hive使用文件方式批量导入数据
1. 创建表,确定分隔符,换行符:
CREATE TABLE test(
id int,
name STRING,
tel STRING
)ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
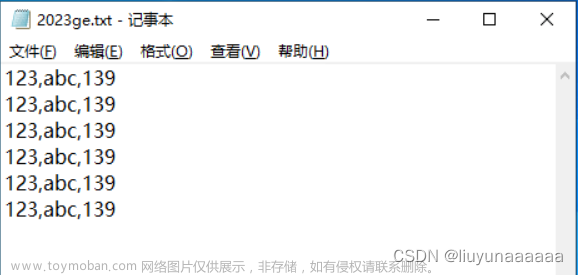
2. 编写数据文件:
3. 查看此表所在路径:describe extended 表名;
describe extended test;

4. 将本地生成好的数据上传至服务器
5. 将生成的txt文件put进HDFS集群
hadoop fs -put /home/hadoop/2023ge.txt /hive/warehouse/mdp_uat.db/test
-
/hive/warehouse/mdp_uat.db/test : 集群路径,第三部查询到的表路径(提前使用 hadoop fs -ls 查看下路径,确认路径正确);
-
/home/hadoop/2023ge.txt :本地路径;文章来源:https://www.toymoban.com/news/detail-647538.html
6. 将数据文件导入到表里
注意单引号;文章来源地址https://www.toymoban.com/news/detail-647538.html
在hive执行:
load data inpath '集群中存放事先已经生成好的txt路径,不需要文件名,指定到目录层级即可' into table 目标表名称;
load data inpath '/hive/warehouse/mdp_uat.db/test' into table test;
7. 验证数据是否导入成功
如果数据量大的话,最好不要全部查出来,使用limit 查询部分数据;
select * from test limit 10;
到了这里,关于hive使用文件方式批量导入数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!