在深度学习和机器学习领域,模型评价指标用于衡量训练得到的模型在处理数据时的性能和效果。常见的模型评价指标包括:
-
准确率(Accuracy): 准确率是最直观和常用的评价指标之一,表示分类正确的样本数占总样本数的比例。然而,在不平衡数据集中,准确率可能会产生误导。
-
精确率(Precision)和召回率(Recall): 精确率和召回率是用于衡量二分类模型性能的指标。精确率指分类为正类别的样本中真正为正类别的比例,召回率指所有正类别样本中被正确识别为正类别的比例。这两者往往需要进行权衡。
-
F1分数(F1 Score): F1分数是精确率和召回率的调和平均数,可以综合衡量分类模型的性能。在精确率和召回率都重要时,F1分数是一个有用的指标。
-
ROC曲线和AUC值(Receiver Operating Characteristic Curve and Area Under the Curve): ROC曲线以假阳率为横轴、真阳率为纵轴,用于评估分类模型的效果,AUC值则表示ROC曲线下的面积,通常用于比较不同模型的性能。
-
均方误差(Mean Squared Error,MSE)和平均绝对误差(Mean Absolute Error,MAE): 这两个指标主要用于回归模型的评价,分别衡量了预测值与真实值之间的平方误差和绝对误差。
-
对数损失(Log Loss): 适用于多分类问题,对数损失衡量了模型对每个类别的预测概率分布与真实分布的差异程度。
除了以上列举的指标外,针对特定任务和领域还可能存在其他更加具体的评价指标。在选择模型评价指标时,需要结合具体问题的特点和需求来进行综合考量,以选择最合适的指标来全面评价模型的性能。我们训练学习好的模型,通过客观地评估模型性能,才能更好实际运用决策。模型评估主要有:预测误差情况、拟合程度、模型稳定性等方面。机器学习模型预测误差情况通常是评估的重点,它不仅仅是学习过程中对训练数据有良好的学习预测能力,根本上在于要对新数据能有很好的预测能力(泛化能力),所以我们常通过测试集的指标表现评估模型的泛化性能。由于损失函数评估分类效果不太直观,所以,分类任务的评估还常用f1-score、precision、recall,可以直接展现各种类别正确分类情况。
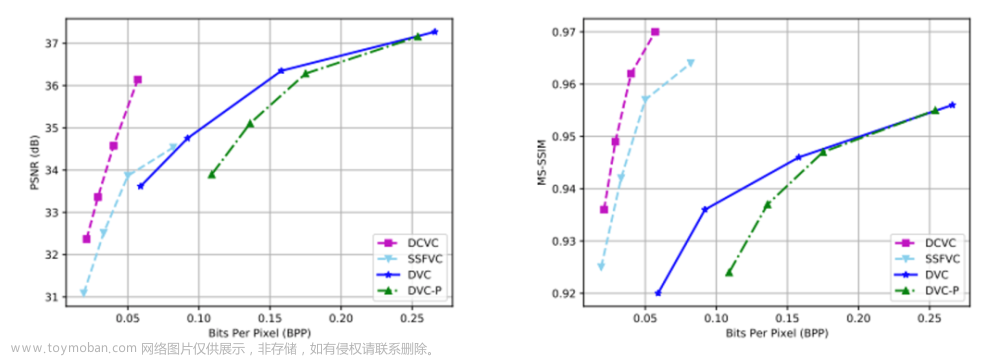
记忆方式:P(Positive)表示挑选,N(negative)表示不挑选,
T(True)表示正确,F(False)表示错误。
TP:挑选的-正确 (挑选的是正确的,正确)
TN:不挑选的-正确 (没有挑选,但是是正确的,说明将负样本归到不挑选类里,正确)
FP:挑选的-错误(误报) (挑选的是错误的,误报)
FN:不挑选的-错误(漏报) (没有挑选,但是是错误的,说明有正样本没有挑选,漏报)
一、准确率:正确样本占总样本的比例
准确率是最直观和常用的评价指标之一,表示分类正确的样本数占总样本数的比例。然而,在不平衡数据集中,准确率可能会产生误导。
Accuracy=(TP+TN)/(TP+TN+FP+FN)(挑选和不挑选,都是正确的,说明是正样本占总样本的比例,比例越大,说明挑选的越好,但是数据不均衡就会导致失真)
二、精确率:正样本预测正确占正样本的比例
精确率和召回率是用于衡量二分类模型性能的指标。精确率指分类为正类别的样本中真正为正类别的比例,召回率指所有正类别样本中被正确识别为正类别的比例。这两者往往需要进行权衡。
precision=(TP)/(TP+FP) (挑选正确的占挑选的比例,说明从所有挑选出来的样本找正确挑选的比例)
1.精确度低(误报多),召回率高的解决办法:
模型把大量背景(负样本)错判成目标(正样本 ),误报多。
主要原因不外乎数据本身有问题:1、图片上目标没有标全,有大量没标注的 ,这样会导致模型其实学到了目标物特征,但是真值是负样本(没有标注);2、图片上目标标的太仔细,把非常小像素的目标(特征跟背景相差不大)都标了,这样也会导致模型错把背景当成目标 。
三、召回率:正样本预测正确占实际正样本的比例
精确率和召回率是用于衡量二分类模型性能的指标。精确率指分类为正类别的样本中真正为正类别的比例,召回率指所有正类别样本中被正确识别为正类别的比例。这两者往往需要进行权衡。
R=(TP)/(TP+FN) (挑选正确占挑选正确+没挑选错误(漏报),说明正确挑选的占实际正样本的比例)
为了找到所有正样本。
1.召回率低(漏报多),精确度高的解决办法:
对错误的标注样本进行修正。
注:漏报(False Negative,FN)是指实际为正类别的样本被错误地预测为负类别,也即模型未能将正例正确地预测为正例。在二分类问题中,漏报会导致召回率(Recall)降低。在实际应用中,精确率和召回率往往需要进行权衡。当需要尽量避免漏报时(例如在医疗诊断中,更希望尽量不要漏掉患病的情况),我们会更加关注召回率;而当需要避免误报时(例如在垃圾邮件过滤中,更希望尽量减少将正常邮件识别为垃圾邮件的情况),我们会更加关注精确率。
四、平均精度AP
AP就是Precision-recall 曲线下面的面积。

