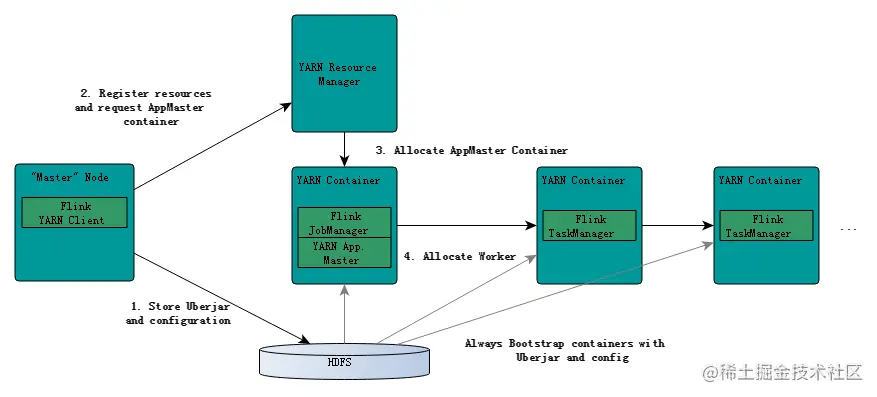
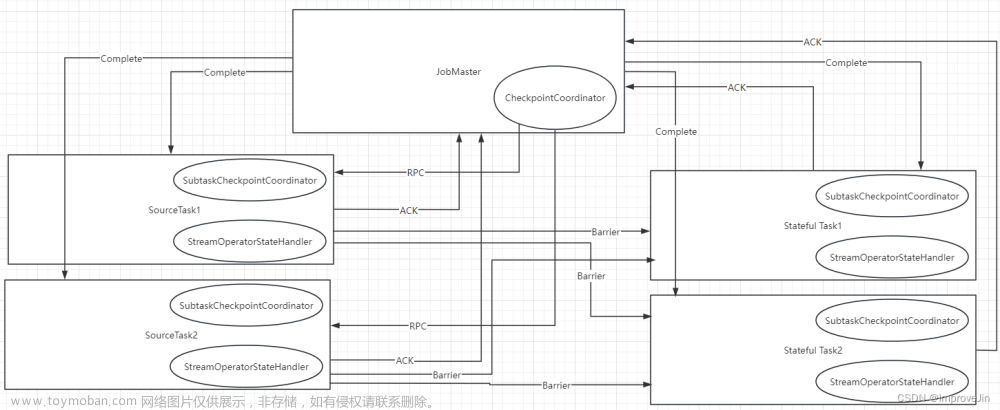
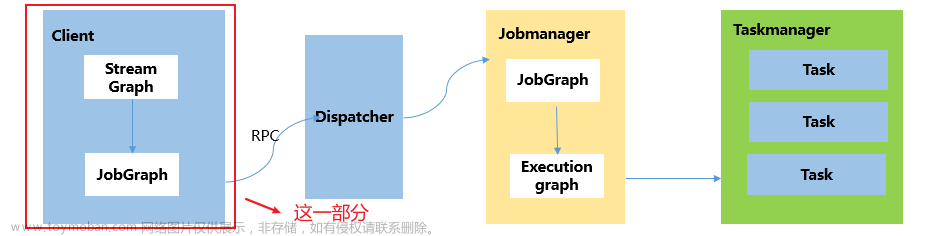
Flink中Graph转换流程如下:
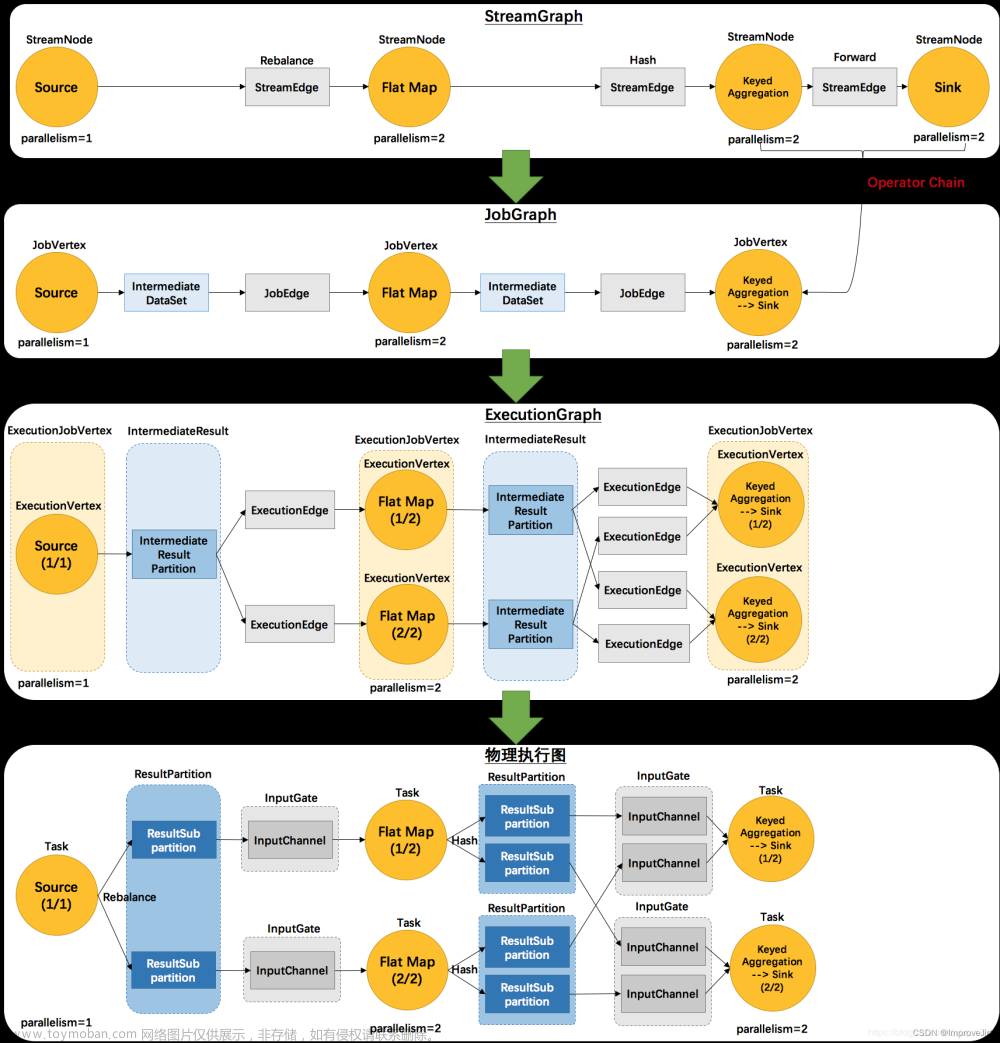
Flink Job提交时各种类型Graph转换流程中,JobGraph是Client端形成StreamGraph后经过Operator Chain优化后形成的,然后提交给JobManager的Restserver,最终转发给JobManager的Dispatcher处理。
CompletableFuture<Acknowledge> submitJob(JobGraph jobGraph, @RpcTimeout Time timeout);
本文主要解析从JobGraph转换为ExecutionGraph过程,执行栈如下:
Dispacher::submitJob
Dispacher::internalSubmitJob
Dispacher::persistAndRunJob
Dispacher::runJob
Dispacher::createJobManagerRunner
JobMasterServiceLeadershipRunnerFactory::createJobManagerRunner
JobMasterServiceLeadershipRunner:start
JobMasterServiceLeadershipRunner::grantLeadership
JobMasterServiceLeadershipRunner::startJobMasterServiceProcessAsync
JobMasterServiceLeadershipRunner::verifyJobSchedulingStatusAndCreateJobMasterServiceProcess
JobMasterServiceLeadershipRunner::createNewJobMasterServiceProcess
DefaultJobMasterServiceProcessFactory::create
DefaultJobMasterServiceProcess::new
DefaultJobMasterServiceFactory::createJobMasterService
DefaultJobMasterServiceFactory::internalCreateJobMasterService //创建JobMaster并调用其start
