目录
Linux服务器环境部署专栏目录(点击进入…)
Linux安装Kafka及其环境配置
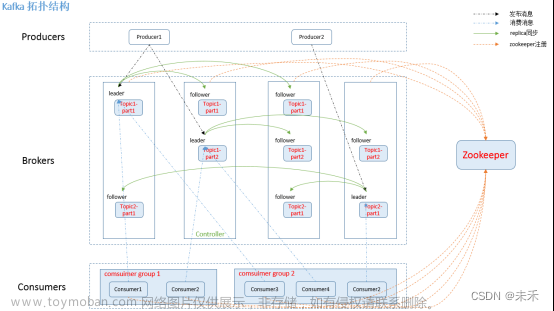
在Kafka集群(Cluster)中,一个Kafka节点就是一个Broker,消息由Topic来承载,可以存储在1个或多个Partition中。发布消息的应用为Producer、消费消息的应用为Consumer,多个Consumer可以促成Consumer Group共同消费一个Topic中的消息
| 概念/对象 | 说明 |
|---|---|
| Broker | Kafka节点 |
| Leader | 用来处理消息的接受和消费等请求,也就是说producer是将消息push到leader,而consumer也是从leader上去poll消息 |
| Follower | 主要用于备份消息数据,一个leader会有多个follower |
| Topic | 主题,用于承载消息 |
| Partition | 分区,用于主题分片存储 |
| Consumer | 消费者,从主题订阅消息的应用 |
| Consumer Group | 消费者组,由多个消费者组成 |
注意:由于kafka依赖zookeeper因此需要安装zookeeper,而kafka是基于scala语言编写,scala又是基于jdk的,因此需要安装jdk
(1)解压Kafka安装包
tar -zxvf kafka_2.12-3.2.3.tgz
(2)配置环境变量
export KAFKA_HOME=/home/environment/kafka_2.12-3.2.3
export PATH=$KAFKA_HOME/bin:$PATH
使配置生效:source /etc/profile文章来源:https://www.toymoban.com/news/detail-684958.html
(3)修改配置文件
| 配置文件 | 说明 |
|---|---|
| /config/server.properties | 修改zookeeper.connect集群地址 |
| /config/zookeeper.properties | Kafka所管理的单机zookeeper(不使用) |
(4)修改broker.id(集群每台机器不能一样)
| 配置 | 说明 |
|---|---|
| broker.id | 每台机器不能一样 |
| zookeeper.connect | 因为实验环境中有3台zookeeper服务器,所以在这里zookeeper.connect设置为3台,必须全部加进去 |
| listeners | Socket服务器侦听的地址,在配置集群的时候必须设置 |
(5)启动Kafka服务
| 命令 | 说明 |
|---|---|
| ./bin/kafka-server-start.sh -daemon ./config/server.properties | 启动 |
| ./bin/kafka-server-stop.sh | 停止 |
启动Kafka自带的Zookeeper文章来源地址https://www.toymoban.com/news/detail-684958.html
#启动Zookeeper
./zookeeper-server-start.sh ../config/zookeeper.properties
#查看日志
/var/tmp/kafka/zk.log 2>&1 &
#查看启动成功
jps
(6)开放端口与防火墙
#开启防火墙
systemctl start firewalld
#开启2181(zk,如果需要向外连接zk则需要)
firewall-cmd --zone=public --add-port=2181/tcp --permanent
#开启开启9092(kafka)
firewall-cmd --zone=public --add-port=9092/tcp --permanent
#重启防火墙
firewall-cmd --reload
#查看已经开放的端口
firewall-cmd --list-ports
#查看是否开启成功
firewall-cmd --list-ports
server.properties配置文件详细说明
# 此配置文件用于基于ZK的模式,其中需要Apache ZooKeeper。请参阅kafka.server。KafkaConfig了解更多详细信息和默认值
############################# Server Basics #############################
# broker id。对于每个代理,必须将其设置为唯一的整数
broker.id=0
############################# Socket Server Settings #############################
# 套接字服务器侦听的地址。如果未配置,主机名将等于java.net.InetAddress.getCanonicalHostName() 和 端口 9092
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
# 不能设置0.0.0.0
listeners=PLAINTEXT://node1:9092
# 监听器名称、主机名和代理将向客户端播发的端口。如果未设置,则使用“listeners”的值
# 比如Kafka集群内部通讯走内网,而对外提供服务的是公网或者隔离网络,则需要配置advertised.listeners
#advertised.listeners=PLAINTEXT://your.host.name:9092
#advertised.listeners=PLAINTEXT://0.0.0.0:9092
# 将侦听器名称映射到安全协议,默认情况下它们是相同的
#listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
