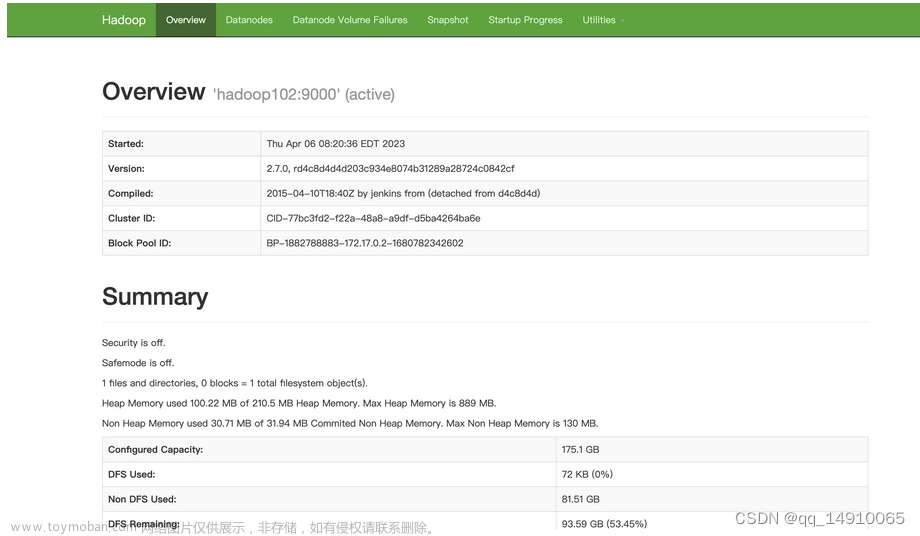
访问Hadoop102:9870,查看是否能够看到hdfs界面
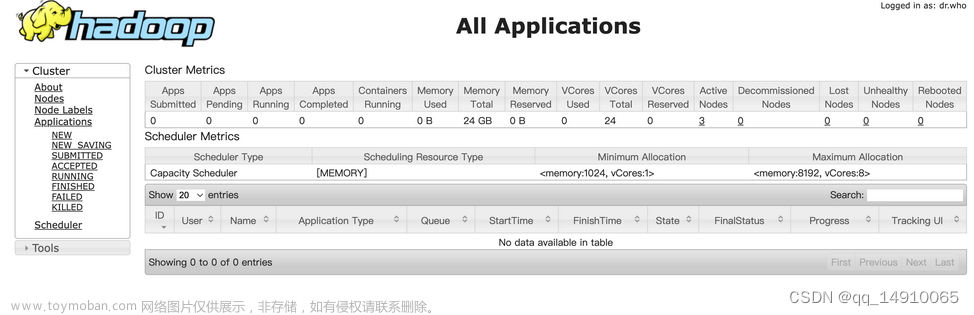
访问hadoop103:8088,查看能够看到yarn界面
 文章来源:https://www.toymoban.com/news/detail-647436.html
文章来源:https://www.toymoban.com/news/detail-647436.html
五 案例
1. 执行一些hdfs命令
cat >> /root/.bashrc << EOF
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
EOF
source /root/.bashrc
hadoop fs -ls /
hadoop fs -mkdir /hadoop
hadoop fs -ls /
2. 上传文件到hdfs上
hadoop fs -put word.txt /hadoop
hadoop fs -ls /hadoop
3. 执行wordcount案例
cd /usr/local/hadoop
./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar wordcount /hadoop/word.txt /output
在yarn上可以看到执行情况
 文章来源地址https://www.toymoban.com/news/detail-647436.html
文章来源地址https://www.toymoban.com/news/detail-647436.html
五、关闭集群
#hadoop102上
stop-dfs.sh
#hadoop103上:
stop-yarn.sh
到了这里,关于Docker安装Hadoop分布式集群的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!