JobMaster::new //调用DefaultSlotPoolServiceSchedulerFactory::createScheduler
DefaultSlotPoolServiceSchedulerFactory::createScheduler //根据调度模式选择调度器
DefaultSchedulerFactory::createInstance //创建SchedulerNG
DefaultScheduler::new //
SchedulerBase::new
SchedulerBase::createAndRestoreExecutionGraph
DefaultExecutionGraphFactory::createAndRestoreExecutionGraph
DefaultExecutionGraphBuilder.buildGraph//在此会将JobGraph转换为ExecutionGraph
DefaultExecutionGraph::new
DefaultExecutionGraph::attachJobGraph //创建ExecutionJobVertex
DefaultExecutionTopology.fromExecutionGraph //创建ExecutionTopology
DefaultExecutionGraph::enableCheckpointing //创建CheckpointCoordinator
CheckpointCoordinator::new
PipelinedRegionSchedulingStrategy.Factory.createInstance //创建PipelinedRegionSchedulingStrategy
JobMaster::start
JobMaster::onStart
JobMaster::startJobExecution
JobMaster::startJobMasterServices //获取RM地址后与RM建立连接
JobMaster::startScheduling
SchedulerBase::startScheduling
DefaultScheduler::startSchedulingInternal
PipelinedRegionSchedulingStrategy::startScheduling
PipelinedRegionSchedulingStrategy::maybeScheduleRegions
DefaultScheduler::allocateSlotsAndDeploy
DefaultScheduler::allocateSlots
SlotSharingExecutionSlotAllocator::allocateSlotsFor //分配Slot
