Tangseng 基于Go语言的搜索引擎
github地址:https://github.com/CocaineCong/tangseng
详细介绍地址:https://cocainecong.github.io/tangseng
这两周我也抽空录成视频发到B站的~ 本来应该10月份就要发了,结果一鸽就鸽到现在hhhh,有兴趣的同学也可留意一下~
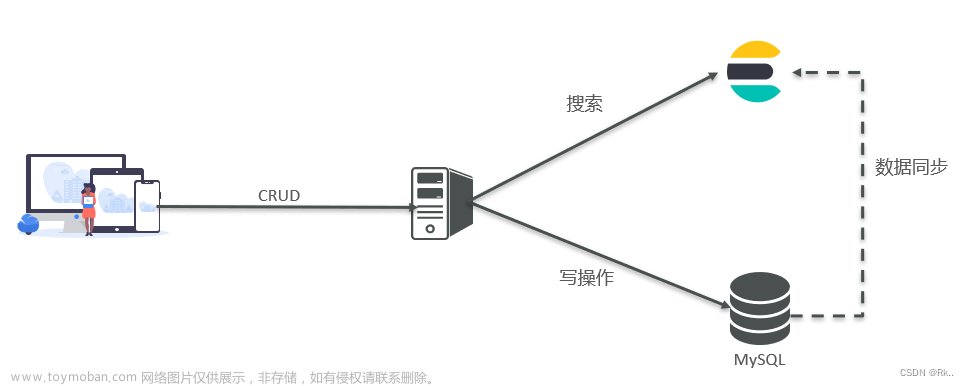
项目大体框架
- gin作为http框架,grpc作为rpc框架,etcd作为服务发现。
- 总体服务分成
用户模块、收藏夹模块、索引平台、搜索引擎(文字模块)、搜索引擎(图片模块)。注册到etcd中,并进行服务发现。 - 分布式爬虫爬取数据,并发送到kafka集群中,再落库消费。现阶段使用数据集文本输入 (虽然爬虫还没写,但不妨碍我画饼…)
- 搜索引擎模块的文本搜索单独设立使用boltdb存储index,mapreduce+kafka集群加速索引构建并使用
roaring bitmap存储索引。 - 使用 trie tree 实现词条联想。
- 图片搜索使用ResNet50来进行向量化查询 + Milvus or Faiss 向量数据库的查询 (开始做了… DeepLearning也太难了…)。
- 支持多路召回,go中进行倒排索引召回,python进行向量召回。通过grpc调用连接,进行融合。
- 支持TF-IDF,BM25等等算法排序。
- 第三方容器纯docker拉取启动。

🧑🏻💻 前端地址
all in react, but still coding react-tangseng
由于我真的不怎么会写前端,前端大佬别骂了…这里就放两个页面…
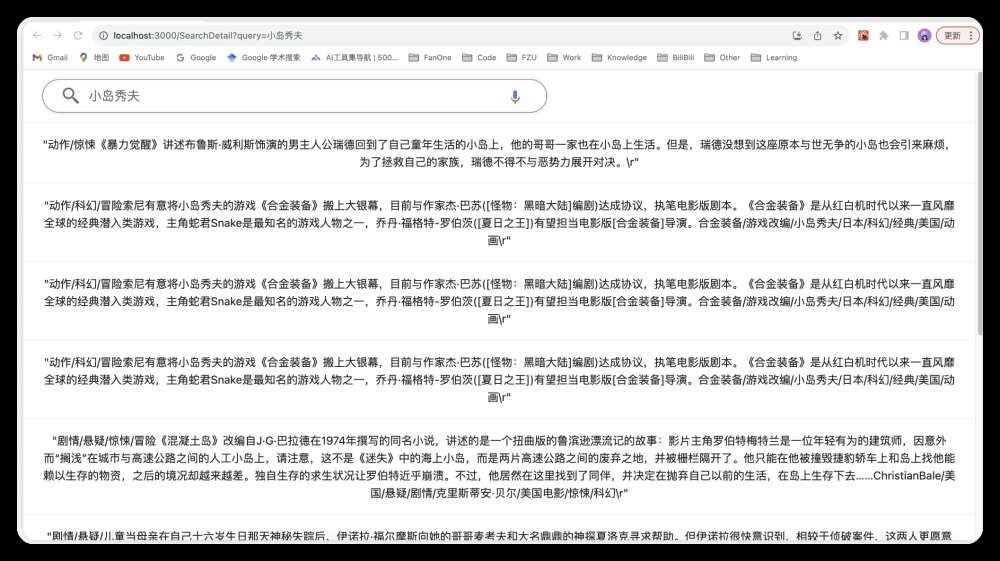
搜索页面
搜索结果页面
🌈 项目主要功能
1. 用户模块
- 登录注册
2. 收藏夹模块
- 创建/更新/删除/展示 收藏夹
- 将搜索结果的url进行收藏夹的创建/删除/展示
3. 索引平台
3.1 文本存储
正排库
目前存放在mysql中,但后续会放到OLAP,starrocks可以承受单表亿级数据毫秒级查询,像mysql这种OLTP到这个级别早就分库分表了,不然这张表或者这个库就废了,索引页也救不活…
倒排库
x.inverted 存储倒排索引文件
x.trie_tree 存储词典trie树
目前使用 mapreduce+kafka 集群 来构建倒排索引

