机器学习 | Python实现KNN(K近邻)模型实践
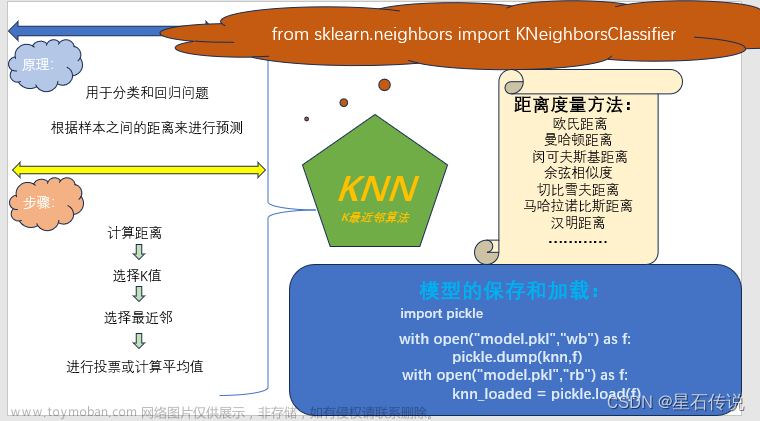
基本介绍
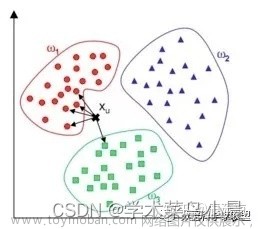
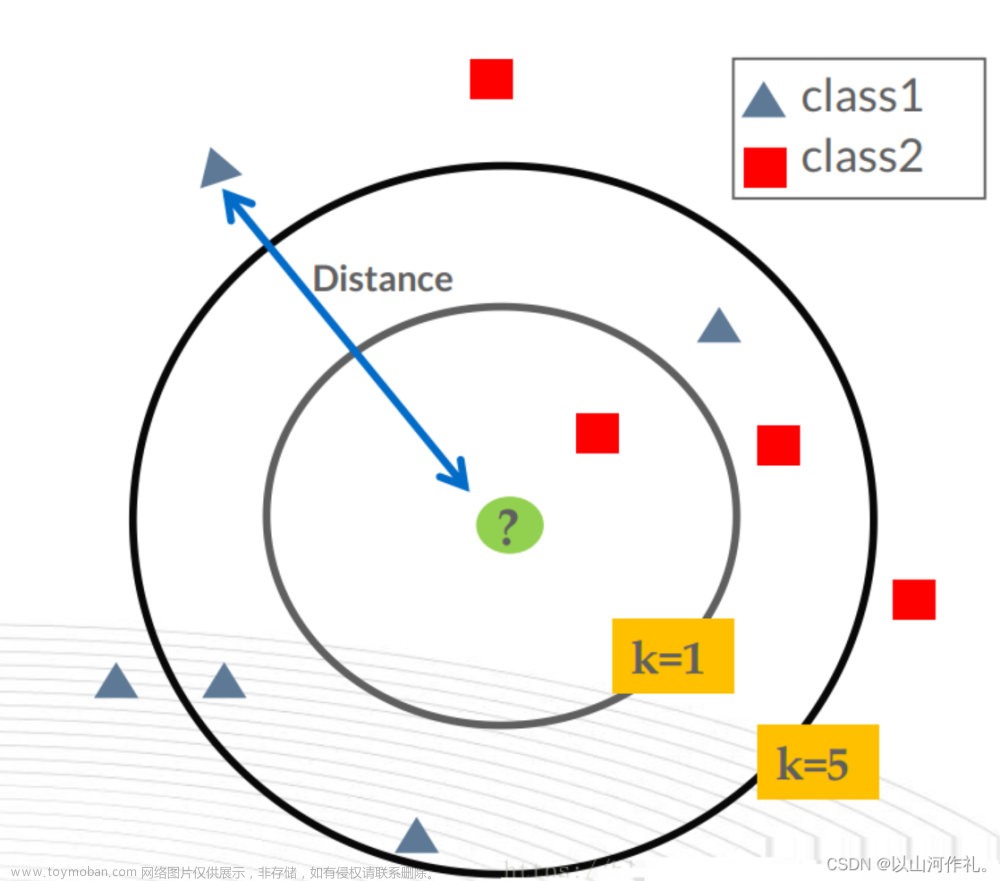
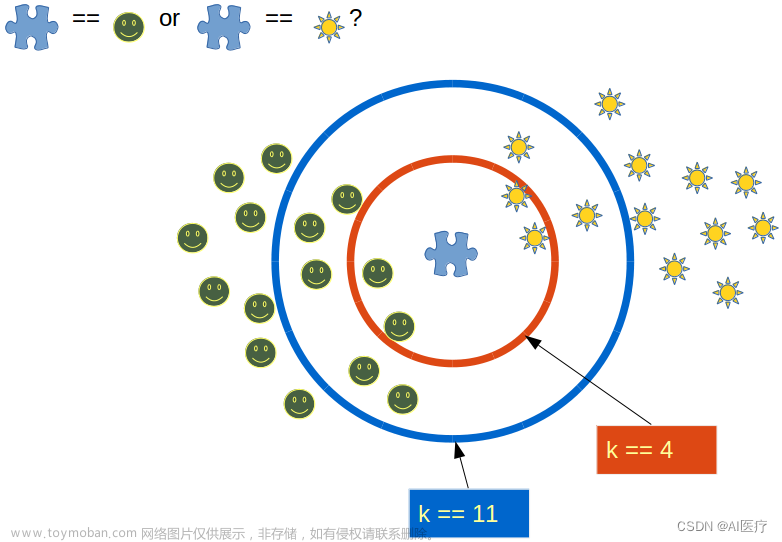
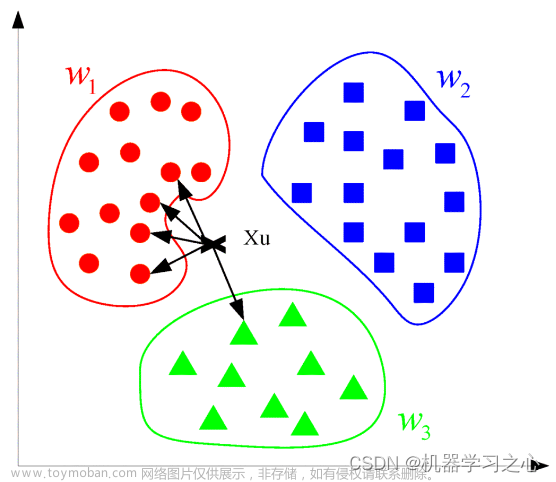
一句话就可以概括出KNN(K最近邻算法)的算法原理:综合k个“邻居”的标签值作为新样本的预测值。更具体来讲KNN分类过程,给定一个训练数据集,对新的样本Xu,在训练数据集中找到与该样本距离最邻近的K(下图k=5)个样本,以这K个样本的最多数所属类别(标签)作为新实例Xu的预测类别。
 文章来源:https://www.toymoban.com/news/detail-647609.html
文章来源:https://www.toymoban.com/news/detail-647609.html
模型原理
- 距离度量
KNN算法用距离去度量两两样本间的临近程度,最终为新实例样本文章来源地址https://www.toymoban.com/news/detail-647609.html
到了这里,关于机器学习 | Python实现KNN(K近邻)模型实践的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!