提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
基于语音识别(1)进行的完善,修改了60秒断触的问题,另外可以更加方便的调用,语音识别1的链接如下:
https://blog.csdn.net/m0_46657126/article/details/124531081
一、申请讯飞语音端口
1.点击链接进入讯飞平台主页面
https://www.xfyun.cn/
2.在页面注册自己的个人账户
ps:注册账户是完全免费的,因为我之前已经注册过一个了,这里就不重复介绍了,注册之后看个人情况进行个人认证,这个不影响之后的操作。
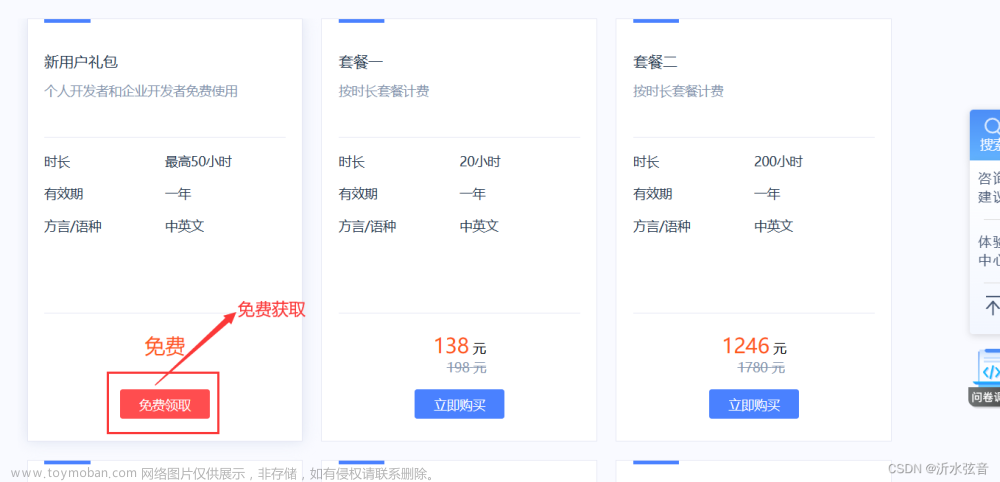
3.申请语音端口

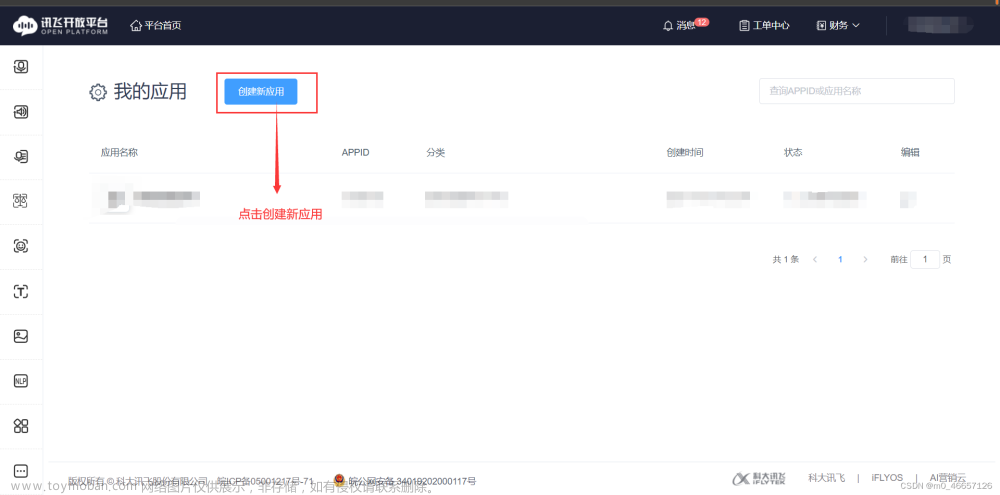
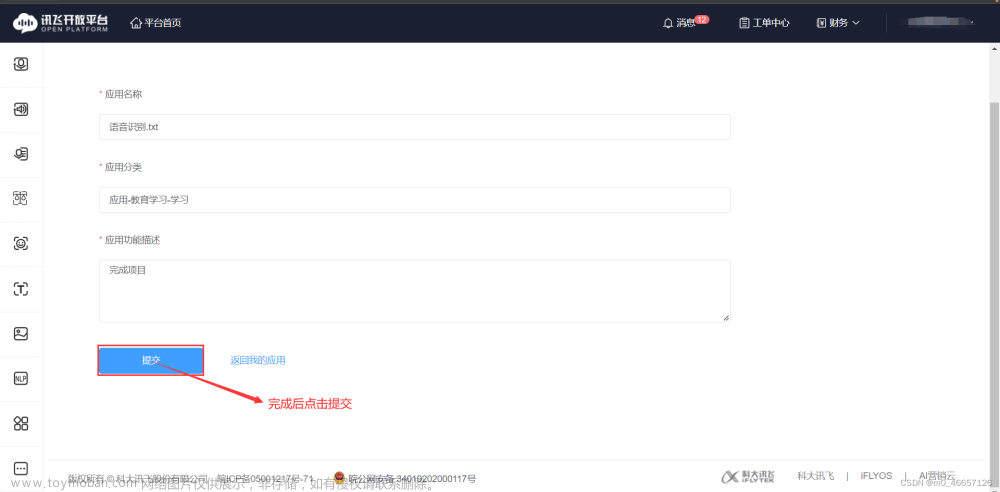
ps:申请内容大概像我这样写就行,名字重复的话换一个
4.查看自己的端口编码
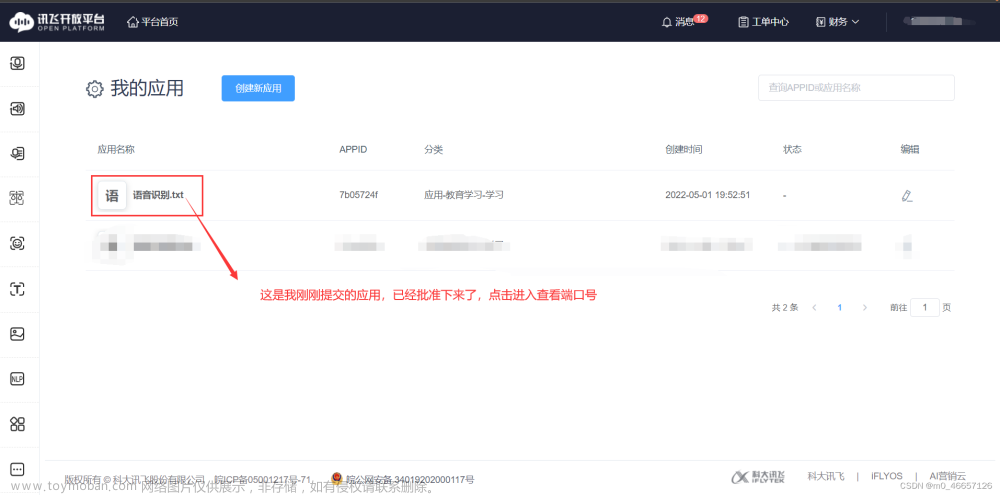
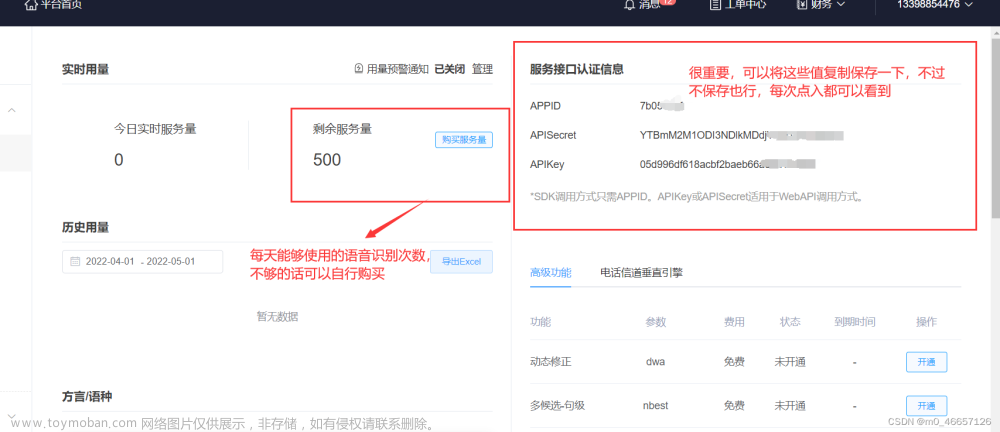
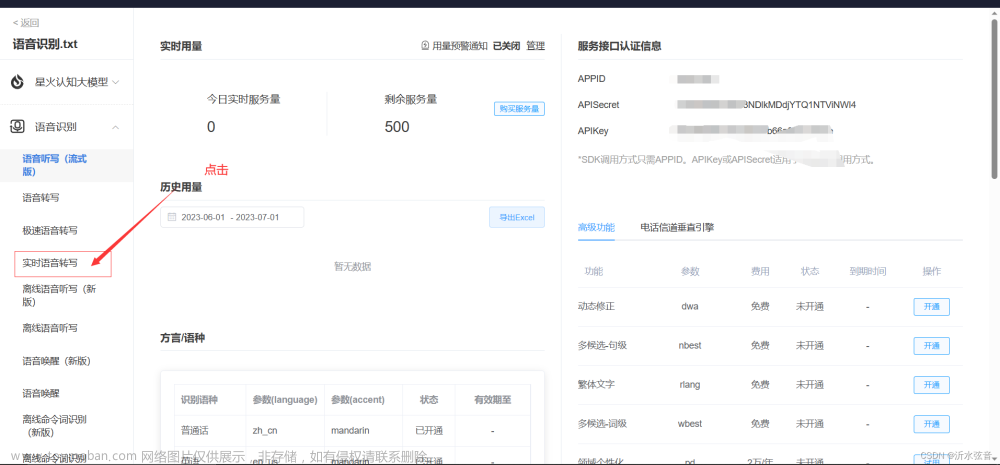
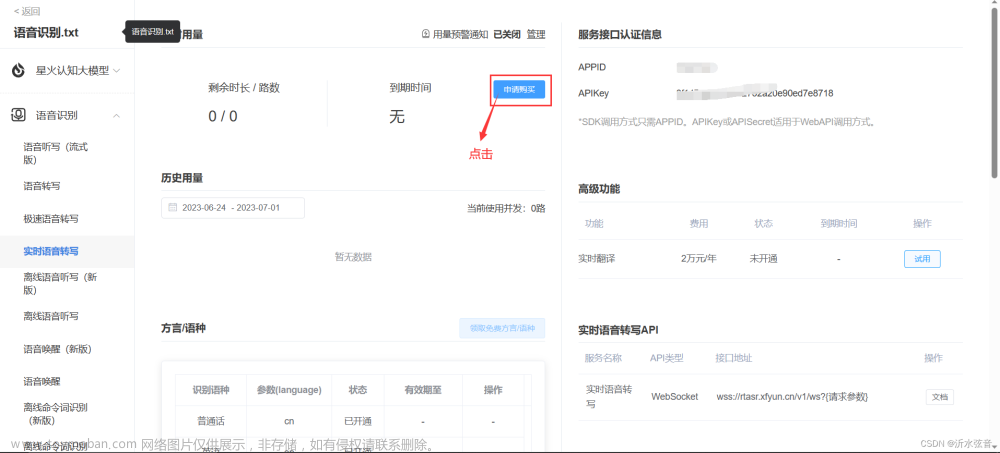

二、python代码讲解
1.代码如下(实例)
代码如下(示例):
# -*- encoding:utf-8 -*-
import hashlib
import hmac
import base64
from socket import *
import json, time, threading
from websocket import create_connection
