1.Python读取一个txt文件的内容并将其写入到另一个txt文件
# -*- encoding:gb2312 -*-
import chardet
def read_write_txt(inputpath, outputpath):
with open(
inputpath,
'rb',
) as file: # rb: 以二进制格式打开一个文件用于只读。
raw_data = file.read() # 读出内容用到的是read函数。这个函数的工作原理是依靠一个指针来对内容进行访问的。read方法会用一个指针将文本内容从上到下扫面一遍并且将其输出到内存。扫描完后它的指针是停留在末尾处的。也就是说,如果我们想用read方法访问同一个文件两次,是不可行的。
detected_encoding = chardet.detect(raw_data)['encoding'] # 返回文件的编码格式。
with open(inputpath, 'r', encoding=detected_encoding) as infile:
with open(outputpath, 'w', encoding=detected_encoding) as outfile:
# # 第一种:读取所有行
# data1 = infile.readlines()
# print(data1)
# # 输出:['好好学习\n', '天天向上\n', '我是一只鱼\n', '哈哈哈']
# 第二种:每行分开读取
data2 = []
for line in infile:
data_line = line.strip("\n") # 去除首尾换行符
data2.append(data_line)
print(data2)
# 输出:['好好学习', '天天向上', '我是一只鱼', '哈哈哈']
# 写入方法
for line in data2:
# data = '' + '\t'.join(str(i) for i in line) + '\n' # 用\t隔开
data = '' + ''.join(str(i) for i in line) + '\n' # 用空格隔开
outfile.write(data)
if __name__ == "__main__":
input_file = '1.txt' # 待读取的文件
output_file = 'ansi.txt' # 写入的文件
read_write_txt(input_file, output_file)
待读入文件1.txt

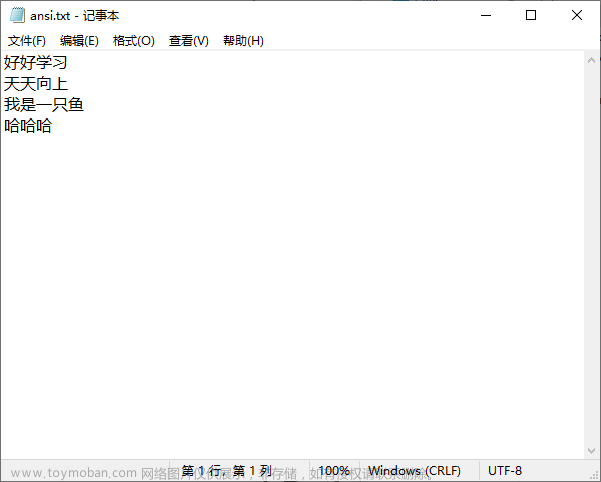
写入后的文件ansi.txt
2.Python读取一个未知编码的文件并将其设置为指定编码格式
要在Python中读取一个未知编码的文件并将其设置为另一种编码格式,可以使用chardet模块来检测文件的编码格式,然后使用Python内置的编码库来进行转换。
使用该代码前需要安装chardet和codecs库
pip install chardet
pip install codecs
首先,你可以使用chardet模块来检测文件的编码格式。你可以使用以下代码来完成这个步骤:
# -*- encoding:gb2312 -*-
import chardet
import codecs
def save_as_specified_encoding(input_file, output_file, output_encoding): #input_file为未知编码文件,output_file为编码后的文件,output_encoding为编码格式
with open(
input_file,
'rb',
) as file: # rb: 以二进制格式打开一个文件用于只读。
raw_data = file.read() # 读出内容用到的是read函数。这个函数的工作原理是依靠一个指针来对内容进行访问的。read方法会用一个指针将文本内容从上到下扫面一遍并且将其输出到内存。扫描完后它的指针是停留在末尾处的。也就是说,如果我们想用read方法访问同一个文件两次,是不可行的。
detected_encoding = chardet.detect(raw_data)['encoding'] # 返回文件的编码格式。
with codecs.open(input_file,
'r',
encoding=detected_encoding,
errors='ignore') as input_file:
content = input_file.read()
# codecs.open(filename, mode='r', encoding=None, errors='strict', buffering=1) 使用给定的 mode 打开已编码的文件并返回一个 StreamReaderWriter的实例,提供透明的编码/解码;与内置函数open类似。
with codecs.open(output_file,
'w',
encoding=output_encoding,
errors='ignore') as output_file:
output_file.write(content)
if __name__ == "__main__":
input_file = '1.txt' # 未知编码文件
output_file = 'ansi.txt' # 编码后的文件
output_encoding = 'ansi' # 设置的编码
save_as_specified_encoding(input_file, output_file, output_encoding)
原始文件1.txt

编码后的文件ansi.txt

3.Python实现txt文件中字符串的替换
# -*- encoding:gb2312 -*-
def replace_txt(inputpath, outputpath):
# 打开原始文件和目标文件
with open(inputpath, 'r') as file:
content = file.read()
# 替换字符:和:
new_content = content.replace(':', ' ')
new_content = new_content.replace(':', ' ')
# 将替换后的内容写入目标文件
with open(outputpath, 'w') as file:
file.write(new_content)
if __name__ == "__main__":
input_path = 'ansi.txt' # 待处理的txt文件
output_path = 'result.txt' # 替换字符后的txt文件
replace_txt(input_path, output_path)
ansi文件(原始文件)

result文件 (替换后的文件)文章来源:https://www.toymoban.com/news/detail-687840.html
 文章来源地址https://www.toymoban.com/news/detail-687840.html
文章来源地址https://www.toymoban.com/news/detail-687840.html
到了这里,关于1.Python操作txt文本的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!








