GO系列
1、GO学习之Hello World
2、GO学习之入门语法
3、GO学习之切片操作
4、GO学习之 Map 操作
5、GO学习之 结构体 操作
6、GO学习之 通道(Channel)
7、GO学习之 多线程(goroutine)
8、GO学习之 函数(Function)
9、GO学习之 接口(Interface)
10、GO学习之 网络通信(Net/Http)
11、GO学习之 微框架(Gin)
12、GO学习之 数据库(mysql)
13、GO学习之 数据库(Redis)
14、GO学习之 搜索引擎(ElasticSearch)
15、GO学习之 消息队列(Kafka)
16、GO学习之 远程过程调用(RPC)
17、GO学习之 goroutine的调度原理
前言
按照公司目前的任务,go 学习是必经之路了,虽然行业卷,不过技多不压身,依旧努力!!!
在现在的互联网应用中,或者是平台,都面对者大流量、百万并发的压力。在微服务项目中,也有为了保证业务逻辑顺序而发愁,在大量消息突然降临的同时,许多应用都是无法支撑大量访问的,导致系统崩溃,此时此刻,只要能让消息排成队,不要拥挤,多分配几个服务处理依然变得很顺畅了,那 Kafka 就是一个相对比较完美的解决方案。
一、Kafka 简介
Kafka 是由 Apache 软件基金会开发和维护的开源的、分布式的消息队列系统,用于高吞吐量、持久性的消息传递。主要用于实时数据处理,可以处理海量的数据流,并将数据流可靠地传递给多个消费者应用程序。
Kafka 的核心概念:
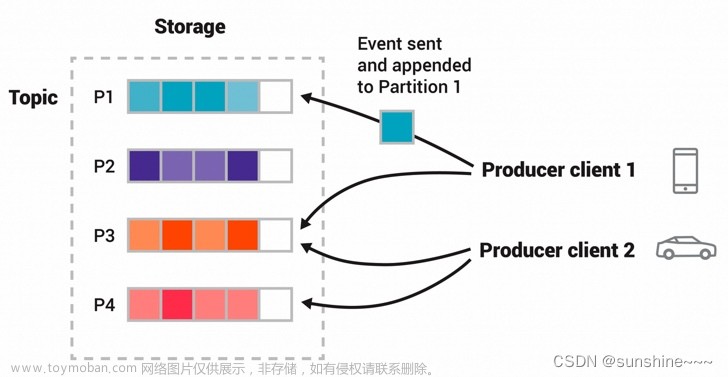
- 主题(Topic): 主题是消息的逻辑通道,消息发布者将消息发布到一个或多个主题。
- 分区(Partition): 主题可以分为多个分区,每个分区可以视为独立的消息队列,方便水平扩展,
- 生产者(Producer): 生成者负责将消息发送到 Topic。
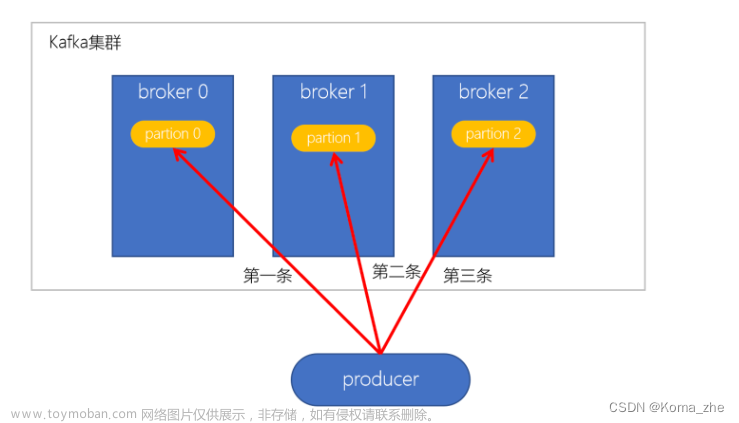
- 消费者(Consumer): 消费者负责从 Topic 中获取消息并且处理。
- 代理节点(Broker): Kafka 集群由多个代理节点组成,每个节点都是一个独立的 Kafka 服务器,负责存储和传递消息。
Kafka 的优点:
- 高吞吐量: Kafka能够处理大规模数据流,支持每秒百万消息的处理。
- 持久性: Kafka 可以可靠地保存消息,即便消费者宕机或断开连接,消息也不会丢失。
- 水平扩展: Kafka 可以通过添加代理节点来水平扩展,以满足高负载需求。
- 采样化的使用场景: Kafka 适用于多种用途,包括日志收集、实时分析、事件驱动架构等。
- 社区支持: 开源项目,Kafka 拥有庞大的社区支持和生态系统。
Kafka 的缺点:
- 复杂性: 配置和管理 Kafka 集群可能相对负责。
- 存储成本: 由于持久性需求,Kafka 需要大量的存储空间来报错消息。
二、基本操作(Go)
2.1 下载Kafka包
通过 go get 拉取:
go get github.com/Shopify/sarama
注意
有可能出错,也是解决了好长时间,我遇到的错误如下:
PS D:\workspaceGo> go get github.com/Shopify/sarama
go: github.com/Shopify/sarama@v1.41.1: parsing go.mod:
module declares its path as: github.com/IBM/sarama
but was required as: github.com/Shopify/sarama
经过一番 baidu,google 和询问 ChatGPT 之后解释是这样的:
这个错误是因为在你的 Go 项目中的 go.mod 文件声明了一个错误的模块路径。错误信息中显示,你的项目试图使用 github.com/IBM/sarama 作为模块路径,但实际上你需要使用 github.com/Shopify/sarama。
那是如何解决呢?
- 首先检查 go.mod 配置文件中,有没有错误的 sarama,发现没有。
- 使用命令 go clean -modcache 来清除缓存,重新 go get github.com/Shopify/sarama,依旧报错。
- 网上说用 replace 来替换错误的包路径,在 go.mod 配置文件中最下面添加:replace github.com/Shopify/sarama => github.com/Shopify/sarama v1.26.1,然后再一次执行 go clean -modcache,go mod vendor 命令,发现可以了。
- 我再次执行 go get github.com/Shopify/sarama 拉取包,发现包自动升级了,返回信息如下:
go: upgraded github.com/Shopify/sarama v1.26.1 => v1.41.1- 包已拉取成功,可以编码了。
此错误应该是包路径冲突导致,目前已解决,如有更好的解决方案,请评论区教一下我,谢谢!!!
2.2 生产者
下面示例中,首先用
sarama.NewConfig()来创建一个 config 配置实体,然后通过 sarama.NewSyncProducer() 来创建一个生产者,用 &sarama.ProducerMessage{} 生成一个消息,通过producer.SendMessage(message)发送到制定 Topic 中。
package main
import (
"log"
"time"
"github.com/Shopify/sarama"
)
func main() {
// 配置 kafka 生产者
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll
config.Producer.Retry.Max = 5
config.Producer.Return.Successes = true
// 创建 Kafka 生产者
producer, err := sarama.NewSyncProducer([]string{"192.168.1.20:9092"}, config)
if err != nil {
log.Fatalf("Creating producer: %v", err)
}
// 延迟关闭生产者链接
defer producer.Close()
// 定义消息 Topic是 go-test, 值为 Hello Kafka
message := &sarama.ProducerMessage{
Topic: "go-test",
Value: sarama.StringEncoder("Hello Kafka!"),
}
// 发送消息
for i := 0; i < 10; i++ {
partition, offset, err := producer.SendMessage(message)
if err != nil {
log.Fatalf("Sending message: %v", err)
}
log.Printf("Message sent to partition %d at offset %d", partition, offset)
time.Sleep(time.Second)
}
}
2.3 消费者
消费者代码和生产者思路一致,首先创建一个 配置对象,通过
sarama.NewConsumer()来创建消费者,然后通过 consumer.ConsumePartition() 监听到一个分区,进行消息消费。
通过 select 来区分是否成功获取到消息,还是获取到错误。
package main
import (
"log"
"github.com/Shopify/sarama"
)
func main() {
// 配置 Kafka 消费者
config := sarama.NewConfig()
config.Consumer.Return.Errors = true
// 创建 Kafka 消费者
consumer, err := sarama.NewConsumer([]string{"192.168.1.20:9092"}, config)
if err != nil {
log.Fatal(err)
}
// 延迟关闭消费者链接
defer consumer.Close()
//订阅主题,获取分区 partition
partitionConsumer, err := consumer.ConsumePartition("go-test", 0, sarama.OffsetOldest)
if err != nil {
log.Fatalf("Consuming partition: %v", err)
}
// 延迟关闭分区链接
defer partitionConsumer.Close()
// 消费消息
for {
select {
// 从 分区 通道中获取信息
case msg := <-partitionConsumer.Messages():
log.Printf("Received message: %s", string(msg.Value))
// 如果从通道中获取消息失败
case err := <-partitionConsumer.Errors():
log.Fatalf("Received error: %v", err)
}
}
}
运行结果如下:
- 首先执行消费者:
PS D:\workspaceGo\src\kafka> go run .\consumer.go
2023/09/03 09:33:10 Received message: Hello Kafka!
