Apache Flink PMC 已正式发布 Apache Flink 1.18.0 版本。与往常一样,这是一个充实的版本,包含了广泛的改进和新功能。总共有 174 人为此版本做出了贡献,完成了 18 个 FLIPs 和 700 多个问题。感谢各位贡献者的支持!
Tips:点击「阅读原文」免费领取 5000CU*小时 Flink 云资源
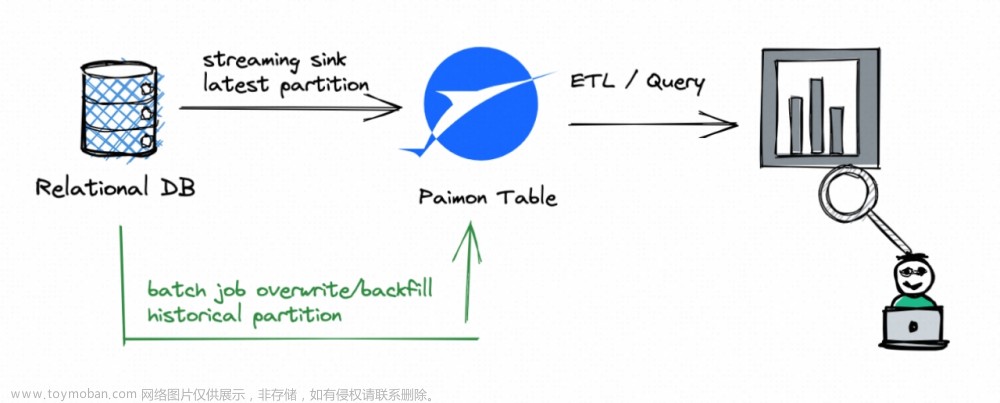
迈向 Streaming Lakehouse
Flink SQL 提升
■ Flink SQL Gateway 的 JDBC Driver
Flink 1.18 版本提供了 Flink SQL Gateway 的 JDBC Driver。因此,您现在可以使用支持 JDBC 的任何 SQL 客户端通过 Flink SQL 与您的表进行交互。以下是使用 SQLLine [1] 的示例。
sqlline version 1.12.0
sqlline> !connect jdbc:flink://localhost:8083
Enter username for jdbc:flink://localhost:8083:
Enter password for jdbc:flink://localhost:8083:
0: jdbc:flink://localhost:8083> CREATE TABLE T(
. .)> a INT,
. .)> b VARCHAR(10)
. .)> ) WITH (
. .)> 'connector' = 'filesystem',
. .)> 'path' = 'file:///tmp/T.csv',
. .)> 'format' = 'csv'
. .)> );
No rows affected (0.122 seconds)
0: jdbc:flink://localhost:8083> INSERT INTO T VALUES (1, 'Hi'), (2, 'Hello');
+----------------------------------+
| job id |
+----------------------------------+
| fbade1ab4450fc57ebd5269fdf60dcfd |
+----------------------------------+
1 row selected (1.282 seconds)
0: jdbc:flink://localhost:8083> SELECT * FROM T;
+---+-------+
| a | b |
+---+-------+
| 1 | Hi |
| 2 | Hello |
+---+-------+
2 rows selected (1.955 seconds)
0: jdbc:flink://localhost:8083>更多信息
-
文档 [2]
-
FLIP-293: Introduce Flink Jdbc Driver For Sql Gateway [3]
■ Flink 连接器的存储过程(Stored Procedure)支持
存储过程(Stored Procedure)在传统数据库中一直是不可或缺的工具,它提供了一种方便的方式来封装用于数据操作和任务管理的复杂逻辑。存储过程还提供了增强性能的潜力,因为它们可以直接在外部数据库中触发数据操作的处理。其他流行的数据系统如 Trino 和 Iceberg 将常见的维护任务自动化并简化为一小组存储过程,从而大大减轻了用户的管理负担。
本次更新主要针对 Flink 连接器的开发人员,他们现在可以通过 Catalog 接口预定义自定义存储过程到连接器中。对用户的主要好处是,以前需要编写自定义 Flink 代码来实现的连接器特定任务现在可以用封装化、标准化和潜在优化底层操作的简单调用来替代。用户可以使用熟悉的 CALL 语法执行存储过程,并使用 SHOW PROCEDURES 查看连接器的可用存储过程。连接器内的存储过程提高了 Flink 的 SQL 和 Table API 的可扩展性,为用户提供更顺畅的数据访问和管理能力。
用户可以使用 CALL 语句来直接调用 catalog 内置的存储过程(注:catalog 内置的存储过程请参考对应 catalog 的文档)。比如可以通过如下 CALL 语句对 Paimon 表进行 compact 操作:
CREATE TABLE `paimon`.`default`.`T` (
id BIGINT PRIMARY KEY NOT ENFORCED,
dt STRING, -- format 'yyyy-MM-dd'
v STRING
);
-- use catalog before call procedures
USE CATALOG `paimon`;
-- compact the whole table using call statement
CALL sys.compact('default.T');更多信息
-
文档 [4]
