ChatGLM2-6B 介绍
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
- 1.更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
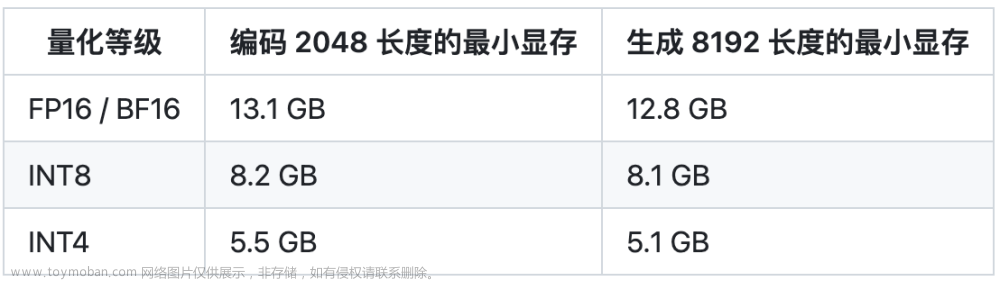
- 2.更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
- 3.更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
- 4.更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在获得官方的书面许可后,亦允许商业使用。
来源:https://github.com/THUDM/ChatGLM2-6B
ChatGLM2微调问题
执行微调命令:
cd ChatGLM2-6B/ptuning
sh train.sh
错误信息:
Traceback (most recent call last):
File "main.py", line 391, in
main()
File "main.py", line 119, in main
model.transformer.prefix_encoder.float()
File "/usr/local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1269, in getattr
raise AttributeError("'{}' object has no attribute '{}'".format(
AttributeError: 'ChatGLMModel' object has no attribute 'prefix_encoder'
重要报错信息:
AttributeError: 'ChatGLMModel' object has no attribute 'prefix_encoder'
解决方法
1.安装 transformers 版本
pip install transformers==4.30.2
2.重新下载 THUDM/chatglm2-6b 中的文件
文件列表:
# ls -lh ./THUDM/chatglm2-6b/
total 12G
-rw-r--r-- 1 2013 999 1.2K Jun 29 06:46 config.json
-rw-r--r-- 1 2013 999 2.2K Jul 12 06:58 configuration_chatglm.py
-rw-r--r-- 1 2013 999 50K Jul 12 06:58 modeling_chatglm.py
-rw-r--r-- 1 2013 999 20K Jun 29 06:46 pytorch_model.bin.index.json
-rw-r--r-- 1 2013 999 15K Jun 29 06:46 quantization.py
-rw-r--r-- 1 2013 999 9.7K Jul 12 06:58 tokenization_chatglm.py
-rw-r--r-- 1 2013 999 995K Jun 29 08:02 tokenizer.model
-rw-r--r-- 1 2013 999 244 Jul 12 06:58 tokenizer_config.json
下载地址:
https://huggingface.co/THUDM/chatglm2-6b/tree/main
下载后覆盖 …/THUDM/chatglm2-6b/ 中对应的文件即可。【不需要下载权重文件】
3.重新训练
执行:
cd ChatGLM2-6B/ptuning
sh train.sh
训练输出如下:
/notebooks/ChatGLM2-6B/ptuning# sh train.sh
master_addr is only used for static rdzv_backend and when rdzv_endpoint is not specified.
