Hadoop是一个开源的分布式处理系统,主要用于处理和存储大量数据。它是由Apache软件基金会开发的,现在已经成为大数据领域中广泛使用的技术之一。
Hadoop架构
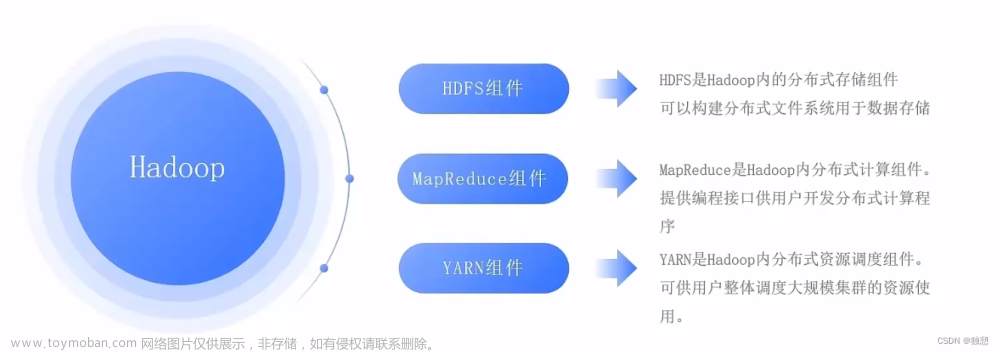
Hadoop的架构包括以下几个主要组件:文章来源地址https://www.toymoban.com/news/detail-761791.html
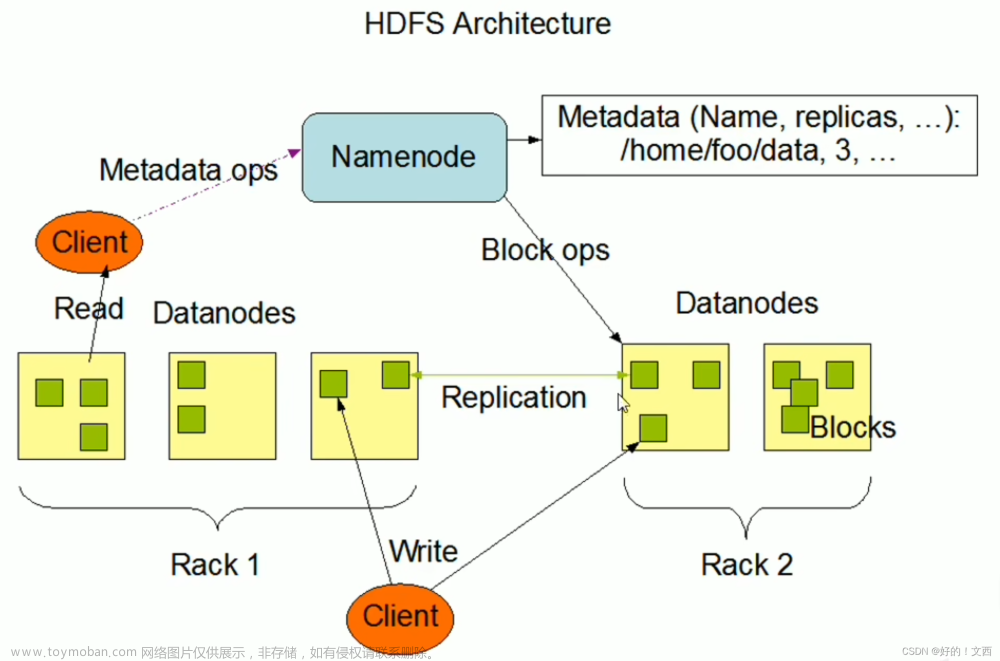
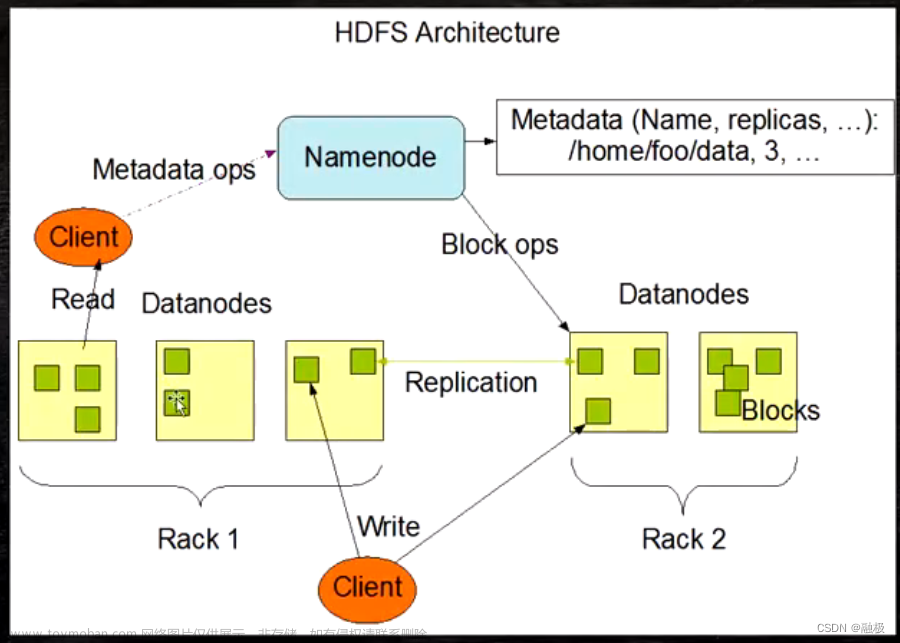
- Hadoop Distributed File System (HDFS): HDFS是Hadoop的核心组件之一,它是一个分布式文件系统,可以存储大量的数据。HDFS的设计考虑到了硬件错误和数据存储的可靠性,它采用主从架构,一个NameNode作为主服务器,管理文件系统的元数据,多个DataNode作为从服务器,负责存储实际的数据。
- Hadoop MapReduce: MapReduce是Hadoop的处理框架,用于处理和生成大数据。MapReduce编程模型是分发任务给工作节点,并在完成后收集结果。Map阶段处理输入数据并生成一系列的键值对,Reduce阶段对这些键值对进行处理。
-
Hadoop Common: 这是Hadoop的公共组件,包括其他一些必要的组件,如文件系统、分布式计算框架等。
核心组件 - NameNode: NameNode是HDFS的主服务器,负责管理文件系统的元数据。它维护了一个文件系统的目录树,并记录了文件的块信息。
- DataNode: DataNode是HDFS的工作节点,负责存储实际的数据。所有的数据都被分成块,并存储在DataNode上。
- JobTracker: 在旧版本的Hadoop中,JobTracker是MapReduce的主服务器,负责协调和处理作业。在新版本中,这个角色由ResourceManager替代。
-
TaskTracker: TaskTracker是MapReduce的工作节点,负责执行MapReduce作业中的任务。
工作原理 - 数据存储: HDFS将所有数据分成块,并存储在DataNode上。NameNode记录了文件系统的元数据和块的存储位置。
- 数据处理: MapReduce作业由用户提交到JobTracker或ResourceManager。JobTracker或ResourceManager将作业分解为一系列的任务,并分发给TaskTracker执行。Map阶段处理输入数据并生成键值对,Reduce阶段对这些键值对进行处理。
-
结果输出: MapReduce作业完成后,结果被写入HDFS或其他存储系统。
