【python】 油管外挂字幕下载位srt文本文件
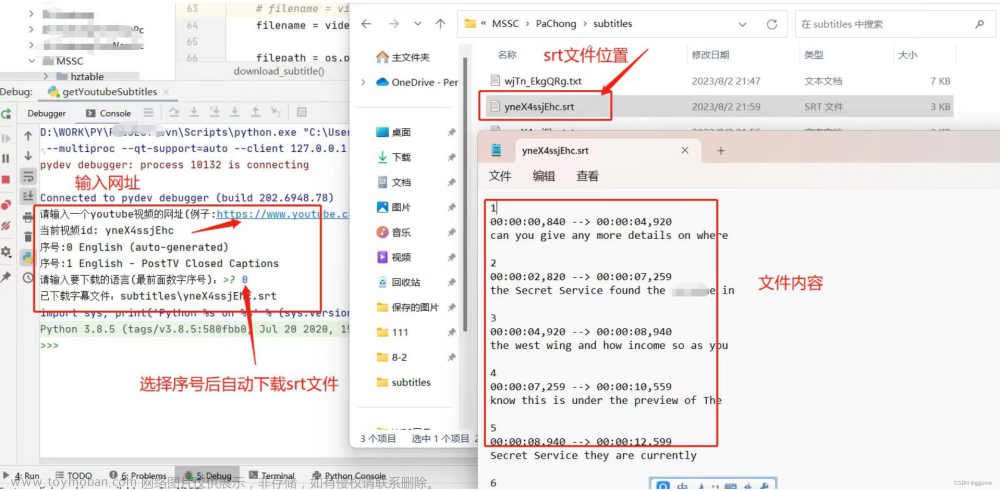
案例截图
 文章来源:https://www.toymoban.com/news/detail-647450.html
文章来源:https://www.toymoban.com/news/detail-647450.html
案例代码
# python程序,可以下youtube视频的字幕文件。输入一个视频的url,就会下载它的字幕文件到一个文件夹里。
# Author WeChat:****请私信,
# Date:2023-8-2,
# Email:ack1024#hotmail.com
# 本软件遵循 Apache License 2.0协议
# 导入需要的模块
import json
import math
import time
import requests
import re
import os
import xml.etree.ElementTree as ElementTree
from html import unescape
# 梯子
proxies = {
"http": "http://127.0.0.1:10809",
"https": "http://127.0.0.1:10809",
}
# 请求头
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'
}
# 定义一个函数,根据视频的url获取字幕的url
def get_subtitle_url(video_url):
# 发送请求,获取视频页面的源码
response = requests.get(video_url, proxies=proxies, headers=headers)
html = response.text
# 用正则表达式匹配字幕的url
match = re.search(pattern, html)
if match:
# 如果找到了字幕的url,返回它
subtitle_url = match.group(1)
return subtitle_url
else:
# 如果没有找到字幕的url,返回None
return None
# 定义一个函数,根据字幕的url下载字幕文件
def download_subtitle(subtitle_url, video_id):
# 发送请求,获取字幕的内容
response = requests.get(subtitle_url, proxies=proxies, headers=headers)
content = response.text
# 用正则表达式去掉不需要的标签
content = xml_caption_to_srt(content)
# 创建一个文件夹,用于存放字幕文件
folder = 'subtitles'
if not os.path.exists(folder):
os.mkdir(folder)
filename = video_id + '.srt'
filepath = os.path.join(folder, filename)
with open(filepath, 'w', encoding='utf-8') as f:
f.write(content)
print('已下载字幕文件:' + filepath)
# 根据视频的url下载视频的字幕文件
def download_video_subtitle(video_url):
video_id = video_url.split('=')[-1]
print('当前视频id:',video_id)
# 调用函数,获取字幕的url
subtitle_url = get_subtitle_url(video_url)
if not subtitle_url:
# 如果没有字幕的url,打印提示信息
print('该视频没有字幕')
exit(0)
subtitle_url = '[' + subtitle_url + ']'
subtitle_urlDics = json.loads(subtitle_url)
strp = ['序号:' + str(i) + ' ' + subtitle_urlDics[i]['name']['simpleText'] for i in range(len(subtitle_urlDics))]
for i in strp:
print(i)
choiceIndex = int(input('请输入要下载的语言(最前面数字序号):'))
subtitle_url = subtitle_urlDics[choiceIndex]['baseUrl']
if subtitle_url:
# 如果有字幕的url,调用函数,下载字幕文件
download_subtitle(subtitle_url, video_id)
else:
# 如果没有字幕的url,打印提示信息
print('该视频没有字幕')
def xml_caption_to_srt(xml_captions: str) -> str:
segments = []
root = ElementTree.fromstring(xml_captions)
for i, child in enumerate(list(root)):
caption = unescape(text.replace("\n", " ").replace(" ", " "), )
try:
duration = float(child.attrib["dur"])
except KeyError:
duration = 0.0
start = float(child.attrib["start"])
end = start + duration
sequence_number = i + 1 # convert from 0-indexed to 1.
line = "{seq}\n{start} --> {end}\n{text}\n".format(
seq=sequence_number,
start=float_to_srt_time_format(start),
end=float_to_srt_time_format(end),
text=caption,
)
segments.append(line)
return "\n".join(segments).strip()
def float_to_srt_time_format(d: float) -> str:
time_fmt = time.strftime("%H:%M:%S,", time.gmtime(whole))
ms = f"{fraction:.3f}".replace("0.", "")
return time_fmt + ms
# 输入一个视频的url,下载它的字幕文件
if __name__ == '__main__':
while True:
video_url = input('请输入一个youtube视频的网址(例子:https://www.youtube.com/watch?v=wjTn)先复制再回来右击即可:')
# video_url = "https://www.youtube.com/watch?v=wjTn_Ek"
download_video_subtitle(video_url)
if input('请输入0退出:') == 0:
exit(0)
以上为部分代码哈! 隐藏的都是正则部分,会Python的都能自己补全哈!超简单的文章来源地址https://www.toymoban.com/news/detail-647450.html
到了这里,关于【python】 油管外挂字幕下载位srt歌词字幕文本文件的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!