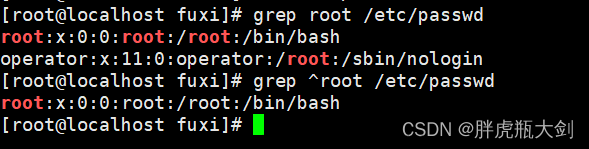
先来看一句 Shell 代码:
dpkg --list | grep -E -o 'cuda-documentation-[0-9\-]*'
-
dpkg --list:dpkg是 Debian 系列 Linux 发行版(如 Ubuntu)的包管理工具。--list选项用于列出所有已安装的软件包。 -
|:这是一个管道符号,用于将前一个命令的输出作为后一个命令的输入。在这里,dpkg --list的输出被直接传递给grep命令。 -
grep -E -o 'cuda-documentation-[0-9\-]*':grep是一个用于在文本中搜索匹配某个模式的命令。-
-E:这是一个选项,用于启用扩展的正则表达式匹配。 -
-o:这个选项告诉grep只输出匹配的部分,而不是整行。 -
'cuda-documentation-[0-9\-]*':这是要搜索的模式。它匹配任何以“cuda-documentation-”开头,后面跟着 0 个或多个数字或短横线(-)的字符串。
-
在这里 [0-9\-]* 就是正则表达式。
正则表达式 用来指定字符串的 模式,经常用于搜索-替换操作。
Regular expressions are used to specify patterns of characters。
这里,术语 模式 (pattern),是指一种用于解决特定问题的、可重复使用的解决方案。模式是一种经过验证的、解决特定问题的最佳实践。
在正则表达式中,普通字符匹配自身,特定字符拥有特殊的含义,这些特定字符称为 元字符。
元字符 是指有特殊含义的字符。比如字符 ~ 在文本中表示“波浪号”,但在 Shell 环境中,~ 是一个元字符,表示 home 目录。如果要从字面上使用它们,则需要转义,要用到表示转义的元字符 \ ,像 \~ 这样。对比下面的例子:
echo ~
输出:/home/nano
echo \~
输出:~
下面开始介绍正则表达式中的元字符,这也是正则表达式的语法。
正则表达式语法汇总
基本匹配元字符
| 基本匹配元字符 | 含义 |
|---|---|
| . | 除新行(newline:\n)字符外,匹配任意的单个字符 |
| ^ | 锚:匹配行的开头 |
| $ | 锚:匹配行的末尾 |
| \< | 锚:匹配单词的开头 |
| \> | 锚:匹配单词的末尾 |
| [list] | 字符类:匹配 list 中的任何一个字符 |
| [^list] | 字符类:匹配不在 list 中的任何一个字符 |
| () | 组(group):视为一个单独的单元 |
| | | 或(alternation):匹配选择任意一个 |
| \ | 引用(quote):从字面上解释元字符 |
注1:锚(anchor),指定正则表达式的开头和结尾,从而匹配特定的字符串或文本。
注2:字符类(character class),在正则表达式中,可以使用方括号([])来定义一个字符类。字符类可以包含一个或多个字符。
注3:引用(quote),它指的是通过特定字符或语法将文本包围起来,以保护文本中的特殊字符不受解释或转义。比如在正则表达式语法中,$ 表示匹配行的末尾,如果想查找的字符串中包含这个符号时怎么办?这时要用 引用 ,即用 \$ 来表示美元符号。
运算符元字符
| 运算符元字符 | 含义 |
|---|---|
| * | 匹配(match) 0 次或多次 |
| + | 匹配 1 次或多次 |
| ? | 匹配 0 次或 1 次 |
| {n} | 限定(bound):匹配 n 次 |
| {n,} | 限定:最少匹配 n 次 |
| {,m} | 限定:最多匹配 m 次 |
| {n,m} | 限定:最少匹配 n 次,最多匹配 m 次 |
预定义字符类
| 字符类 | 含义 | 类似于 |
|---|---|---|
| [:lower:] | 小写字母 | a-z |
| [:upper:] | 大写字母 | A-Z |
| [:alpha:] | 大小写字母 | A-Za-z |
| [:alnum:] | 大小写字母、数字 | A-Za-z0-9 |
| [:digit:] | 数字 | 0-9 |
| [:punct:] | 标点符号 | - |
| [:blank:] | 空格或制表符 | - |
使用总则
为了创建正则表达式,需要根据特定的规则将普通字符和元字符组合在一起,然后使用该正则表达式搜索希望查找的字符串。
使用举例
匹配任意的单个字符: .