五、map
当我们把所有类别的AP都计算出来后,再对它们求平均值,即可得到mAP。
六、F1 分数
如果想要找到 P 和 R 二者之间的一个平衡点,我们就需要一个新的指标:F1 分数。F1 分数同时考虑了查准率和查全率,让二者同时达到最高,取一个平衡。F1 计算公式如下:
这里的 F1 计算是针对二分类模型,多分类任务的 F1 的计算请看下面。

F1 度量的一般形式:Fβ,能让我们表达出对查准率/查全率的偏见,Fβ 计算公式如下:
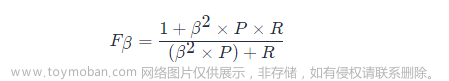
其中β>1 对查全率有更大影响,β<1 对查准率有更大影响。
不同的计算机视觉问题,对两类错误有不同的偏好,常常在某一类错误不多于一定阈值的情况下,努力减少另一类错误。在目标检测中,mAP(mean Average Precision)作为一个统一的指标将这两种错误兼顾考虑。
很多时候我们会有多个混淆矩阵,例如进行多次训练/测试,每次都能得到一个混淆矩阵;或者是在多个数据集上进行训练/测试,希望估计算法的”全局“性能;又或者是执行多分类任务,每两两类别的组合都对应一个混淆矩阵;…总而来说,我们希望能在 nn 个二分类混淆矩阵上综合考虑查准率和查全率。
一种直接的做法是先在各混淆矩阵上分别计算出查准率和查全率,记为 (P1,R1),(P2,R2),...,(Pn,Rn) 然后取平均,这样得到的是”宏查准率(Macro-P)“、”宏查准率(Macro-R)“及对应的”宏 F1F1(Macro-F1)“:

另一种做法是将各混淆矩阵对应元素进行平均,得到 TP、FP、TN、FNTP、FP、TN、FN 的平均值,再基于这些平均值计算出”微查准率“(Micro-P)、”微查全率“(Micro-R)和”微 F1“(Mairo-F1)

七、PR 曲线
精准率和召回率的关系可以用一个 P-R 图来展示,以查准率 P 为纵轴、查全率 R 为横轴作图,就得到了查准率-查全率曲线,简称 P-R 曲线,PR 曲线下的面积定义为 AP:

1.4.1,如何理解 P-R 曲线
可以从排序型模型或者分类模型理解。以逻辑回归举例,逻辑回归的输出是一个 0 到 1 之间的概率数字,因此,如果我们想要根据这个概率判断用户好坏的话,我们就必须定义一个阈值 。通常来讲,逻辑回归的概率越大说明越接近 1,也就可以说他是坏用户的可能性更大。比如,我们定义了阈值为 0.5,即概率小于 0.5 的我们都认为是好用户,而大于 0.5 都认为是坏用户。因此,对于阈值为 0.5 的情况下,我们可以得到相应的一对查准率和查全率。
但问题是:这个阈值是我们随便定义的,我们并不知道这个阈值是否符合我们的要求。 因此,为了找到一个最合适的阈值满足我们的要求,我们就必须遍历 0 到 1 之间所有的阈值,而每个阈值下都对应着一对查准率和查全率,从而我们就得到了 PR 曲线。文章来源:https://www.toymoban.com/news/detail-652151.html
最后如何找到最好的阈值点呢? 首先,需要说明的是我们对于这两个指标的要求:我们希望查准率和查全率同时都非常高。 但实际上这两个指标是一对矛盾体,无法做到双高。图中明显看到,如果其中一个非常高,另一个肯定会非常低。选取合适的阈值点要根据实际需求,比如我们想要高的查全率,那么我们就会牺牲一些查准率,在保证查全率最高的情况下,查准率也不那么低。。文章来源地址https://www.toymoban.com/news/detail-652151.html
八、ROC 曲线与 AUC 面积
- PR 曲线是以 Recall 为横轴,Precision 为纵轴;而 ROC 曲线则是以 FPR 为横轴,TPR 为纵轴**。P-R 曲线越靠近右上角性能越好。PR 曲线的两个指标都聚焦于正例
- PR 曲线展示的是 Precision vs Recall 的曲‘’‘’‘’线,ROC 曲线展示的是 FPR(x 轴:False positive rate) vs TPR(True positive rate, TPR)曲线。
到了这里,关于深度学习1:通过模型评价指标优化训练的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!