import websocket
from urllib.parse import quote
import logging
import pyaudio
import re
# reload(sys)
# sys.setdefaultencoding("utf8")
class Client():
def __init__(self):
logging.basicConfig()
self.app_id = ""
self.api_key = ""
base_url = "ws://rtasr.xfyun.cn/v1/ws"
ts = str(int(time.time()))
tt = (self.app_id + ts).encode('utf-8')
md5 = hashlib.md5()
md5.update(tt)
baseString = md5.hexdigest()
baseString = bytes(baseString, encoding='utf-8')
apiKey = self.api_key.encode('utf-8')
signa = hmac.new(apiKey, baseString, hashlib.sha1).digest()
signa = base64.b64encode(signa)
signa = str(signa, 'utf-8')
self.end_tag = "{\"end\": true}"
self.ws = create_connection(base_url + "?appid=" + self.app_id + "&ts=" + ts + "&signa=" + quote(signa))
self.trecv = threading.Thread(target=self.recv)
self.trecv.start()
def send(self):
CHUNK = 300 # 定义数据流块
FORMAT = pyaudio.paInt16 # 16bit编码格式
CHANNELS = 1 # 单声道
RATE = 16000 # 16000采样频率
p = pyaudio.PyAudio()
# 创建音频流
stream = p.open(format=FORMAT, # 音频流wav格式
channels=CHANNELS, # 单声道
rate=RATE, # 采样率16000
input=True,
frames_per_buffer=CHUNK)
print("- - - - - - - Start Recording ...- - - - - - - ")
while True:
# file_object = stream.read(CHUNK)
index = 1
while True:
chunk = stream.read(1280)
if not chunk:
break
self.ws.send(chunk)
index += 1
time.sleep(0.04)
# self.ws.send(bytes(self.end_tag.encode('utf-8')))
# print("send end tag success")
def recv(self):
try:
while self.ws.connected:
result = str(self.ws.recv())
if len(result) == 0:
print("receive result end")
break
result_dict = json.loads(result)
# 解析结果
if result_dict["action"] == "started":
print("handshake success, result: " + result)