[2023-07-12 06:58:22,763] [INFO] [real_accelerator.py:110:get_accelerator] Setting ds_accelerator to cuda (auto detect)
07/12/2023 06:58:23 - WARNING - __main__ - Process rank: 0, device: cuda:0, n_gpu: 1distributed training: True, 16-bits training: False
07/12/2023 06:58:23 - INFO - __main__ - Training/evaluation parameters Seq2SeqTrainingArguments(
_n_gpu=1,
adafactor=False,
adam_beta1=0.9,
adam_beta2=0.999,
adam_epsilon=1e-08,
auto_find_batch_size=False,
bf16=False,
bf16_full_eval=False,
data_seed=None,
dataloader_drop_last=False,
dataloader_num_workers=0,
dataloader_pin_memory=True,
ddp_backend=None,
ddp_bucket_cap_mb=None,
ddp_find_unused_parameters=None,
ddp_timeout=1800,
debug=[],
deepspeed=None,
disable_tqdm=False,
do_eval=False,
do_predict=False,
do_train=True,
eval_accumulation_steps=None,
eval_delay=0,
eval_steps=None,
evaluation_strategy=no,
fp16=False,
fp16_backend=auto,
fp16_full_eval=False,
fp16_opt_level=O1,
fsdp=[],
fsdp_config={'fsdp_min_num_params': 0, 'xla': False, 'xla_fsdp_grad_ckpt': False},
fsdp_min_num_params=0,
fsdp_transformer_layer_cls_to_wrap=None,
full_determinism=False,
generation_config=None,
generation_max_length=None,
generation_num_beams=None,
gradient_accumulation_steps=8,
gradient_checkpointing=False,
greater_is_better=None,
group_by_length=False,
half_precision_backend=auto,
hub_model_id=None,
hub_private_repo=False,
hub_strategy=every_save,
hub_token=<HUB_TOKEN>,
ignore_data_skip=False,
include_inputs_for_metrics=False,
jit_mode_eval=False,
label_names=None,
label_smoothing_factor=0.0,
learning_rate=0.02,
length_column_name=length,
load_best_model_at_end=False,
local_rank=0,
log_level=passive,
log_level_replica=warning,
log_on_each_node=True,
logging_dir=output/nd-chatglm2-6b-pt-128-2e-2/runs/Jul12_06-58-22_1354e8450936,
logging_first_step=False,
logging_nan_inf_filter=True,
logging_steps=10,
logging_strategy=steps,
lr_scheduler_type=linear,
max_grad_norm=1.0,
max_steps=30,
metric_for_best_model=None,
mp_parameters=,
no_cuda=False,
num_train_epochs=3.0,
optim=adamw_hf,
optim_args=None,
output_dir=output/nd-chatglm2-6b-pt-128-2e-2,
overwrite_output_dir=True,
past_index=-1,
per_device_eval_batch_size=1,
per_device_train_batch_size=2,
predict_with_generate=True,
prediction_loss_only=False,
push_to_hub=False,
push_to_hub_model_id=None,
push_to_hub_organization=None,
push_to_hub_token=<PUSH_TO_HUB_TOKEN>,
ray_scope=last,
remove_unused_columns=True,
report_to=[],
resume_from_checkpoint=None,
run_name=output/nd-chatglm2-6b-pt-128-2e-2,
save_on_each_node=False,
save_safetensors=False,
save_steps=10,
save_strategy=steps,
save_total_limit=None,
seed=42,
sharded_ddp=[],
skip_memory_metrics=True,
sortish_sampler=False,
tf32=None,
torch_compile=False,
torch_compile_backend=None,
torch_compile_mode=None,
torchdynamo=None,
tpu_metrics_debug=False,
tpu_num_cores=None,
use_ipex=False,
use_legacy_prediction_loop=False,
use_mps_device=False,
warmup_ratio=0.0,
warmup_steps=0,
weight_decay=0.0,
xpu_backend=None,
)
