hiveserver2服务
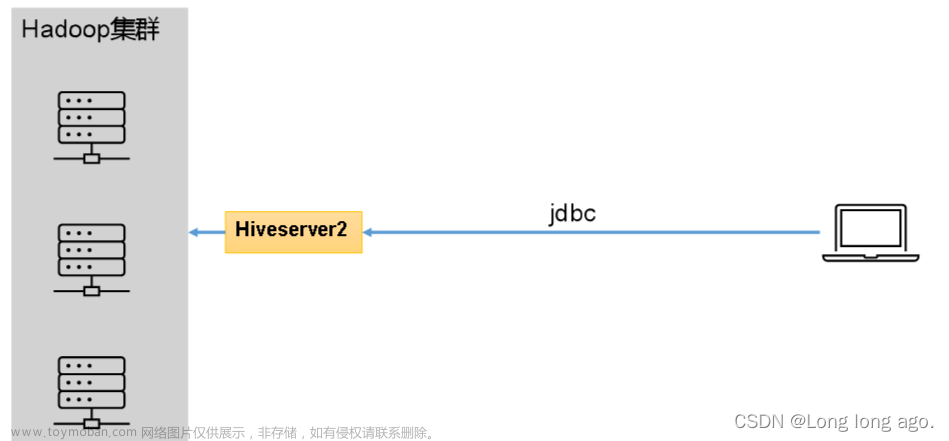
hiveserver2提供JDBC/ODBC接口,使得用户可以远程访问Hive数据,即作为客户端的代理与Hadoop集群进行交互。
hiveserver2部署时需要部署到一个能访问集群的节点上,保证能够直接往Hadoop上提交数据。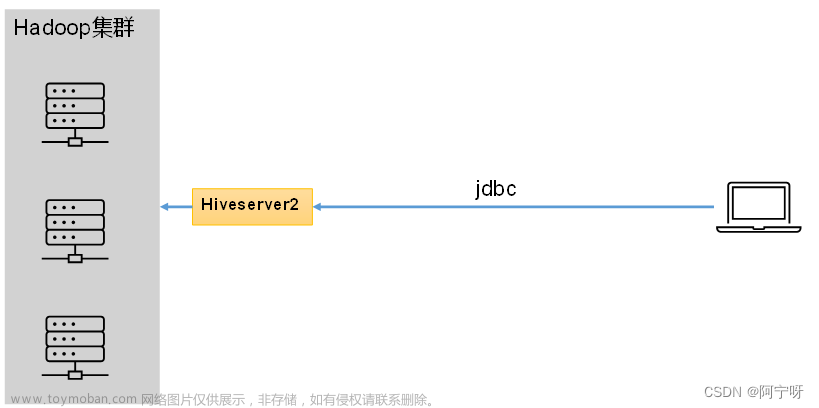
用户在客户端提交SQL语句时,由hiveserver请求HDFS或者提交计算任务到Yarn上,再由hiveserver2将结果返回给客户端。
(1)用户说明:
用户即由hiveserver2代理进行远程访问Hadoop集群的用户。
因为Hadoop集群中的数据由访问权限控制,设置了hive.server2.enable.doAs(表示是否启用Hiveserver2用户模拟功能)参数控制访问Hadoop集群的用户身份。
参数value值为true时启用(默认开启),即Hiveserver2会模拟客户端的登录用户访问Hadoop集群;参数value值为fault时,会直接使用Hiveserver2进程的启动用户访问Hadoop集群数据。
未开启用户模拟功能: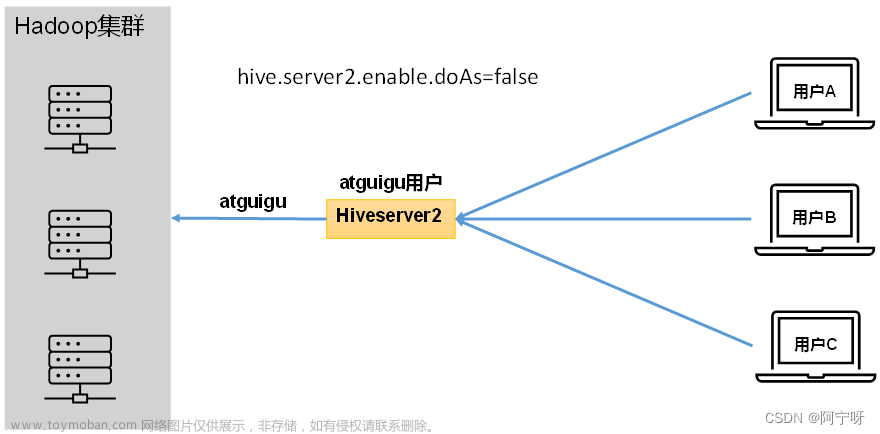
因为没启用用户模拟功能,所以在用户登录使用时,都是由Hiveserver2的启动进程的用户与Hadoop集群进行交互。
开启用户模拟功能:
在开启用户模拟时,用户登录,Hiveserver会模拟登录的用户与Hadoop集群进行交互。
在生产环境中要启用用户模拟功能,只有开启用户模拟功能之后才能保证用户的权限隔离。
(2)Hiveserver2部署
(i)Hadoop端配置
hivesever2的模拟用户功能,依赖于Hadoop提供的proxy user(代理用户功能),只有Hadoop中的代理用户才能模拟其他用户的身份访问Hadoop集群。
需要将hiveserver2的启动用户设置为Hadoop的代理用户。
Hadoop中的core-site.xml中添加,之后分发文件并重启集群:
cd HADOOP_HOME/etc/hadoop
vim core-site.xml
#添加以下
<!--配置所有节点(host节点)的liaoyanxia用户都可作为代理用户,value为具体节点的主机-->
