⭐前言
大家好,我是yma16,本文分享关于 让大模型分析csdn文章质量 —— 提取csdn博客评论在开源大模型分析评论区内容。
vue3系列相关文章:
vue3 + fastapi 实现选择目录所有文件自定义上传到服务器
前端vue2、vue3去掉url路由“ # ”号——nginx配置
csdn新星计划vue3+ts+antd赛道——利用inscode搭建vue3(ts)+antd前端模板
认识vite_vue3 初始化项目到打包
python_selenuim获取csdn新星赛道选手所在城市用echarts地图显示
python系列文章:
python爬虫_基本数据类型
python爬虫_函数的使用
python爬虫_requests的使用
python爬虫_selenuim可视化质量分
python爬虫_django+vue3可视化csdn用户质量分
python爬虫_正则表达式获取天气预报并用echarts折线图显示
python爬虫_requests获取bilibili锻刀村系列的字幕并用分词划分可视化词云图展示
python爬虫_selenuim登录个人markdown博客站点
python爬虫_requests获取小黄人表情保存到文件夹
python_selenuim获取csdn新星赛道选手所在城市用echarts地图显示
什么是自然语言处理
自然语言处理(Natural Language Processing,简称NLP),指的是计算机科学和人工智能领域中研究人类语言和计算机之间的相互作用的一门技术。其目标是让计算机能够理解、处理、生成和运用自然语言。NLP技术包括文本分类、情感分析、语言翻译、问答系统等诸多领域,应用广泛。
insicode演示项目
⭐技术栈选择
前端:vue3 + antd
后端:python + django
引用开源大模型: 文心一言
⭐前端页面搭建
vue3搭建页面
<script setup lang="ts">
import { reactive } from 'vue'
import { getRemoteCsdnCommit, askGpt } from '../../service/csdnApi.js'
import { message } from 'ant-design-vue';
const state: any = reactive({
loading: false,
analysis:'',
text: '',
articleId: '133955447',
page: 1,
pageSize: 10,
unfold: '',
commitId: ''
})
const getCommit = async () => {
state.loading = true
state.text = ''
const params = { ...state }
delete params.text
delete params.loading
try {
const result = await getRemoteCsdnCommit(params)
console.log(result, 'result')
const { data } = result?.data
if (data?.list) {
state.text = data.list.map((item:any) => item.info.content).join(',')
}
}
catch (e) {
message.warning(JSON.stringify(e))
}
finally {
state.loading = false
}
}
const analysisCommit = async () => {
try {
console.log('state.text',state.text)
const res = await askGpt({
content: '帮我分析总结这些评论' + state.text
})
if(res?.data?.result){
state.analysis=res?.data?.result
}
}
catch (e) {
message.warn(JSON.stringify(e))
}
}
</script>
<template>
<a-spin :spinning="state.loading">
