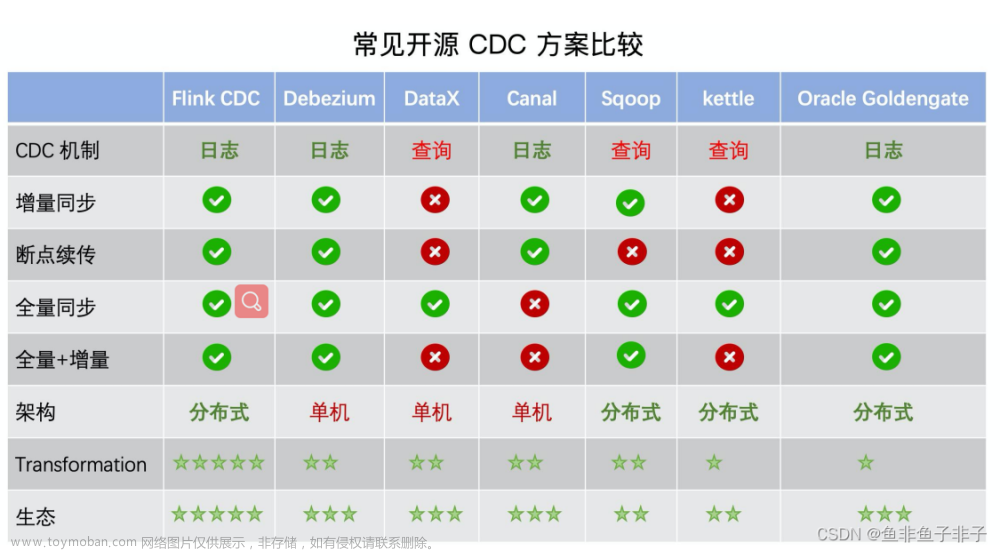
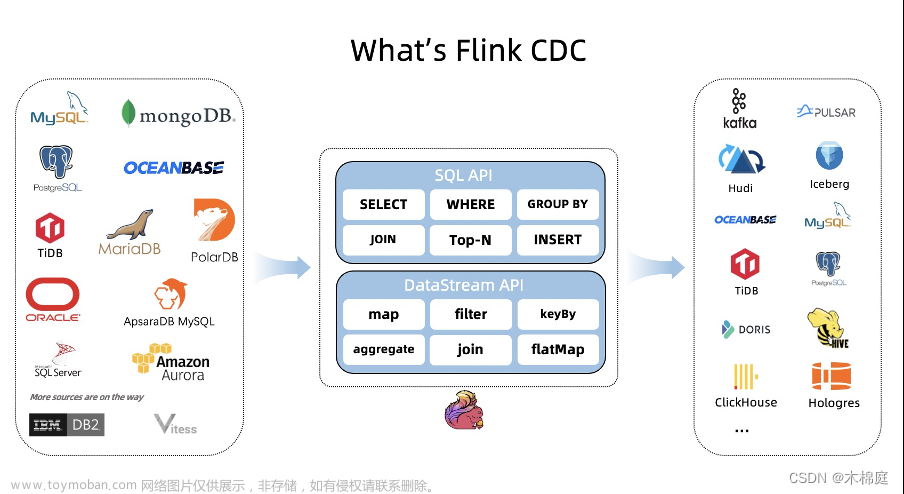
1. 环境信息
| 类型 | 版本/描述 |
|---|---|
| docker | 20.10.9 |
| Postgresql | 10.6 |
| 初始化账号密码:postgres/postgres 普通用户:test1/test123 数据库:test_db |
|
| flink | 1.13.6 |
2. 安装
step1: 拉取 PostgreSQL 10.6 版本的镜像:
docker pull postgres:10.6
step2:创建并启动 PostgreSQL 容器,在这里,我们将把容器的端口 5432 映射到主机的端口 30028,账号密码设置为postgres,并将 pgoutput 插件加载到 PostgreSQL 实例中:
docker run -d -p 30028:5432 --name postgres-10.6 -e POSTGRES_PASSWORD=postgres postgres:10.6 -c 'shared_preload_libraries=pgoutput'
step3: 查看容器是否创建成功:
docker ps | grep postgres-10.6
3. 配置
step1:docker进去Postgresql数据的容器:
docker exec -it postgres-10.6 bash
step2:编辑postgresql.conf配置文件:
vi /var/lib/postgresql/data/postgresql.conf
配置内容如下:
# 更改wal日志方式为logical(方式有:minimal、replica 、logical )
wal_level = logical
# 更改solts最大数量(默认值为10),flink-cdc默认一张表占用一个slots
max_replication_slots = 20
# 更改wal发送最大进程数(默认值为10),这个值和上面的solts设置一样
max_wal_senders = 20
# 中断那些停止活动超过指定毫秒数的复制连接,可以适当设置大一点(默认60s,0表示禁用)
wal_sender_timeout = 180s
step3:重启容器:
docker restart postgres-10.6
连接数据库,如果查询一下语句,返回logical表示修改成功:
SHOW wal_level;
4. 新建用户并赋权
使用创建容器时的账号密码(postgres/postgres)登录Postgresql数据库。
先创建数据库和表:
-- 创建数据库 test_db
CREATE DATABASE test_db;
-- 连接到新创建的数据库 test_db
\c test_db
-- 创建 t_user 表
CREATE TABLE "public"."t_user" (
"id" int8 NOT NULL,
"name" varchar(255),
"age" int2,
PRIMARY KEY ("id")
);
新建用户并且给用户权限:
-- pg新建用户
CREATE USER test1 WITH PASSWORD 'test123';
-- 给用户复制流权限
ALTER ROLE test1 replication;
-- 给用户登录数据库权限
GRANT CONNECT ON DATABASE test_db to test1;
-- 把当前库public下所有表查询权限赋给用户
GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA public TO test1;
5. 发布表
-- 设置发布为true
update pg_publication set puballtables=true where pubname is not null;
-- 把所有表进行发布
CREATE PUBLICATION dbz_publication FOR ALL TABLES;
-- 查询哪些表已经发布
select * from pg_publication_tables;
更改表的复制标识包含更新和删除的值:文章来源:https://www.toymoban.com/news/detail-672886.html
-- 更改复制标识包含更新和删除之前值(目的是为了确保表 t_user 在实时同步过程中能够正确地捕获并同步更新和删除的数据变化。如果不执行这两条语句,那么 t_user 表的复制标识可能默认为 NOTHING,这可能导致实时同步时丢失更新和删除的数据行信息,从而影响同步的准确性)
ALTER TABLE t_user REPLICA IDENTITY FULL;