以上就是Hadoop的架构、核心组件和工作原理的简要介绍。当然,下面我将更深入地探讨Hadoop的架构和工作原理。
深入了解Hadoop架构 - HDFS架构: HDFS采用主从架构,NameNode作为主服务器,负责管理文件系统的元数据,而多个DataNode作为从服务器,负责存储实际的数据。这种架构使得HDFS具有高容错性和可扩展性。
- MapReduce架构: MapReduce框架用于处理和生成大数据。Map阶段负责处理输入数据并生成键值对,Reduce阶段则对这些键值对进行处理。MapReduce框架具有高度的可扩展性和容错性,可以处理大规模的数据集。
-
Hadoop Common: Hadoop Common是Hadoop的公共组件,包括其他一些必要的组件,如文件系统、分布式计算框架等。这些组件为Hadoop提供了基础支持。
深入了解Hadoop工作原理 - 数据存储: HDFS采用分布式存储架构,将所有数据分成块,并存储在多个DataNode上。NameNode记录了文件系统的元数据和块的存储位置,使得数据可以被高效地访问和管理。
- 数据处理: MapReduce作业由用户提交到JobTracker或ResourceManager。JobTracker或ResourceManager将作业分解为一系列的任务,并分发给TaskTracker执行。Map阶段处理输入数据并生成键值对,Reduce阶段对这些键值对进行处理。在这个过程中,Hadoop提供了丰富的数据处理功能,如排序、去重、连接等。
- 资源管理: Hadoop使用ResourceManager进行资源管理。ResourceManager负责分配和管理集群中的资源,确保作业能够公平地共享资源,并保证系统的稳定性和可靠性。
- 容错性: Hadoop具有高度的容错性。如果某个DataNode或TaskTracker出现故障,Hadoop会自动将其从集群中移除,并将任务重新分配给其他可用的节点。此外,Hadoop还提供了数据备份和恢复机制,确保数据的可靠性和完整性。
-
可扩展性: Hadoop具有出色的可扩展性。当需要处理的数据量增加时,只需添加更多的DataNode或TaskTracker到集群中即可。这使得Hadoop能够轻松应对大规模的数据处理任务。
总的来说,Hadoop是一个强大的分布式处理系统,它通过HDFS和MapReduce框架实现了数据的分布式存储和处理。Hadoop具有高容错性、可扩展性和出色的性能,使得它成为大数据领域中广泛使用的技术之一。
文章来源:https://www.toymoban.com/news/detail-761791.html
到了这里,关于Hadoop是一个开源的分布式处理系统,主要用于处理和存储大量数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!