-
FLIP-311: Support Call Stored Procedure [5]
■ DDL 支持扩展
从 1.18 版本开始,Flink 支持以下功能:
-
REPLACE TABLE AS SELECT
-
CREATE OR REPLACE TABLE AS SELECT
这两个命令以及之前支持的 CREATE TABLE AS 现在都支持原子性,前提是底层连接器也支持。
此外,Apache Flink 现在支持在批处理模式下执行 TRUNCATE TABLE。与以前一样,底层连接器需要实现并提供此功能。
最后,我们还实现了通过以下方式支持添加、删除和列出分区:
-
ALTER TABLE ADD PARTITION
-
ALTER TABLE DROP PARTITION
-
SHOW PARTITIONS
更多信息
-
TRUNCATE 文档 [6]
-
CREATE OR REPLACE 文档 [7]
-
ALTER TABLE 文档 [8]
-
FLIP-302: Support TRUNCATE TABLE statement in batch mode [9]
-
FLIP-303: Support REPLACE TABLE AS SELECT statement [10]
-
FLIP-305: Support atomic for CREATE TABLE AS SELECT(CTAS) statement [11]
■ 时间旅行(Time Traveling)
Flink 支持时间旅行(time travel) SQL 语法,用于查询历史版本的数据。用户可以指定一个时间点,来检索表在该时间点的数据和架构。借助时间旅行功能,用户可以轻松分析和比较数据的历史版本。
例如,用户可以通过如下的语句查询一张表指定时间点的数据;
-- 查询表 `paimon_tb` 在 2022年11月11日的数据
SELECT * FROM paimon_tb FOR SYSTEM_TIME AS OF TIMESTAMP '2022-11-11 00:00:00';更多信息
-
文档 [12]
-
FLIP-308: Support Time Travel [13]
流处理提升
■ Table API & SQL 支持算子级别状态保留时间(TTL)
从 Flink 1.18 版本开始,Table API 和 SQL 用户可以为有状态的算子单独设置状态保留时间 (TTL)。在像流 regular join 这样的场景中,用户现在可以为左侧和右侧流设置不同的 TTL。在以前的版本中,状态保留时间只能在 pipeline 级别使用配置项 table.exec.state.ttl 进行控制。引入算子级别的状态保留后,用户现在可以根据其具体需求优化资源使用。
更多信息
-
文档 [14]
-
FLIP-292: Enhance COMPILED PLAN to support operator-level state TTL configuration [15]
■ SQL 的水印对齐(Watermark Alignment)和空闲检测(Idleness Detection)
现在,您可以使用 SQL Hint 配置水印对齐 [16]和数据源空闲超时 [17]。之前这些功能仅在 DataStream API 中可用。
更多信息
-
文档 [18]
-
FLIP-296:Extend watermark-related features for SQL [19]
批处理提升
■ Hybrid Shuffle 支持远程存储
Hybrid Shuffle 支持将 Shuffle 数据存储在远程存储中。可以使用配置项 taskmanager.network.hybrid-shuffle.remote.path 配置远程存储路径。Hybrid Shuffle 通过将内存用量与并行度解耦,减少了网络内存的使用,提高了稳定性和易用性。
更多信息
-
文档 [20]
-
FLIP-301: Hybrid Shuffle supports Remote Storage [21]
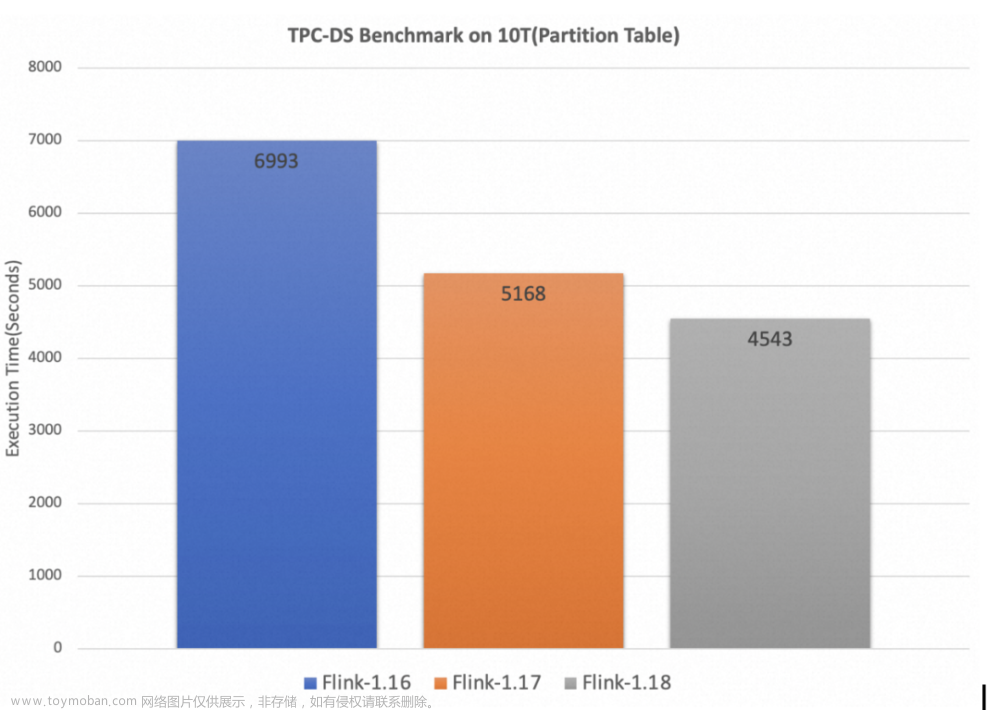
■ 性能提升与 TPC-DS 基准测试
在之前的版本中,社区投入了大量精力来改进 Flink 的批处理性能,产生了显著的改进。在这个发布周期中,社区的贡献者继续付出了重大努力,进一步改进了 Flink 的批处理性能。
Flink SQL 的运行时过滤(Runtime Filter)
运行时过滤(Runtime Filter)是用于优化 join 性能的常见方法。它旨在动态生成某些 join 查询的运行时过滤条件,以减少扫描或 Shuffle 的数据量,避免不必要的 I/O 和网络传输,从而加速查询。我们在 Flink 1.18 版本引入了运行时过滤,并通过 TPC-DS 基准测试验证了其有效性,观察到启用此功能后,某些查询的速度提高了 3 倍。
Flink SQL 算子的融合代码生成(Operator Fusion Codegen)