07/12/2023 06:59:43 - WARNING - datasets.builder - Found cached dataset json (/root/.cache/huggingface/datasets/json/default-7bb34faa0c533729/0.0.0/8bb11242116d547c741b2e8a1f18598ffdd40a1d4f2a2872c7a28b697434bc96)
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 633.77it/s]
[INFO|configuration_utils.py:667] 2023-07-12 06:59:43,392 >> loading configuration file ../THUDM/chatglm2-6b/config.json
[INFO|configuration_utils.py:667] 2023-07-12 06:59:43,397 >> loading configuration file ../THUDM/chatglm2-6b/config.json
[INFO|configuration_utils.py:725] 2023-07-12 06:59:43,398 >> Model config ChatGLMConfig {
"_name_or_path": "../THUDM/chatglm2-6b",
"add_bias_linear": false,
"add_qkv_bias": true,
"apply_query_key_layer_scaling": true,
"apply_residual_connection_post_layernorm": false,
"architectures": [
"ChatGLMModel"
],
"attention_dropout": 0.0,
"attention_softmax_in_fp32": true,
"auto_map": {
"AutoConfig": "configuration_chatglm.ChatGLMConfig",
"AutoModel": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForSeq2SeqLM": "modeling_chatglm.ChatGLMForConditionalGeneration"
},
"bias_dropout_fusion": true,
"eos_token_id": 2,
"ffn_hidden_size": 13696,
"fp32_residual_connection": false,
"hidden_dropout": 0.0,
"hidden_size": 4096,
"kv_channels": 128,
"layernorm_epsilon": 1e-05,
"model_type": "chatglm",
"multi_query_attention": true,
"multi_query_group_num": 2,
"num_attention_heads": 32,
"num_layers": 28,
"original_rope": true,
"pad_token_id": 2,
"padded_vocab_size": 65024,
"post_layer_norm": true,
"pre_seq_len": null,
"prefix_projection": false,
"quantization_bit": 0,
"rmsnorm": true,
"seq_length": 32768,
"tie_word_embeddings": false,
"torch_dtype": "float16",
"transformers_version": "4.30.2",
"use_cache": true,
"vocab_size": 65024
}
[INFO|tokenization_utils_base.py:1821] 2023-07-12 06:59:43,404 >> loading file tokenizer.model
[INFO|tokenization_utils_base.py:1821] 2023-07-12 06:59:43,404 >> loading file added_tokens.json
[INFO|tokenization_utils_base.py:1821] 2023-07-12 06:59:43,404 >> loading file special_tokens_map.json
[INFO|tokenization_utils_base.py:1821] 2023-07-12 06:59:43,404 >> loading file tokenizer_config.json
[INFO|modeling_utils.py:2575] 2023-07-12 06:59:43,572 >> loading weights file ../THUDM/chatglm2-6b/pytorch_model.bin.index.json
[INFO|configuration_utils.py:577] 2023-07-12 06:59:43,573 >> Generate config GenerationConfig {
"_from_model_config": true,
"eos_token_id": 2,
"pad_token_id": 2,
"transformers_version": "4.30.2"
}
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████| 7/7 [00:08<00:00, 1.15s/it]
[INFO|modeling_utils.py:3295] 2023-07-12 06:59:51,883 >> All model checkpoint weights were used when initializing ChatGLMForConditionalGeneration.
[WARNING|modeling_utils.py:3297] 2023-07-12 06:59:51,883 >> Some weights of ChatGLMForConditionalGeneration were not initialized from the model checkpoint at ../THUDM/chatglm2-6b and are newly initialized: ['transformer.prefix_encoder.embedding.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
[INFO|modeling_utils.py:2927] 2023-07-12 06:59:51,886 >> Generation config file not found, using a generation config created from the model config.