grep 'Har..y' data.txt
搜索文件 data.txt ,查找类似于以下单词的 行 :
harley、harxxy、har12y
匹配行:^ 、 $
假设 data.txt 文件中有以下 4 行内容:
Harley is smart
Harley
I like Harley
the dog likes the cat
- 普通查找
grep 'Harley' data.txt
将输出以下三行:
Harley is smart
Harley
I like Harley
- 而如果正则表达式使用
^锚定为匹配行的开头,代码如下:
grep '^Harley' data.txt
将输出以下两行:
Harley is smart
Harley
之所以不选取第三行,是因为第三行中的 Harley 不在一行的开头部分。
- 如果正则表达式使用
$锚定为匹配行的结尾,代码如下:
grep 'Harley$' data.txt
将输出以下两行:
Harley
I like Harley
之所以不选取第一行,是因为第一行中的 Harley 不在行的结尾部分。
- 同时锚定行首和行尾
grep '^Harley$' data.txt
搜索整行就一个单词“Harley”的行,输出:
Harley
小技巧:
grep ‘^$’ data.txt | wc -l
这个命令将统计在 data.txt 文件中的空行数量。
匹配单词:\< 、 \>
grep '\<kn' data.txt # 以“kn”为开头的单词所在行
grep 'ow\>' data.txt # 以“ow”为结尾的单词所在行
grep '\<know\>' data.txt # 包含单词 “know” 的行
需要注意的是,当使用正则表达式时,单词 的定义要比英语中的定义更灵活。在正则表达式中,单词就是一个由字母、数字或者下划线(_)构成的连续字符序列,比如 error_code_5 是合法的单词。
匹配字符类:[list] 、 [^list]
. 匹配的是任意的字符,如果需要匹配特定字符,可以将这些字符放在方括号([])中来指定希望搜索的字符。这样的结构就称为一个字符类。
grep 'H[aA]' data.txt
搜索文件 data.txt ,查找所有包含字符 “Ha” 或 “HA” 的 行 。
如果特定的字符是一个连续范围,则可以将第一个字符和最后一个字符用连字符(-)分开:
grep 'H[0-9]' data.txt
搜索文件 data.txt ,查找所有包含字符 “H0” 、 “H1” 、… “H9” 的 行 。
匹配不在字符类中的字符,只需要在开头的左方括号之后放一个音调符号(^)即可:
grep 'H[^aA]' data.txt
搜索文件 data.txt ,查找所有包含字符 ‘X’,同时后面不跟有 “a” 或 “A”的 行 。
预定义字符类:[:xxxx:]
字符类 的特殊用法,预定义一些常用的字符集。
grep '21[[:alpha:]]' data.txt
搜索文件 data.txt ,查找所有包含数字 “21”,后面跟一个小写字母或大写字母的所有行。
注意必须包含第二组方括号。
另外记住的是:每一个预定义字符类只表示一个单独的字符。
重复运算符:* 、+ 、?
grep ':.*:' data.txt #包含 1 个冒号,后跟 0 个或多个任意字符,后面再跟 1 个冒号
grep ':.+:' data.txt #包含 1 个冒号,后跟 1 个或多个任意字符,后面再跟 1 个冒号
grep ':.?:' data.txt #包含 1 个冒号,后跟 0 个或 1 个任意字符,后面再跟 1 个冒号
限定运算符:{n}、 {n,}、{,m}、{n,m}
grep '[0-9]{3}' data.txt #正好匹配 3 个数字
grep '[0-9]{3,}' data.txt #至少匹配 3 个数字
grep '[0-9]{,5}' data.txt #最多匹配 5 个数字
grep '[0-9]{3,5}' data.txt #匹配 3~5 个数字
组(())和或(|)
如果希望在文件中搜索包含下述任意一个单词的行:
cat dog bird hamster
可以使用如下命令:
grep '\<(cat|dog|bird|hamster)\>' data.txt
注意使用圆括号(())创建一个组,这将允许我们将整个模式视为一个单元。
通配符
每当键入以文件名作为参数的命令时,可以通过使用特定的元字符 —— 通配符 来指定多个文件。术语 元字符 就是由 shell 解释时拥有特殊含义的字符。当在文件名中使用通配符时,通配符就拥有特殊的含义。
ls h* #列举当前工作目录中的所有以字母 ‘h’ 开头的文件
咋一看,通配符与正则表达式的元字符极其相似。实际上,通配符更加简单一些。此外,它们只有一个用途:当键入一条命令时匹配一组文件名。正则表达式中的预定义字符类也适用于通配符。以下为基本通配符极其含义:
| 符号 | 含义 |
|---|---|
| * | 匹配 0 个或多个字符构成的序列 |
| ? | 匹配任何单个字符 |
| [list] | 匹配 list 中的任何字符(定义字符集合) |
| [^list] | 匹配不在 list 中的任何字符 |
| {string1,string2,…} | 依次匹配每个字符串 (注意逗号前后不能有空格) |
比如:
-
d?:以 d 开头的两个字符的文件名 -
?*y:至少两个字符,并且以 y 结尾的文件名 -
test.[co]:test.c 或 test.o -
ls [^Hh]*:显示工作目录中所有不以字母 H 或 h 开头的文件名 -
[a-z]*:以小写字母开头的文件名 -
ls /home/{abc,xyz,123}:分别列举 /home/abc、/home/xyz、/home/123 中所有文件的名称 -
mkdir ~/work/{abc,xyz,123}:在 /home/work/ 目录下创建三个文件夹,分别是 abc、xyz、123
文章来源:https://www.toymoban.com/news/detail-720044.html
读后有收获,资助博主养娃 - 千金难买知识,但可以买好多奶粉 (〃‘▽’〃) 文章来源地址https://www.toymoban.com/news/detail-720044.html
文章来源地址https://www.toymoban.com/news/detail-720044.html
到了这里,关于Linux Shell :正则表达式的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!