<div>
<div style="display: flex;">
<div style="width:50%">
<div>
articleId: <a-input v-model:value="state.articleId" />
</div>
<div>
page: <a-input v-model:value="state.page" />
</div>
<div>
pageSize: <a-input v-model:value="state.pageSize" />
</div>
<div>
unfold: <a-input v-model:value="state.unfold" />
</div>
<div>
commitId: <a-input v-model:value="state.commitId" />
</div>
</div>
<div style="width:50%;display: flex;justify-content: center;align-items: center;">
<a-button @click="getCommit">获取评论</a-button>
</div>
</div>
<div>
<div class="des">
评论
</div>
<a-textarea v-model:value="state.text" placeholder="评论" :disabled="state.loading"
:auto-size="{ minRows: 2, maxRows: 5 }" />
</div>
<div style="margin-top:10px;;width:100%;display: flex;justify-content: center;align-items: center;">
<a-button @click="analysisCommit">文心一言分析评论</a-button>
</div>
<div style="margin-top:10px;">
<div class="des">
生成的文章总结
</div>
<a-textarea v-model:value="state.analysis" placeholder="生成的文章总结" readonly
:auto-size="{ minRows: 2, maxRows: 5 }" />
</div>
</div>
</a-spin>
</template>
页面效果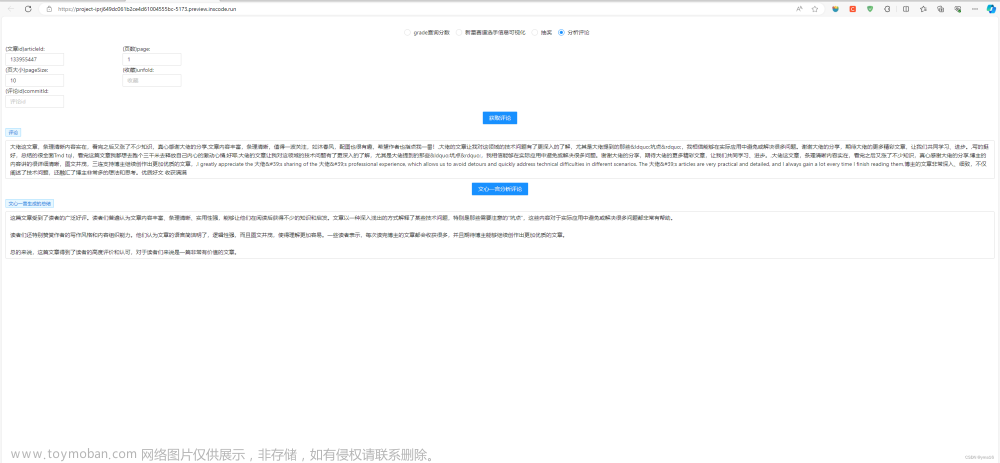
⭐后端获取数据暴露接口
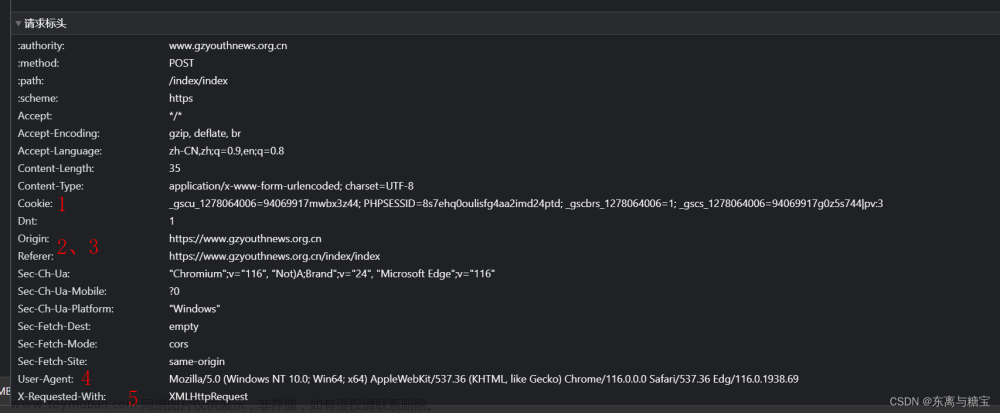
分析接口:
💖requests获取数据
import requests
def get_article_commit(articleId,page,pageSize,unfold,commentId):
requestUrl="https://blog.csdn.net/phoenix/web/v1/comment/list/{articleId}?page={page}&size={pageSize}&fold={unfold}&commentId={commentId}".\
format(articleId=articleId,page=page,pageSize=pageSize,unfold=unfold,commentId=commentId)
refererUrl = 'https://blog.csdn.net/qq_38870145/article/details/{articleId}'.format(articleId=articleId)
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
"origin": "https://blog.csdn.net",
"referer": refererUrl
}
resp=requests.get(requestUrl,headers=headers)
print('评论结果:',resp.json())
if __name__=='__main__':
get_article_commit('133955447',1,10,'unfold','')
获取数据成功!