if result_dict["action"] == "result":
result = ''
result_1 = re.findall('"w":"(.*?)"', str(result_dict["data"]))
for i in result_1:
if i == '。' or i == '.。' or i == ' .。' or i == ' 。':
pass
else:
result += i
print("翻译结果:" + result)
# 写入文本文件
tep = open('tep.txt', 'w', encoding='utf-8')
tep.write(result)
tep.close()
# print("rtasr result: " + result_1)
if result_dict["action"] == "error":
print("rtasr error: " + result)
self.ws.close()
return
except websocket.WebSocketConnectionClosedException:
print("receive result end")
def close(self):
self.ws.close()
print("connection closed")
def runc():
client = Client()
client.send()
if __name__ == '__main__':
logging.basicConfig()
client = Client()
client.send()
2.代码需要修改的部分
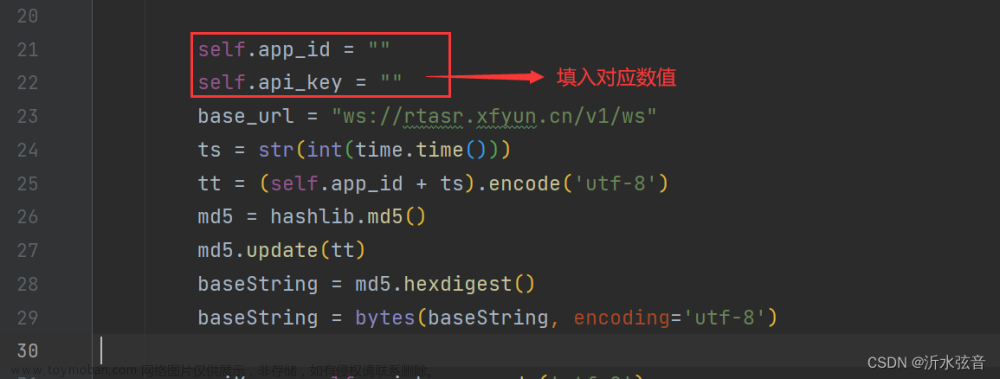
3.包的导入
Ps:因为没有新的Project Interpreter,所以不记得有什么包需要重新引入,唯一有印象的只有pyaudio了,所以这里就只提供了pyaudio的引入方法,其他的好像直接导入就可以了。
