需求分析
- 从https://pic.netbian.com/4kfengjing/网站爬取图片,并保存
Python实现
- 获取待爬取网页
def get_htmls(pages=list(range(2, 5))):
"""获取待爬取网页"""
pages_list = []
for page in pages:
url = f"https://pic.netbian.com/4kfengjing/index_{page}.html"
response = requests.get(url)
response.encoding = 'gbk'
pages_list.append(response.text)
return pages_list
get_htmls(pages=list(range(2, 5)))
- 获取所有图片,并下载
def get_picturs(htmls):
"""获取所有图片,并下载"""
for html in htmls:
soup = BeautifulSoup(html, 'html.parser')
pic_li = soup.find('div', id='main').find('div', class_='slist').find('ul', class_='clearfix')
image_path = pic_li.find_all('img')
for file in image_path:
pic_name = './practice05/' + file['alt'].replace(" ",'_') + '.jpg'
src = file['src']
src = f"https://pic.netbian.com/{src}"
response = requests.get(src)
with open(pic_name, 'wb') as f:
f.write(response.content)
print("图片已下载并保存为:{}".format(pic_name))
htmls = get_htmls(pages=list(range(2, 5)))
get_picturs(htmls)
-
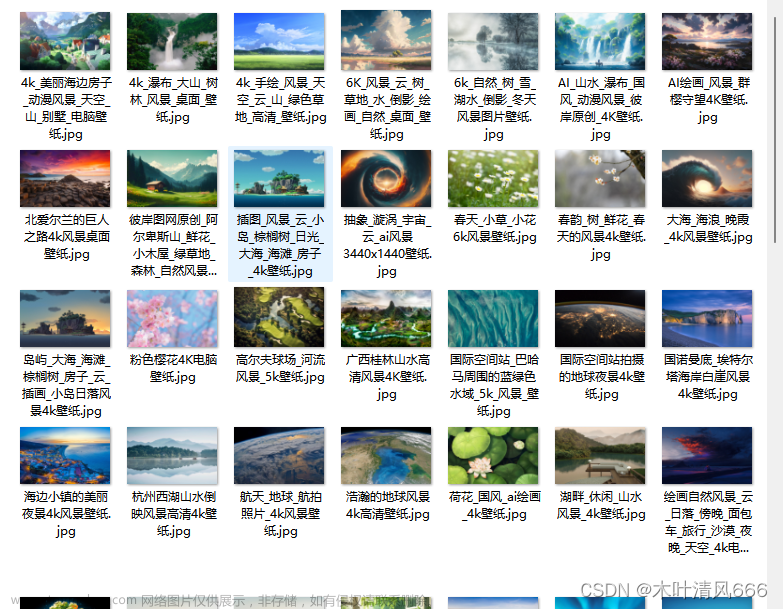
爬取结果展示

文章来源地址https://www.toymoban.com/news/detail-686457.html
文章来源:https://www.toymoban.com/news/detail-686457.html
到了这里,关于【python爬虫】—图片爬取的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![python爬取豆瓣电影排行前250获取电影名称和网络链接[静态网页]————爬虫实例(1)](https://imgs.yssmx.com/Uploads/2024/01/415693-1.png)