- map任务将数据拆分以下形式
{
"token":"xxx",
"doc_id":1
}
- reduce任务将所有相同 token 的 doc_id 合并在一起
存储doc id使用roaring bitmap这种数据结构来存储,尽可能的压缩空间
在索引平台中,离线构建的倒排索引会进行合并操作
- 每天产生的数据将存放同一个文件中. eg: 2023-10-03.inverted
- 每周的周日会将这一周的数据都合并到当月中. eg: 2023-10.inverted
- 每月的最后一天会把该月合并到该季度中. eg: 2023-Autumn.inverted
向量库
向量库采用milvus来存储向量信息,这部分逻辑是放在python的,因为文本向量化基本都是python垄断
4. 搜索模块
4.1 文本搜索
- 倒排召回
因为 boltdb 是kv数据库,所以直接获取所有的对应的query对应的 doc id 即可,这部分使用的是golang实现的,并提供了grpc接口。
- 向量召回
query向量化,并从milvus中查询获取,这部分使用的python实现,并提供了grpc接口。
- 融合
将倒排和向量两个纬度的索引信息召回进行融合。
- 排序
bm25进行排序
4.2 图片搜索(待定…)
- resnet50 模型召回

✨ 项目结构
1.tangseng 项目总体
tangseng/
├── app // 各个微服务
│ ├── favorite // 收藏夹
│ ├── gateway // 网关
│ ├── index_platform // 索引平台
│ ├── mapreduce // mapreduce 服务(已弃用)
│ ├── gateway // 网关
│ ├── search_engine // 搜索微服务(文本)
│ ├── search_vector // 向量搜索微服务(图片+向量)
│ └── user // 用户模块微服务
├── bin // 编译后的二进制文件模块
├── config // 配置文件
├── consts // 定义的常量
├── doc // 接口文档
├── idl // protoc文件
│ └── pb // 放置生成的pb文件
├── loading // 全局的loading,各个微服务都可以使用的工具
├── logs // 放置打印日志模块
├── pkg // 各种包
│ ├── bloom_filter // 布隆过滤器
│ ├── clone // 复制context,防止context cancel
│ ├── ctl // 用户信息相关
│ ├── discovery // etcd服务注册、keep-alive、获取服务信息等等
│ ├── fileutils // 文件操作相关
│ ├── es // es 模块
│ ├── jwt // jwt鉴权
│ ├── kfk // kafka 生产与消费
│ ├── logger // 日志
│ ├── mapreduce // mapreduce服务
│ ├── res // 统一response接口返回
│ ├── retry // 重试函数
│ ├── timeutil // 时间处理相关
│ ├── trie // 前缀树
│ ├── util // 各种工具、处理时间、处理字符串等等..
│ └── wrappers // 熔断
├── repository // 放置打印日志模块
│ ├── mysql // mysql 全局数据库
│ ├── redis // redis 全局数据库
│ └── vector // 向量数据库
└── types // 定义各种结构体
2.gateway 网关部分
gateway/
├── cmd // 启动入口
├── internal // 业务逻辑(不对外暴露)
│ ├── handler // 视图层
│ └── service // 服务层
│ └── pb // 放置生成的pb文件
├── logs // 放置打印日志模块
├── middleware // 中间件
├── routes // http 路由模块
└── rpc // rpc 调用
3.user && favorite 用户与收藏夹模块
user/
├── cmd // 启动入口
└── internal // 业务逻辑(不对外暴露)
├── service // 业务服务
└── repository // 持久层
└── db // db模块
├── dao // 对数据库进行操作
└── model // 定义数据库的模型
4. index platform索引平台
seach-engine/
├── analyzer // 分词器
├── cmd // 启动入口
├── consts // 放置常量
├── crawl // 分布式爬虫
├── input_data // csv文件(爬虫未实现)
├── respository // 存储信息
│ ├── spark // spark 存储,后续支持...
│ └── storage // boltdb 存储(后续迁到spark)
├── service // 服务
└── trie // 存放trie树
5.search-engine 搜索引擎模块
seach-engine/
├── analyzer // 分词器
├── cmd // 启动入口
├── data // 数据层
├── ranking // 排序器
├── respository // 存储信息
│ ├── spark // spark 存储,后续支持...
│ └── storage // boltdb 存储(后续迁到spark)
├── service // 服务
├── test // 测试文件
└── types // 定义的结构体
这里只是对tangseng的简单介绍而已~,具体可以查看github链接 tangseng搜索引擎文章来源:https://www.toymoban.com/news/detail-770759.html
另外lotusdblabs 社区也开源了一个 lotusearch 搜索引擎,有兴趣同学可以瞅瞅~文章来源地址https://www.toymoban.com/news/detail-770759.html
到了这里,关于【Go语言实战】(26) 分布式搜索引擎的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!