-- 查看复制标识(为f标识说明设置成功,f(表示 full),否则为 n(表示 nothing),即复制标识未设置)
select relreplident from pg_class where relname='t_user';
6. flink sql
-- 源表定义
CREATE TABLE `table_source_pg` (
id BIGINT,
name STRING,
age INT
) WITH (
'connector' = 'postgres-cdc',
'hostname' = '10.194.183.120',
'port' = '30028',
'username' = 'test1',
'password' = 'test123',
'database-name' = 'test_db',
'schema-name' = 'public',
'table-name' = 't_user',
'decoding.plugin.name' = 'pgoutput'
)
-- 目标表表定义
CREATE TABLE `table_sink_mysql` (
id BIGINT,
name STRING,
age INT,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://10.194.183.120:30306/test',
'username' = 'root',
'password' = 'root',
'table-name' = 't_user_copy'
)
-- insert语句
INSERT INTO `table_sink_mysql` (`id`, `name`, `age`) (SELECT `id`, `name`, `age` FROM `table_source_pg`)
7. 命令汇总
-- pg新建用户
CREATE USER test1 WITH PASSWORD 'test123';
-- 给用户复制流权限
ALTER ROLE ODPS_ETL replication;
-- 给用户数据库权限
GRANT CONNECT ON DATABASE test_db to test1;
-- 设置发布开关
update pg_publication set puballtables=true where pubname is not null;
-- 把所有表进行发布
CREATE PUBLICATION dbz_publication FOR ALL TABLES;
-- 查询哪些表已经发布
select * from pg_publication_tables;
-- 给表查询权限
grant select on TABLE aa to ODPS_ETL;
-- 给用户读写权限
grant select,insert,update,delete ON ALL TABLES IN SCHEMA public to bd_test;
-- 把当前库所有表查询权限赋给用户
GRANT SELECT ON ALL TABLES IN SCHEMA public TO ODPS_ETL;
-- 把当前库以后新建的表查询权限赋给用户
alter default privileges in schema public grant select on tables to ODPS_ETL;
-- 更改复制标识包含更新和删除之前值
ALTER TABLE test0425 REPLICA IDENTITY FULL;
-- 查看复制标识
select relreplident from pg_class where relname='test0425';
-- 查看solt使用情况
SELECT * FROM pg_replication_slots;
-- 删除solt
SELECT pg_drop_replication_slot('zd_org_goods_solt');
-- 查询用户当前连接数
select usename, count(*) from pg_stat_activity group by usename order by count(*) desc;
-- 设置用户最大连接数
alter role odps_etl connection limit 200;
附:文章来源地址https://www.toymoban.com/news/detail-672886.html
- 参考文章:https://www.cnblogs.com/xiongmozhou/p/14817641.html
到了这里,关于flink postgresql cdc实时同步(含pg安装配置等)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!