💖 django 抛出api 接口
django views视图
# 获取csdn 评论
def getCsdnCommit(request):
if request.method == 'GET':
articleId = request.GET.get('articleId', default='')
page = request.GET.get('page', default='')
pageSize = request.GET.get('pageSize', default='')
unfold = request.GET.get('unfold', default='')
commentId = request.GET.get('commentId', default='')
if len(articleId) == 0:
return JsonResponse({"data": {}, "code": 0, "msg": 'articleId is null'})
return JsonResponse({"data": get_article_commit(articleId,page,pageSize,unfold,commentId), "code": 200,"msg":'success'})
# 获取文章评论
def get_article_commit(articleId,page,pageSize,unfold,commentId):
requestUrl="https://blog.csdn.net/phoenix/web/v1/comment/list/{articleId}?page={page}&size={pageSize}&fold={unfold}&commentId={commentId}".\
format(articleId=articleId,page=page,pageSize=pageSize,unfold=unfold,commentId=commentId)
refererUrl = 'https://blog.csdn.net/qq_38870145/article/details/{articleId}'.format(articleId=articleId)
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
"origin": "https://blog.csdn.net",
"referer": refererUrl
}
resp=requests.get(requestUrl,headers=headers)
if resp.json()['code'] is 200:
return resp.json()['data']
return {
'count':0,
'pageCount':0,
'foldCount':0,
'list':[]
}
⭐效果
查询评论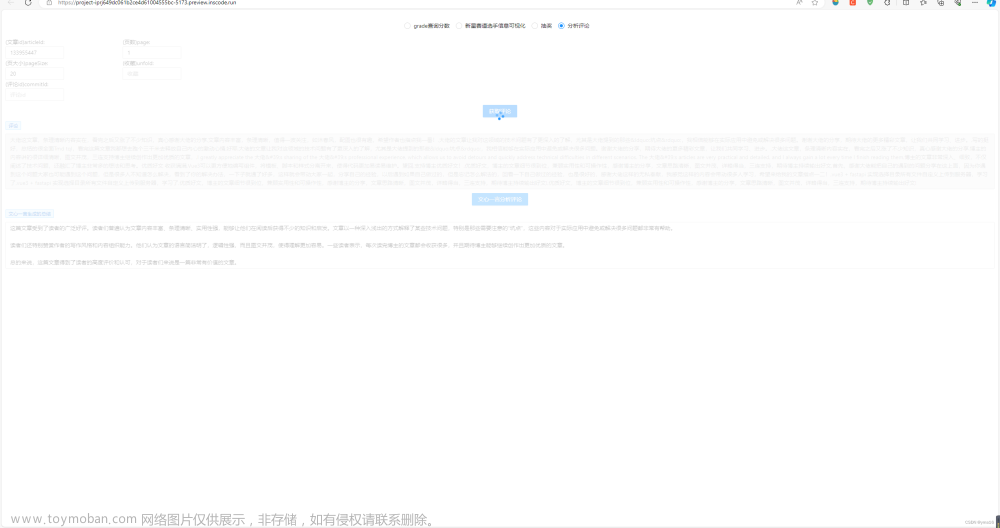
总结评论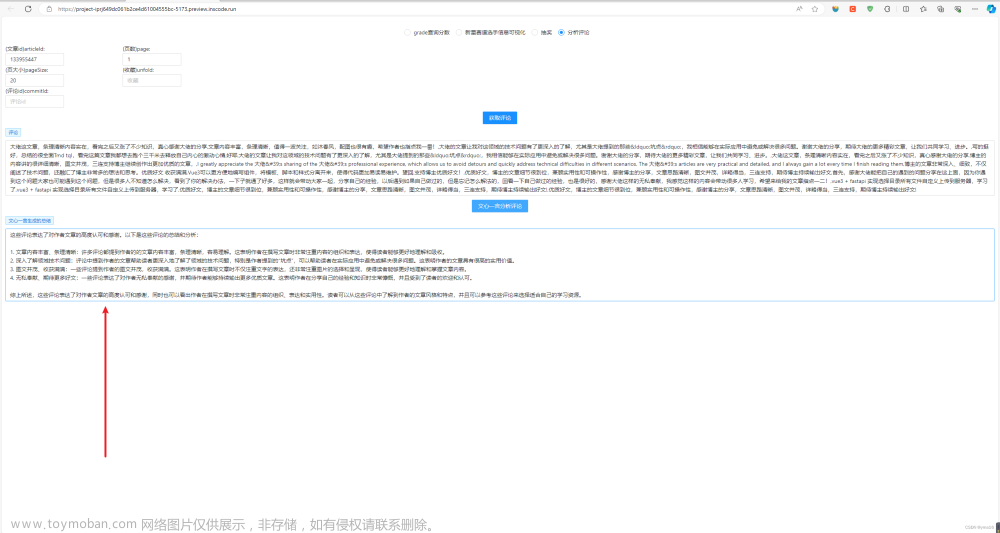
⭐结束
本文分享到这结束,如有错误或者不足之处欢迎指出! 文章来源:https://www.toymoban.com/news/detail-712974.html
文章来源:https://www.toymoban.com/news/detail-712974.html
👍 点赞,是我创作的动力!
⭐️ 收藏,是我努力的方向!
✏️ 评论,是我进步的财富!
💖 感谢你的阅读!文章来源地址https://www.toymoban.com/news/detail-712974.html
到了这里,关于让大模型分析csdn文章质量 —— 提取csdn博客评论在文心一言分析评论区内容的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!