算子融合代码生成(Operator Fusion Codegen)通过将算子 DAG 融合成一个经过优化的单算子,消除了虚函数调用,利用 CPU 寄存器进行中间数据操作,并减少指令缓存不命中的情况,从而提高了查询的执行性能。作为一项技术优化,我们通过 TPC-DS 验证了其有效性,部分批处理算子(Calc、HashAgg 和 HashJoin)在 1.18 版本中完成了融合代码生成支持,很多查询性能显著提高。
请注意,上述两个功能默认情况下处于关闭状态。可以通过使用 table.optimizer.runtime-filter.enabled 和 table.exec.operator-fusion-codegen.enabled 两个配置项来启用它们。
自 Flink 1.16 以来,Apache Flink 社区一直在通过 TPC-DS 基准测试框架持续跟踪其批处理引擎的性能。在 Flink 1.17 版本中经过重大改进(动态 join 重排序、动态 local aggregation)后,前面描述的两项改进(算子融合、运行时过滤)在分区表 10T 数据集上,与 Flink 1.17 相比性能提高了 14%,与 Flink 1.16 相比性能提高了 54%。
更多信息
-
FLIP-324: Introduce Runtime Filter for Flink Batch Jobs [22]
-
FLIP-315: Support Operator Fusion Codegen for Flink SQL [23]
-
Benchmarking 代码仓库 [24]
迈向云原生弹性化
弹性化(Elasticity)描述了系统在不中断的情况下适应工作负载变化的能力,理想情况下是以自动方式进行。这是云原生系统的一个定义特征,对于长时间运行的流处理工作负载尤为重要。因此,弹性性能的改进是 Apache Flink 社区不断投入的领域。最近的提议包括 Kubernetes 自动缩放器(Autoscaler) [25]、对性能调整的众多改进,以及自适应调度器(Adaptive Scheduler) [26]。
自 Flink 1.15 版本首次引入以来,自适应调度器构成了完全弹性 Apache Flink 部署的核心。在其核心功能中,它允许作业在运行时更改其资源要求和并行度。此外,它还根据集群中可用的资源进行自适应调整,只有当集群能够满足作业的最低所需资源时才会重新调整。
在 Flink 1.18 版本之前,自适应调度器主要用于响应模式(Reactive Mode) [27],根据设计,单个作业始终会使用集群中的所有可用资源。请参阅这篇博客文章 [28],了解如何使用 Kubernetes 上的水平 Pod 自动缩放器自动缩放 Flink 作业。
在 Flink 1.18 版本中,自适应调度器变得更加强大和更广泛适用,并正在成为 Apache Flink 流处理任务的默认调度器。
通过 REST API 控制动态细粒度扩缩容
尽管自适应调度器具有在运行时更改作业资源需求的能力,但此功能之前一直未开放给用户,自 Flink 1.18 起,在作业运行时,您可以通过 Flink Web UI 和 REST API 更改作业的任何 task 的并行度。
实现细节上,Apache Flink 在获得新并行度所需的资源后会立即执行扩缩容操作。扩缩容操作不基于 savepoint,而是基于普通的定期 checkpoint,这意味着它不会引入额外的 snapshot。对于状态规模较小的作业,重新调整操作几乎立即发生,且中断时间非常短。
与 Apache Flink Web UI 的反压监控 [29]相结合,现在更容易找到并维护使每个任务高效运行、无反压的并行度。
-
如果一个任务非常繁忙(红色),您可以增加并行度。
-
如果一个任务大部分时间处于空闲状态(蓝色),您可以减少并行度。
更多信息
-
FLIP-291: Externalized Declarative Resource Management [30]
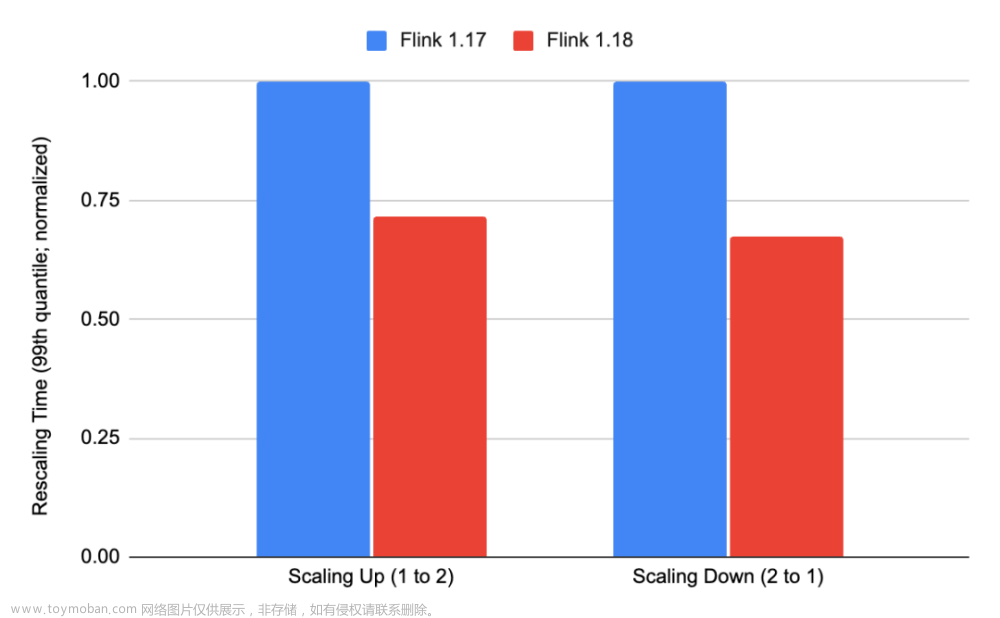
更快地 RocksDB 扩缩容
使用 RocksDB 状态后端和增量 checkpoint 的扩缩容时间在第 99 百分位数(99th percentile)上提高了约 30%。我们提升了并行下载的能力,从只并行下载状态句柄(state handle),扩展到并行下载文件。此外,我们关闭了用于扩缩容的临时 RocksDB 实例在批量插入时的写前日志(write-ahead-logging)。
更多信息
-
FLINK-32326 [31]
-
FLINK-32345 [32]
Java 17 支持
Java 17 于 2021 年发布,是 Java 的最新长期支持(LTS)版本,将于 2029 年终止支持。从 Flink 1.18 版本开始,您现在可以在 Java 17 上运行 Apache Flink。官方 Docker 仓库 [33]目前已包含基于 Java 17 的镜像:
docker pull flink:1.18.0-java17如果您的集群运行在 Java 17 上,您的用户程序中也可以使用 Java 17 的功能,并将其编译为 Java 17 版本。
更多信息
-
文档 [34]
-
FLINK-15736 [35]
其他改进
生产可用的水印对齐(Watermark Alignment)功能
自 Flink 1.16 和 Flink 1.17 版本以来以 Beta 形式支持的水印对齐 [36]已在实际环境中经过大规模的充分测试。在此期间,社区已经收集并解决了发现的错误和性能问题。随着这些问题的解决,我们推荐水印对齐功能供一般使用。
更多信息
-
FLINK-32548 [37]
可插拔式故障处理
Apache Flink 作为许多公司流处理平台的基础,也是许多商业流处理服务的基础。因此,能够轻松集成到内部和供应商平台更广泛生态系统中的能力变得越来越重要。Catalog 修改监听器和可插拔式故障处理程序属于这一类改进。
更多信息
-
文档 [38]
-
FLIP-304: Pluggable Failure Enrichers [39]
SQL 客户端的改进
在 1.18 版本中,SQL 客户端进行了一系列的易用性改进:
-
客户端更加多彩,可开启 SQL 语法突出显示和切换 7 种不同配色方案。
-
更容易编辑和预览大查询。
-
可随时关闭和打开行号。
更多信息
-
FLIP-189: SQL Client Usability Improvements [40]
Apache Pekko 代替 Akka
一年前,Lightbend 宣布 [41]将 Akka 未来版本(2.7+)的许可证从 Apache 2.0 更改为 BSL,Apache Flink 使用的 Akka 2.6 版本将在 2023 年 9 月之前接收安全更新和关键错误修复。因此在 Flink 1.18 版本,我们决定从 Akka 切换到Apache Pekko(Incubating)。Apache Pekko [42](Incubating) 基于 Akka 项目采用商业源代码许可证之前的 Akka 2.6.x。Pekko 最近发布了 Apache Pekko 1.0.1-incubating,我们即刻在 Flink 1.18 中进行使用。虽然我们的中期计划是完全放弃对 Akka 或 Pekko 的依赖(参见 FLINK-29281 [43]),但切换到 Pekko 提供了一个良好的短期解决方案,并确保了 Apache Pekko 和 Apache Flink 社区能够处理整个软件供应链中的关键错误修复和安全漏洞。
更多信息
-
FLINK-32468 [44]
Calcite 升级
在 Apache Flink 1.18 中,Apache Calcite 逐渐从 1.29 版本升级到 1.32 版本。版本升级的带来的好处包括错误修复、更智能的优化器和性能改进。在解析器级别,它现在允许使用括号将 join 操作分组成树状结构(SQL-92)。例如 SELECT * FROM a JOIN (b JOIN c ON b.x = c.x) ON a.y = c.y,请参阅 CALCITE-35 [45]。此外,升级到 Calcite 1.31+ 解锁了通过表值函数支持会话窗口(Session Windows via Table-Valued Functions,参见 CALCITE-4865 [46]、FLINK-24024 [47]),并弃用旧的分组窗口聚合(Group Window Aggregations)。由于 CALCITE-4861 [48],Flink 的强制类型转换行为略有改变。一些边界情况现在可能会有不同的行为:例如,从 FLOAT/DOUBLE 9234567891.12 到 INT/BIGINT 的强制类型转换会产生 Java 的溢出行为。
更多信息
-
FLINK-27998 [49]
-
FLINK-28744 [50]
-
FLINK-29319 [51]
重要 API 弃用
为了为明年发布的 Flink 2.0 版本做准备,社区已经决定正式弃用多个接近生命周期结束的 API。
-
SourceFunction [52]现在已经弃用。如果您仍在使用基于 SourceFunction 构建的连接器,请将其迁移到 Source [53]。SinkFunction 目前尚未正式弃用,但它也即将接近生命周期结束,将被 SinkV2 所取代。
-
Queryable State [54]现已弃用,将在 Flink 2.0 中移除。
-
DataSet API [55]现已弃用。建议用户迁移到执行模式 [56]设置为 BATCH 的 DataStream API。
升级注意事项
Flink 社区尽力确保无缝升级。然而,某些变更可能需要用户在升级到 1.18 版本时对程序的某些部分进行调整。请参考发行说明 [57],以获取升级过程中需要进行的调整和要检查的问题的综合列表。
贡献者列表
Apache Flink 社区向所有为这个版本的实现做出贡献的贡献者表示感谢:
Aitozi, Akinfolami Akin-Alamu, Alain Brown, Aleksandr Pilipenko, Alexander Fedulov, Anton Kalashnikov, Archit Goyal, Bangui Dunn, Benchao Li, BoYiZhang, Chesnay Schepler, Chris Nauroth, Colten Pilgreen, Danny Cranmer, David Christle, David Moravek, Dawid Wysakowicz, Deepyaman Datta, Dian Fu, Dian Qi, Dong Lin, Eric Xiao, Etienne Chauchot, Feng Jin, Ferenc Csaky, Fruzsina Nagy, Gabor Somogyi, Gunnar Morling, Gyula Fora, HaiYang Chen, Hang Ruan, Hangxiang Yu, Hanyu Zheng, Hong Liang Teoh, Hongshun Wang, Huston, Jacky Lau, James Hughes, Jane Chan, Jark Wu, Jayadeep Jayaraman, Jia Liu, JiangXin, Joao Boto, Junrui Lee, Juntao Hu, K.I. (Dennis) Jung, Kaiqi Dong, L, Leomax_Sun, Leonard Xu, Licho, Lijie Wang, Liu Jiangang, Lyn Zhang, Maomao Min, Martijn Visser, Marton Balassi, Mason Chen, Matthew de Detrich, Matthias Pohl, Min, Mingliang Liu, Mohsen Rezaei, Mrart, Mulavar, Nicholas Jiang, Nicolas Fraison, Noah, Panagiotis Garefalakis, Patrick Lucas, Paul Lin, Peter Vary, Piotr Nowojski, Qingsheng Ren, Ran Tao, Rich Bowen, Robert Metzger, Roc Marshal, Roman Khachatryan, Ron, Rui Fan, Ryan Skraba, Samrat002, Sergey Nuyanzin, Sergio Morales, Shammon FY, ShammonFY, Shengkai, Shuiqiang Chen, Stefan Richter, Tartarus0zm, Timo Walther, Tzu-Li (Gordon) Tai, Venkata krishnan Sowrirajan, Wang FeiFan, Weihua Hu, Weijie Guo, Wencong Liu, Xiaogang Zhou, Xintong Song, XuShuai, Yanfei Lei, Yu Chen, Yubin Li, Yun Gao, Yun Tang, Yuxin Tan, Zakelly, Zhanghao Chen, ZhengYiWeng, Zhu Zhu, archzi, baiwuchang, cailiuyang, chenyuzhi, darenwkt, dongwoo kim, eason.qin, felixzh, fengli, frankeshi, fredia, godfrey he, haishui, hehuiyuan, huangxingbo, jiangxin, jiaoqingbo, jinfeng, jingge, kevin.cyj, kristoffSC, leixin, leiyanfei, liming.1018, lincoln lee, lincoln.lil, liujiangang, liuyongvs, luoyuxia, maigeiye, mas-chen, novakov-alexey, oleksandr.nitavskyi, pegasas, sammieliu, shammon, shammon FY, shuiqiangchen, slfan1989, sunxia, tison, tsreaper, wangfeifan, wangkang, whjshj, wuqqq, xiangyu0xf, xincheng.ljr, xmzhou, xuyu, xzw, yuanweining, yuchengxin, yunfengzhou-hub, yunhong, yuxia Luo, yuxiqian, zekai-li, zhangmang, zhengyunhong.zyh, zzzzzzzs, 沈嘉琦
参考
[1] SQLLine:
https://julianhyde.github.io/sqlline/manual.html
