分布式ID系统设计第三集
id-service-SnowFlake方案
第二集说了id-service-Segment-DB可以生成趋势递增的ID,但是ID号是可以计算的。不太适用于一些订单ID生成的场景。因为存在数据暴露的风险
比如我可以对比两天的订单ID号来大致计算出公司一天的订单量。这个有点危险。
所以我们需要id-serviceSnowFlake方案。
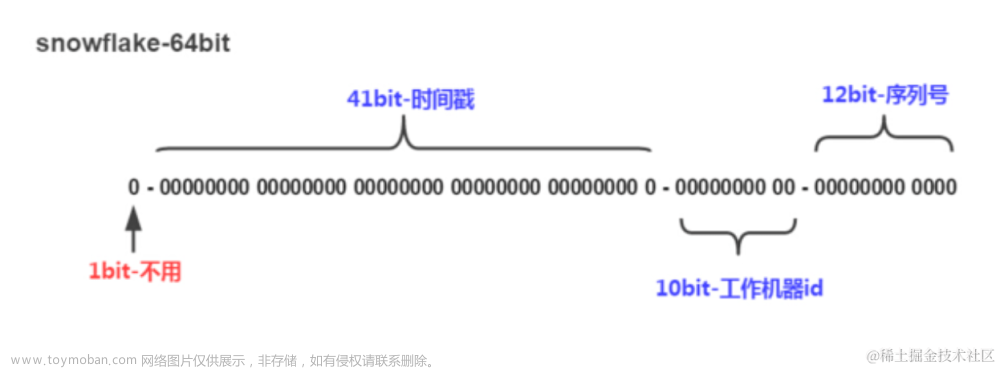
id-service-snowFlake完全沿用snowFlake方案的bit位设计。即"1+41+10+12"的方式组装id。对于workid的分配 基本上可以用手动配置。也可以借助Zk或者etcd CP实现的分布式协调者来配置。id-service-SnowFlake按照下面几个步骤启动:
1 启动id-servicesnowFlake。连接zk或者etcd。在id-service-snowflake父节点下检查自己是否已注册。
2 如果有就直接拿到自己的workId zk/etcd 生成的id 启动。
3 如果没有就在根下面生成一个节点id 当作自己的workId
4 start-service
弱依赖zk
如果想做到这一步就在本地osFile上。当zk出现问题的时候,而服务又要重启。这个时候这一步就能提高SLA.
解决时钟问题
因为这种方案依赖时间。如果机器的时钟发生了回拨。那么有可能生成重复的ID.那就需要解决这个问题。
1 首先服务注册到zk 检查自己是否写如果zk
2 如果写过 则用自己的系统时间与id-service-forever/{id}节点记录时间做比较 如果小于则认为机器时间发生了回拨,这个时候可以选择等待也可以选择失败退出。
3 如未写过 则直接注册进去。然后对比其他节点的系统时间判断自己系统时间是否正确。可以选择轮训对比 也可以选择相加/节点数对比
4 若时间正确就启动 写入zk
5 否则认为有回拨。
6 每隔一段时间上报自己的系统时间写入zk
由于强依赖时钟,对时钟要求很敏感。如果机器上有NTP时间服务同步的话。在他同步的时候会造成秒级的回拨。(不过一般的公司也不会有这种业务量 除了大厂)。解决方案就是在回拨的时候等待一段时间(1s 2s 这样)或者直接重试.再或者直接摘除节点 告警。
代码实现也很简单
/发生了回拨,此刻时间小于上次发号时间
if (timestamp < lastTimestamp) {
long offset = lastTimestamp - timestamp;
if (offset <= 5) {
try {
//时间偏差大小小于5ms,则等待两倍时间
wait(offset << 1);//wait
timestamp = timeGen();
if (timestamp < lastTimestamp) {
//还是小于,抛异常并上报
throwClockBackwardsEx(timestamp);
}
} catch (InterruptedException e) {
throw e;
}
} else {
//throw
throwClockBackwardsEx(timestamp);
}
}
从使用情况来看 基本没有出现过问题。文章来源:https://www.toymoban.com/news/detail-741258.html
id-service 情况
作为一个基架服务。性能应该是最关心的 能在4C8G机器上跑出4w QPS.可用性也能保证9999.提供给6个BU 一天有个几百万的使用量。作为基架。高SLA和高性能是必须要保证的。文章来源地址https://www.toymoban.com/news/detail-741258.html
到了这里,关于分布式ID系统设计(3)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!