1)首先:下载安装 pyaudio 的 whl 文件
下载网址:https://www.lfd.uci.edu/~gohlke/pythonlibs/
2)该界面上输入ctrl+f,搜索pyaudio
3)下载
重点:一定要根据自己的版本进行下载!!!,每个人不一定是一样的。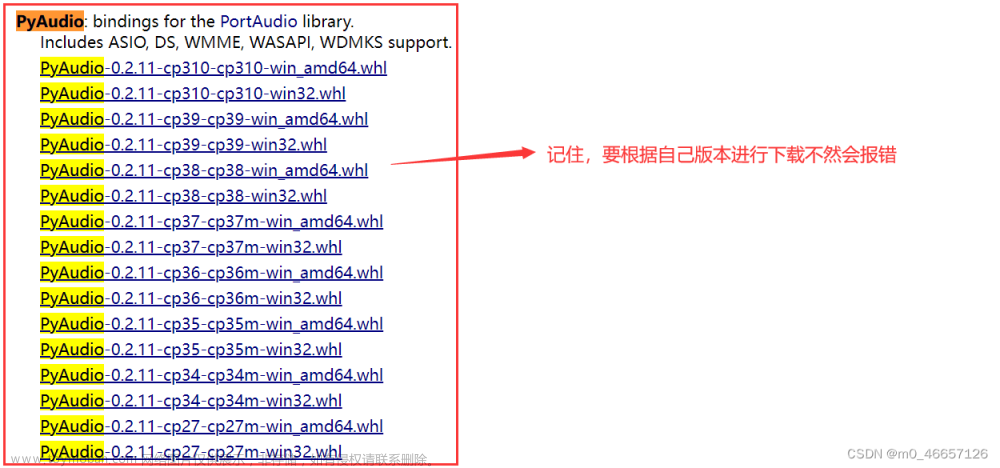
4)记录下载文件的安装路径,如果换位置,则记住新的位置
5)安装
键盘输入win+r,输入cmd打开终端模式
假设我的下载位置为D盘的杂项文件夹,那么可以先利用cd转到D盘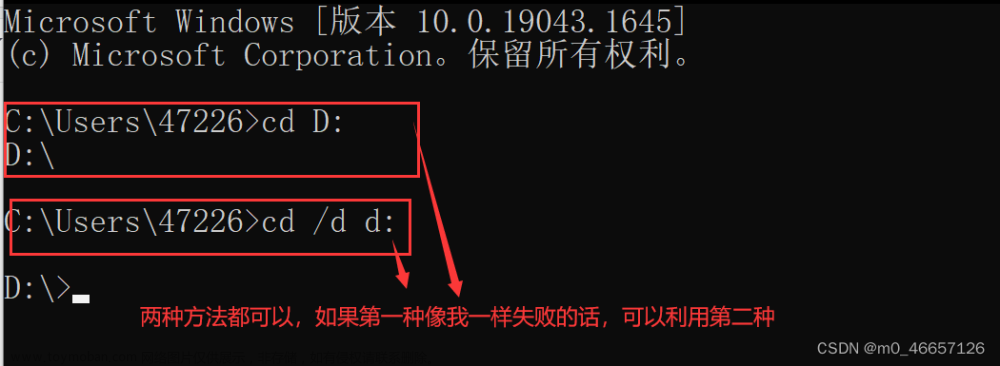
再转到杂项
进行安装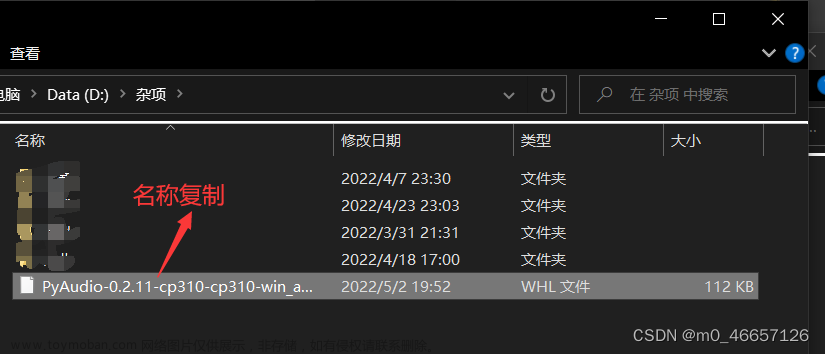
然后输入pip install 文件名称即可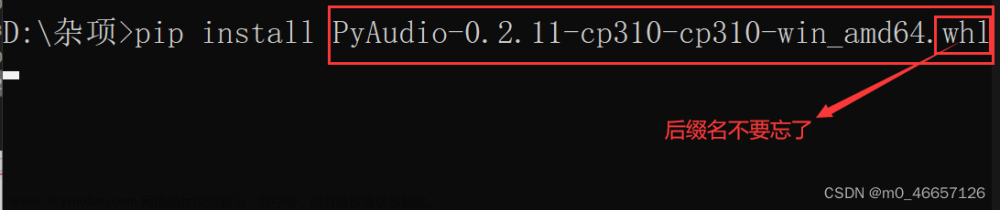
回车,安装结束
4.结果演示
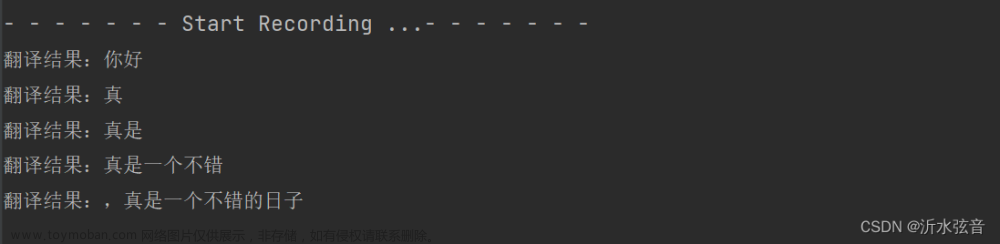 文章来源:https://www.toymoban.com/news/detail-771867.html
文章来源:https://www.toymoban.com/news/detail-771867.html
总结
以上主要是对第一篇语音识别的更新,因为很多小伙伴提出了出现的问题,依次对其进行了改进。文章来源地址https://www.toymoban.com/news/detail-771867.html
到了这里,关于语音识别(利用python将语音转化为文字)(升级版)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!