[2] 文档 :
https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/table/jdbcdriver/
[3] FLIP-293: Introduce Flink Jdbc Driver For Sql Gateway:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-293%3A+Introduce+Flink+Jdbc+Driver+For+Sql+Gateway
[4] 文档:
https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/table/procedures/
[5] FLIP-311: Support Call Stored Procedure:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-311%3A+Support+Call+Stored+Procedure
[6] TRUNCATE 文档:
https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/table/sql/truncate/
[7] CREATE OR REPLACE 文档:
https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/table/sql/create/#create-or-replace-table
[8] ALTER TABLE 文档:
https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/table/sql/alter/#alter-table
[9] FLIP-302: Support TRUNCATE TABLE statement in batch mode:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-302%3A+Support+TRUNCATE+TABLE+statement+in+batch+mode
[10] FLIP-303: Support REPLACE TABLE AS SELECT statement:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-303%3A+Support+REPLACE+TABLE+AS+SELECT+statement
[11] FLIP-305: Support atomic for CREATE TABLE AS SELECT(CTAS) statement :
https://cwiki.apache.org/confluence/display/FLINK/FLIP-305%3A+Support+atomic+for+CREATE+TABLE+AS+SELECT(CTAS)+statement
[12] 文档 :
https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/table/sql/queries/time-travel/
[13] FLIP-308: Support Time Travel:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-308%3A+Support+Time+Travel
[14] 文档:
https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/table/concepts/overview/#configure-operator-level-state-ttl
[15] FLIP-292: Enhance COMPILED PLAN to support operator-level state TTL configuration:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-292%3A+Enhance+COMPILED+PLAN+to+support+operator-level+state+TTL+configuration
[16] 水印对齐:
https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/datastream/event-time/generating_watermarks/#watermark-alignment
[17] 数据源空闲超时:
https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/datastream/event-time/generating_watermarks/#dealing-with-idle-sources