Quantized to 4 bit
input_ids [64790, 64792, 790, 30951, 517, 30910, 30939, 30996, 13, 13, 54761, 31211, 54708, 37999, 31201, 56011, 56895, 31201, 33778, 31201, 37282, 32584, 31689, 31201, 34425, 32559, 54530, 50451, 31201, 33494, 33286, 32366, 54642, 31696, 33510, 54570, 33182, 44737, 34425, 32559, 54838, 31636, 35266, 31838, 32581, 31211, 32016, 35295, 31211, 55256, 55139, 13, 38471, 31211, 54740, 13, 32711, 31211, 30972, 30940, 55201, 13, 13, 54590, 55391, 31211, 55346, 54608, 30972, 30940, 54614, 31123, 54536, 43281, 42823, 31201, 41819, 32768, 31155, 13, 13, 54600, 54881, 54915, 31211, 32016, 54564, 55340, 33329, 31755, 55346, 54608, 32735, 31123, 53848, 42823, 31201, 41819, 32768, 31155, 54933, 31755, 40619, 36428, 31201, 46585, 52576, 32735, 31155, 32016, 54716, 32482, 54881, 54915, 31123, 54716, 37957, 54915, 31123, 54716, 36152, 32993, 54915, 31155, 13, 13, 54618, 54827, 32066, 31211, 37999, 30966, 30981, 51837, 32016, 54826, 55008, 37924, 31123, 52799, 32285, 31123, 56029, 56456, 54716, 33993, 31155, 39845, 32066, 54933, 54904, 33993, 31123, 35994, 54643, 35832, 54716, 33993, 31155, 13, 13, 33665, 32066, 31211, 56070, 41864, 33368, 38944, 31123, 46728, 31183, 30941, 16088, 30964, 32285, 31123, 56182, 58050, 31928, 32285, 31155, 31722, 33665, 32066, 54716, 33993, 31155, 13, 13, 34648, 34283, 31211, 55120, 56182, 13, 13, 32108, 31211, 31937, 33503, 31123, 31899, 32623, 31123, 33666, 54644, 55092, 31155, 13, 13, 55437, 31211, 30910, 49141, 32387, 54960, 34425, 32559, 54838, 54530, 35266, 31838, 32581, 31211, 13, 13, 37999, 31211, 37999, 30966, 30981, 56774, 32285, 34534, 31123, 54933, 31755, 55079, 55002, 54746, 54589, 55002, 32741, 31155, 35079, 31847, 33494, 31123, 32108, 31913, 33536, 37999, 32112, 31155, 13, 56011, 56895, 31211, 54933, 38166, 32016, 56011, 56895, 31689, 31123, 54828, 33473, 32559, 31155, 13, 33778, 31211, 54933, 38166, 32016, 33778, 31689, 31123, 54828, 33473, 32559, 31155, 13, 37282, 32584, 31689, 31211, 54933, 38166, 51124, 32993, 54643, 37282, 32052, 31123, 32067, 32581, 37282, 32584, 54642, 31155, 32108, 54534, 34425, 32559, 54538, 32674, 32559, 51124, 32993, 31201, 41600, 31201, 54840, 55156, 34864, 31693, 32016, 54570, 32993, 54530, 32768, 31155, 13, 34425, 32559, 32936, 33286, 51852, 31211, 34425, 32559, 31845, 32936, 31123, 31779, 54590, 55391, 31201, 54600, 54881, 54915, 31201, 54618, 54827, 32066, 31201, 33665, 32066, 31201, 34648, 34283, 41633, 31155, 54688, 32108, 54534, 32559, 54538, 31917, 56011, 56895, 31201, 33778, 31201, 37282, 31689, 38955, 31707, 31123, 54548, 32316, 32936, 33286, 51852, 31155, 13, 34425, 32559, 32366, 54642, 31211, 34425, 32559, 36844, 31845, 32366, 31123, 32330, 32385, 33724, 31155, 32108, 31983, 35266, 33724, 31201, 32366, 31123, 32317, 56577, 54858, 31123, 53199, 39803, 33494, 33286, 45250, 31155, 13, 46483, 42626, 31123, 54960, 34425, 32559, 54838, 54534, 37999, 31201, 33778, 31201, 37282, 32584, 31689, 33510, 31849, 32578, 31123, 32108, 33473, 32559, 44689, 45987, 31123, 54548, 31803, 35266, 42639, 32016, 54020, 31155, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
inputs [Round 1]
......
训练过程正常了。文章来源:https://www.toymoban.com/news/detail-647841.html
参考
1.https://github.com/THUDM/ChatGLM2-6B
2.https://huggingface.co/THUDM/chatglm2-6b/tree/main
3.https://github.com/THUDM/ChatGLM-6B/issues/357
4.https://github.com/THUDM/ChatGLM-6B
5.https://chatglm.cn/blog文章来源地址https://www.toymoban.com/news/detail-647841.html
到了这里,关于【AI实战】ChatGLM2-6B 微调:AttributeError: ‘ChatGLMModel‘ object has no attribute ‘prefix_encoder‘的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!