2023/09/03 09:33:46 Received message: Hello Kafka!
2023/09/03 09:34:32 Received message: Hello Kafka!
2023/09/03 09:34:32 Received message: Hello Kafka!
2023/09/03 09:34:32 Received message: Hello Kafka!
2023/09/03 09:34:32 Received message: Hello Kafka!
2023/09/03 09:34:32 Received message: Hello Kafka!
2023/09/03 09:34:32 Received message: Hello Kafka!
2023/09/03 09:34:32 Received message: Hello Kafka!
2023/09/03 09:34:32 Received message: Hello Kafka!
- 再执行生产者:
PS D:\workspaceGo\src\kafka> go run .\producer.go
2023/09/03 09:34:32 Message sent to partition 0 at offset 2
2023/09/03 09:34:32 Message sent to partition 0 at offset 3
2023/09/03 09:34:32 Message sent to partition 0 at offset 4
2023/09/03 09:34:32 Message sent to partition 0 at offset 5
2023/09/03 09:34:32 Message sent to partition 0 at offset 6
2023/09/03 09:34:32 Message sent to partition 0 at offset 7
2023/09/03 09:34:32 Message sent to partition 0 at offset 8
2023/09/03 09:34:32 Message sent to partition 0 at offset 9
2023/09/03 09:34:32 Message sent to partition 0 at offset 10
2023/09/03 09:34:32 Message sent to partition 0 at offset 11
四、总结
此篇中,首先对 Kafka 有了一个初步的介绍,相对于有开发经验的大佬来说,Kafka 再熟悉不过了,不过时间长不用的话难免有点生疏了。
至于如何搭建 Kafka 则是网上资料无数。
接下来就是 Go 操作 Kafka,主要是消息生产者 和 消息消费者 两个示例程序,比较简单,适合我这种菜鸟级别的 Gopher。
那 Go 操作 Kafka 有优点和需要注意的点呢?
优点:
- 高性能: Go 是一门编译型语言,性能高且延迟低,适合处理大量的消息。
- 并发支持: Go 天生支持并发,对于多个 Topic 和 Partition 并行处理非常有帮助。
- 丰富的库支持: Go 社区有丰富的 Kafka 客户端,比如:Sarama。
- 轻量级: Go 语言本身非常轻量级,构建的二进制文件小巧,适合于微服务和容器化构建。
- 跨平台支持: Go 支持多个平台,在不同的操作系统上运行。
需要注意的点:文章来源:https://www.toymoban.com/news/detail-705364.html
- 版本兼容: 确保使用的 Kafka 客户端版本兼容,不同的版本可能有不同的特性和 API。
- 异常处理: 需要尽可能的处理错误和异常,以确保消息可靠的 生产 和 消费。
- 序列化和反序列化: 在消息 生产 和 消费的过程中,正确的进行消息的序列化和反序列化,确保消息正确传递。
- 监控和调试: 适当的监控和日志记录,以便调试和故障排除。
现阶段还是对 Go 语言的学习阶段,想必有一些地方考虑的不全面,本文示例全部是亲自手敲代码并且执行通过。
如有问题,还请指教。
评论去告诉我哦!!!一起学习一起进步!!!文章来源地址https://www.toymoban.com/news/detail-705364.html
到了这里,关于GO学习之 消息队列(Kafka)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!