[18] 文档:
https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/table/sql/queries/hints/
[19] FLIP-296:Extend watermark-related features for SQL:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-296%3A+Extend+watermark-related+features+for+SQL
[20] 文档:
https://nightlies.apache.org/flink/flink-docs-stable/docs/ops/batch/batch_shuffle/#hybrid-shuffle
[21] FLIP-301: Hybrid Shuffle supports Remote Storage:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-301%3A+Hybrid+Shuffle+supports+Remote+Storage
[22] FLIP-324: Introduce Runtime Filter for Flink Batch Jobs:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-324%3A+Introduce+Runtime+Filter+for+Flink+Batch+Jobs
[23] FLIP-315: Support Operator Fusion Codegen for Flink SQL:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-315+Support+Operator+Fusion+Codegen+for+Flink+SQL
[24] Benchmarking 代码仓库:
https://github.com/ververica/flink-sql-benchmark
[25] 自动缩放器(Autoscaler):
https://nightlies.apache.org/flink/flink-kubernetes-operator-docs-release-1.6/docs/custom-resource/autoscaler/
[26] 自适应调度器(Adaptive Scheduler):
https://nightlies.apache.org/flink/flink-docs-stable/docs/deployment/elastic_scaling/#adaptive-scheduler
[27] 响应模式(Reactive Mode):
https://nightlies.apache.org/flink/flink-docs-stable/docs/deployment/elastic_scaling/#reactive-mode
[28] 博客文章:
https://flink.apache.org/2021/05/06/scaling-flink-automatically-with-reactive-mode/
[29] 反压监控:
https://nightlies.apache.org/flink/flink-docs-stable/docs/ops/monitoring/back_pressure/
[30] FLIP-291: Externalized Declarative Resource Management:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-291%3A+Externalized+Declarative+Resource+Management
[31] FLINK-32326:
https://issues.apache.org/jira/browse/FLINK-32326
[32] FLINK-32345:
https://issues.apache.org/jira/browse/FLINK-32345
[33] 官方 Docker 仓库:
https://hub.docker.com/_/flink
[34] 文档:
https://nightlies.apache.org/flink/flink-docs-stable/docs/deployment/java_compatibility/
[35] FLINK-15736:
https://issues.apache.org/jira/browse/FLINK-15736
[36] 水印对齐:
https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/datastream/event-time/generating_watermarks/#watermark-alignment
[37] FLINK-32548:
https://issues.apache.org/jira/browse/FLINK-32548
[38] 文档:
https://nightlies.apache.org/flink/flink-docs-stable/docs/deployment/advanced/failure_enrichers/
[39] FLIP-304: Pluggable Failure Enrichers:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-304%3A+Pluggable+Failure+Enrichers
[40] FLIP-189: SQL Client Usability Improvements:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-189%3A+SQL+Client+Usability+Improvements
[41] Lightbend 宣布:
https://flink.apache.org/2022/09/08/regarding-akkas-licensing-change/
[42] Apache Pekko:
https://pekko.apache.org/
[43] FLINK-29281:
https://issues.apache.org/jira/browse/FLINK-29281
[44] FLINK-32468:
https://issues.apache.org/jira/browse/FLINK-32468
[45] CALCITE-35:
https://issues.apache.org/jira/browse/CALCITE-35
[46] CALCITE-4865:
https://issues.apache.org/jira/browse/CALCITE-4865
[47] FLINK-24024:
https://issues.apache.org/jira/browse/FLINK-24024
[48] CALCITE-4861:
https://issues.apache.org/jira/browse/CALCITE-4861
[49] FLINK-27998:
https://issues.apache.org/jira/browse/FLINK-27998
[50] FLINK-28744:
https://issues.apache.org/jira/browse/FLINK-28744
[51] FLINK-29319:
https://issues.apache.org/jira/browse/FLINK-29319
[52] SourceFunction:
https://github.com/apache/flink/blob/master/flink-streaming-java/src/main/java/org/apache/flink/streaming/api/functions/source/SourceFunction.java
[53] Source:
https://github.com/apache/flink/blob/master/flink-core/src/main/java/org/apache/flink/api/connector/source/Source.java
[54] Queryable State:
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/datastream/fault-tolerance/queryable_state/
[55] DataSet API:
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/dataset/overview/
[56] 执行模式:
https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/datastream/execution_mode/
[57] 发行说明:
https://nightlies.apache.org/flink/flink-docs-release-1.18/release-notes/flink-1.18/
Flink Forward Asia 2023 正式启动
点击查看活动详情文章来源:https://www.toymoban.com/news/detail-739601.html
 文章来源地址https://www.toymoban.com/news/detail-739601.html
文章来源地址https://www.toymoban.com/news/detail-739601.html
到了这里,关于官宣|Apache Flink 1.18 发布公告的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!