<property>
<name>hadoop.proxyuser.liaoyanxia.hosts</name>
<value>*</value>
</property>
<!--配置liaoyanxia用户能够代理的用户组为任意组-->
<property>
<name>hadoop.proxyuser.liaoyanxia.groups</name>
<value>*</value>
</property>
<!--配置liaoyanxia用户能够代理的用户为任意用户-->
<property>
<name>hadoop.proxyuser.liaoyanxia.users</name>
<value>*</value>
</property>
(ii)Hive端配置
hive-site.xml中添加:
cd HIVE_HOME/conf
vim hive-site.xml
#添加以下:
<!-- 指定hiveserver2连接的host(hive用户要绑定的网络接口) -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
(3)测试
(i)启动hiveserver2:
使用nohup启动hiveserver2进程,避免在断开连接进程挂断;”&”表示在后台运行;”1”表示标准输出,即表示hiveserver2的标准输出都重定位写到/div/nu中,”0”表示标准输入,”2”表示标准错误输出:
nohup bin/hiveserver2 1>/home/liaoyanxia/div/out 2>/home/liaoyanxia/div/out &
以上可以简化为(表示标准输出和标准错误输出重定位到同一个地址):
nohup bin/hiveserver2 1>/home/liaoyanxia/div/out 2>&1 &
也可以简化为(省略前面的1即默认表示的是标准输出):
nohup bin/hiveserver2 >/home/liaoyanxia/div/out 2>&1 &
用jps可以看到RunJar进程,表示hiveserver2启动成功。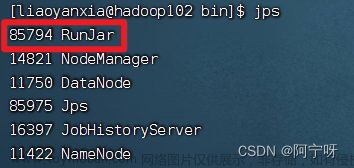
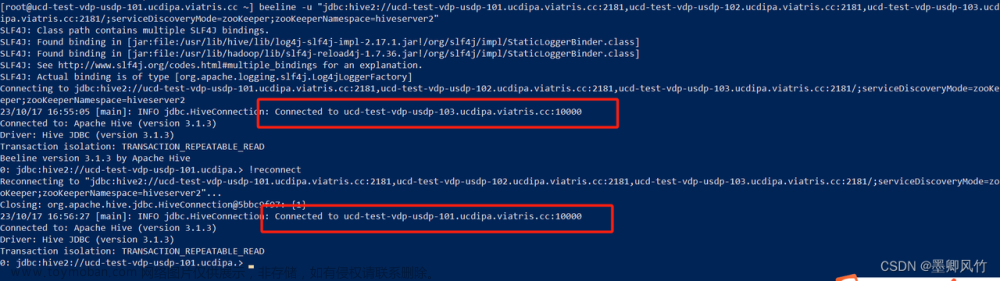