# 服务器用于从网络接收请求并向网络发送响应的线程数
num.network.threads=3
# 服务器用于处理请求的线程数,其中可能包括磁盘I/O
num.io.threads=8
# 套接字服务器使用的发送缓冲区(SO_SNDBUF)
socket.send.buffer.bytes=102400
# 套接字服务器使用的接收缓冲区(SO_RCVBUF)
socket.receive.buffer.bytes=102400
# 套接字服务器将接受的最大请求大小(防止OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# 存储日志文件的目录的逗号分隔列表
log.dirs=/data/kafka/logs
# 每个主题的默认日志分区数。更多的分区允许使用更大的并行性,但这也会导致跨代理的文件更多
num.partitions=1
# 每个数据目录在启动和关闭时用于日志恢复的线程数。对于数据目录位于RAID阵列中的安装,建议增加此值
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
# 组元数据内部主题“__consumer_offsets”和“__transaction_state”的复制因子对于开发测试以外的任何内容,建议使用大于1的值以确保可用性,例如3
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
############################# Log Flush Policy #############################
# 消息会立即写入文件系统,但默认情况下,仅使用fsync()延迟同步操作系统缓存。
# 以下配置控制数据到磁盘的刷新
# 这里的几个重要的权衡:
# 1.持久性(Durability):如果不使用复制,未刷新的数据可能会丢失。
# 2.延迟(Latency):当刷新发生时,非常大的刷新间隔可能会导致延迟峰值,因为要刷新的数据很多。
# 3.吞吐量(Throughput):刷新通常是最昂贵的操作,较小的刷新间隔可能导致过度查找
# 下面的设置允许用户配置刷新策略,以便在一段时间后或每隔N条消息(或两者)刷新数据。这可以在全局范围内完成,并基于每个主题进行覆盖.
# 强制将数据刷新到磁盘之前要接受的消息数
#log.flush.interval.messages=10000
# 在强制刷新之前,消息可以在日志中停留的最长时间
#log.flush.interval.ms=1000
############################# Log Retention Policy #############################
# 以下配置控制日志段的处理。可以将策略设置为在一段时间后或在累积给定大小后删除段。只要满足这些条件中的*任一*,就会删除一个段。删除总是从日志末尾开始.
# 日志保留时间
log.retention.hours=168
# 日志的基于大小的保留策略。除非剩余的段低于log.retention.bytes,否则会从日志中删除段。功能独立于log.retention.hours.
#log.retention.bytes=1073741824
# 日志段文件的最大大小。当达到此大小时,将创建一个新的日志段 默认1024MB
log.segment.bytes=1073741824
# 检查日志段以查看是否可以根据保留策略删除它们的时间间隔
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# Zookeeper连接字符串(有关详细信息,请参阅动物园管理员文档)。这是一个逗号分隔的主机:端口对,每个主机对应一个zk服务器
# Zookeeper. 案例. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# 还可以将可选的chroot字符串附加到url,以指定所有kafka znode的根目录.
#zookeeper.connect=localhost:2181
zookeeper.connect=node1:2181,node2:2181,node3:2181
# 连接到zookeeper超时(毫秒)
zookeeper.connection.timeout.ms=18000
############################# Group Coordinator Settings #############################
# 以下配置指定GroupCoordinator将延迟初始消费者重新平衡的时间(毫秒)。
# 重新平衡将因group.initial.rebalance.delay的值而进一步延迟。ms作为新成员加入组,最大为max.poll.interval.ms。默认值为3秒
# 在这里将其覆盖为0,因为它可以为开发和测试提供更好的开箱即用体验。然而,在生产环境中,默认值3秒更合适,因为这将有助于避免在应用程序启动期间进行不必要且可能代价高昂的重新平衡
group.initial.rebalance.delay.ms=0
zookeeper.properties配置详细说明
# kakfa管理的zookeeper(使用自己的集群)
# 存储快照的目录
#dataDir=/tmp/zookeeper
dataDir=/data/zookeeper/zkdata
# 客户端将连接的端口
clientPort=2181
# 禁用每个ip的连接数限制,因为这是非生产配置
maxClientCnxns=0
# 默认情况下禁用admin server以避免端口冲突。默认false 如果选择启用此选项,请将端口设置为非冲突端口
admin.enableServer=true
admin.serverPort=8010
到了这里,关于Linux安装Kafka及其环境配置的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!