DefaultScheduler::waitForAllSlotsAndDeploy
DefaultScheduler::assignAllResourcesAndRegisterProducedPartitions
DefaultScheduler::assignResource //为每个Execution分配Slot
DefaultScheduler::registerProducedPartitions
DefaultScheduler::deployAll
DefaultScheduler::deployOrHandleError
DefaultScheduler::deployTaskSafe
DefaultExecutionVertexOperations::deploy
ExecutionVertex::deploy
Execution::deploy //提交任务向TM提交Deploymen
TaskManagerGateway.submitTask
在整个提交过程中,首先获取JobMasterService的Leader权限,然后对一个JobGraph生成一个JobMaster,JobMaster先将JobGraph转换为ExecutionGraph,转换核心逻辑在DefaultExecutionGraph::attachJobGraph方法中,最后为每个Execution申请Slot资源,对每个Execution向TM提交TaskDeploymentDescriptor调度执行。
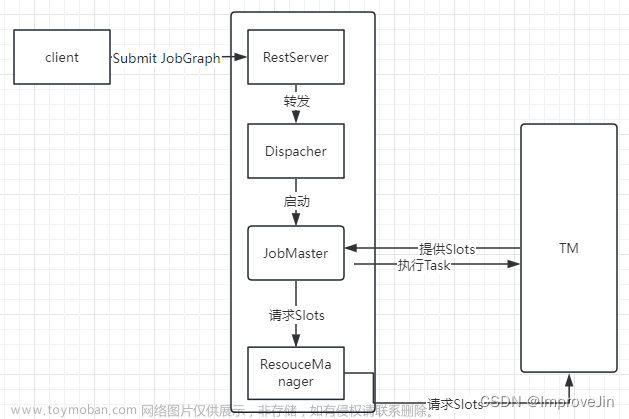
JobMaster管理整个Job的生命周期,主要有以下功能:文章来源:https://www.toymoban.com/news/detail-647701.html
- 将JobGraph转换为ExecutionGraph,创建调度器调度执行
- 通过心跳保持与ResourceManager的连接,为当前Job向RM申请Slot资源
- 接受TaskManager的OfferSlot, 向TM提交task, 主动发送心跳请求保持与执行当前Job的TM的连接
- 创建CheckpointCoordinator,触发Checkpoint
Flink中可通过jobmanager.scheduler配置调度类型,默认为NG:文章来源地址https://www.toymoban.com/news/detail-647701.html
NG:new generation scheduler
Adaptive: adaptive scheduler; supports reactive mode
到了这里,关于Flink源码之JobMaster启动流程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!