(ii)使用命令行客户端beeline进行远程访问:
启动beeline客户端:
cd /HIVE_HOME/bin
beeline
由于采用的是jdbc协议,所以需要连接到HQL,进入到beeline客户端后:
beeline>!connect jdbc:hive2://hadoop102:10000
#然后提示输入用户名,该用户名是作为hiveserver2访问集群的用户
#因为没启用身份认证功能,所以提示的密码可以不填

进入到hiveserver2,可以执行sql语句:
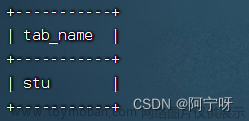
0;jdbc:hive2//hadoop102:10000>show tables;
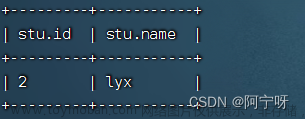
0;jdbc:hive2//hadoop102:10000>select * from stu;
0;jdbc:hive2//hadoop102:10000>!quit
(iii)用Datagrip图形化客户端进行远程访问:
需要先开启hiveserver2服务。文章来源:https://www.toymoban.com/news/detail-647707.html
nohup bin/hiveserver2 >/home/liaoyanxia/div/out 2>&1 &
创建Datagrip连接: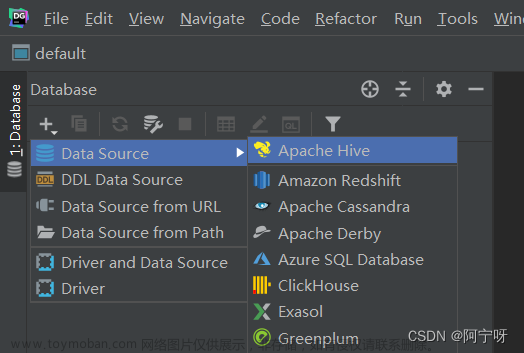
配置连接属性:所有属性配置,和Hive的beeline客户端配置一致,初次使用,配置过程会提示缺少JDBC驱动,按照提示下载。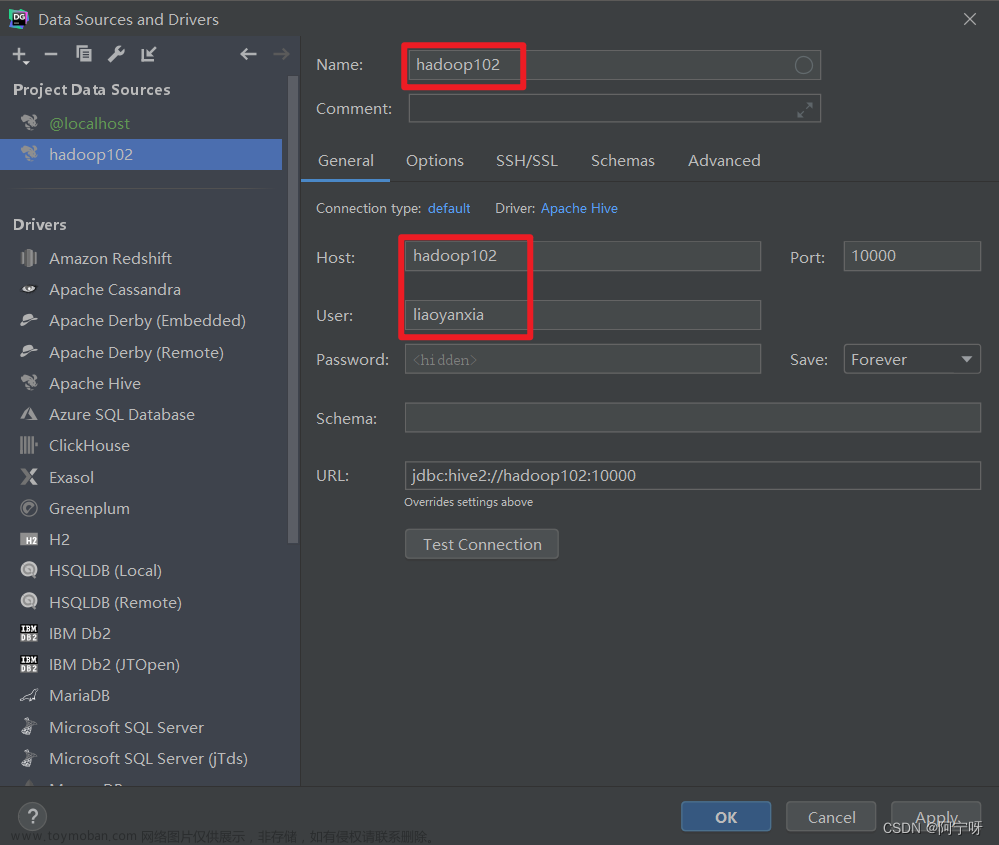
测试sql执行: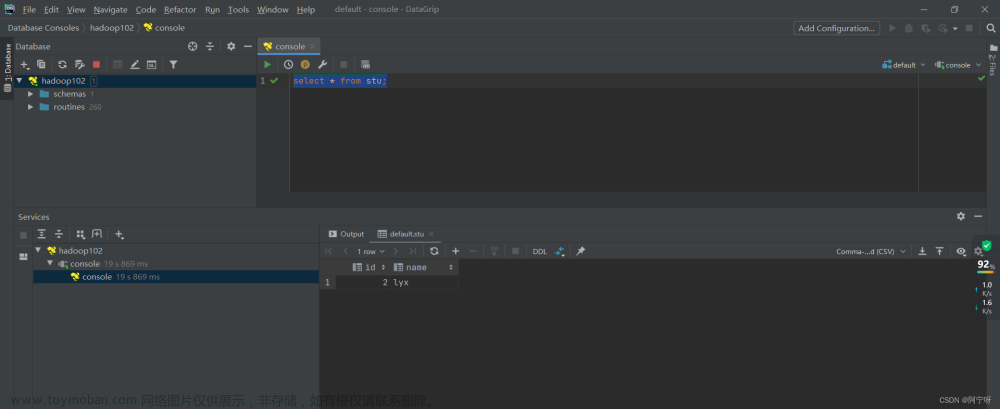 文章来源地址https://www.toymoban.com/news/detail-647707.html
文章来源地址https://www.toymoban.com/news/detail-647707.html
到了这里,关于【大数据之Hive】五、Hiveserver2服务部署的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!