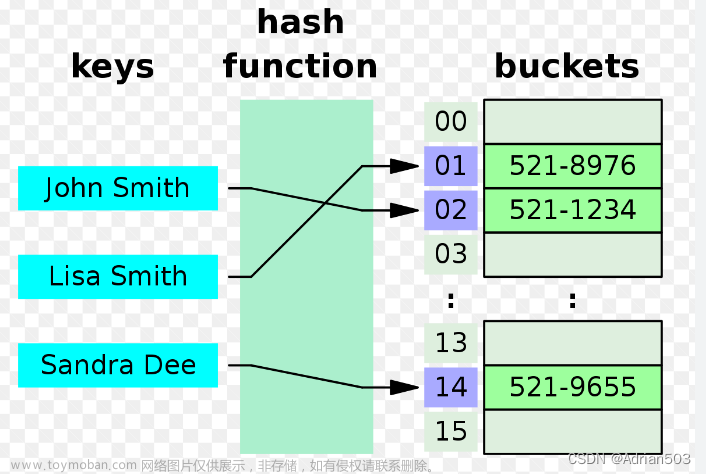
一、什么是哈希表
哈希表又叫散列表,他们两个是同一个东西,本文全文采用“散列表”的叫法。散列表的本质其实就是一个数组,他的作用就像使用数组时一样,输入下标可以得到对应元素,散列表可以实现输入一个关键字的时候得到这个关键字的地址信息。
下面是百科给出的解释:
散列表(Hash table,也叫哈希表),是根据键(key)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
二、散列表的查找
注意:该部分内容可能比较晦涩难懂,大家可以阅读完 2.3 部分后再回头看概念。
2.1.概念
在元素的存储位置和其关键字之间建立某种直接关系,按照这种关系直接由关键字找到相应的记录,这就是散列查找法的思想,它通过对元素的关键字值进行某种运算,直接求出元素的地址,即使用关键字到地址的直接转换方法,而不需要反复比较。因此散列查找法又叫杂凑法或散列法。
2.2.常用术语
散列函数和散列地址:在记录的存储位置 p 和其关键字 key 之间建立一个确定的对应关系H,使得p=H(key),称这个对应关系 H 为散列函数,p 为散列地址。
散列表:一个有限连续的地址空间,用以存储有散列函数计算得到的散列地址。通常散列表的存储空间是一个一维数组,散列地址是数组的下标。
冲突和同义词:对不同的关键字可能得到同一散列地址,即 key1≠key2,而H(key1)=H(key2),这种现象称为冲突。key1与key2互为同义词。
注意:在实际应用中,理想化的、不产生冲突的散列函数极少存在,这是因为散列表中关键字的取值集合通常远远大于表空间的地址集。
2.3.散列函数的构造方法
2.3.1考虑因素及遵循原则
构造散列函数的方法很多,一般来说要考虑以下因素,然后根据不同情况选择不同的构造方法:
(1)散列表的长度;
(2)关键字的长度;
(3)关键字的分布情况;
(4)计算散列函数所需的时间;
(5)记录的查找频率。
构造一个好的散列函数还应遵循以下两条原则:
(1)函数计算要简单,每一关键字只能有一个散列地址与之对应;
(2)函数的值域需在表长的范围内,计算出的散列地址的分布应该均匀,尽可能减少冲突。
2.3.2常见的构造方法
1.数字分析法:
提取关键字中取值较为均匀的数字为作为散列地址的方法。适用于事先知道所有关键字每一位数字的分布情况。
例如:对于一组关键字:
{92317602,92326875,92739628,92343634,92706816,92774628,92381262,92394220}
通过观察可知,从左到右第1、2、3位和第6位的关键字取值较为集中,不宜作为散列函数(哈希函数)。剩余的第4、5、7、8位取值较为分散,可以根据实际需要选取其中的若干位作为散列地址(哈希地址)。若选取最后两位作为散列地址,则散列地址的集合为{2,75,28,34,16,38,62,20}。
2.平方取中法:
提取关键字平方后的中间几位或者其组合作为散列地址的方法。适用于不能事先了解关键字的所有情况,或难于直接从关键字中找到取值较分散的几位的情况。
| 关键字 | 关键字的平方 | 散列地址 |
| 09040101 | 081723426090201 | 426 |
| 09040202 | 081725252200804 | 252 |
| 24090403 | 580347516702409 | 516 |
| 25090404 | 629528372883216 | 372 |
3.折叠法:
将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为散列地址,这种方法成为折叠法。根据数位叠加的方式,可以把折叠法分为移位叠加和边界叠加两种。
移位叠加是将分割后每一部分的最低位对齐,然后相加;
边界叠加是将两个相邻的部分沿边界来回折叠,然后对齐相加。
适用于散列地址的位数较少,而关键字的位数较多,且难于直接从关键字中找到取值较分散的几位。

4.除留余数法:(最常用!!!)
假设散列表的表长为 m ,选择一个不大于 m 的数 p ,用 p 去除关键字,除后所的余数为散列地址,即:H(key)=key%p 。
这个方法的关键是选取适当的 p ,一般情况下,选取 p 为小于表长的最大质数。例如,表长 m=100,可取 p=97 。
除留余数法计算简单,适用范围非常广,是最常用的构造散列函数的方法。它不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模,这样能够保证散列地址一定落在散列表的地址空间中。
代码如下:(实现功能为,输入一组数组元素作为初始数据,再输入想要找到下标的元素;输出该元素的下标)
#include<bits/stdc++.h>
using namespace std;
const int m=20; //length of hash table
const int NULLKEY=-12345; //null flag
bool isPrime(int n) {
if(n==1) return false;
for(int i=2; i<=sqrt(n); i++) {
if(n%i==0) return false;
}
return true;
}
int getPrime(int n) { //Get largest prime less than n
for(int i=n-1; i>=2; i--) {
if(isPrime(i)) {
return i;
break;
}
}
}
int H(int key,int p) { //hash function
int ans;
ans=abs(key)%p;
return ans;
}
int hashSearch(vector<int> &a,int key) {
int p=getPrime(m);
int d0=H(key,p);
int di;
if(a[d0]==NULLKEY) return -1;
else if(a[d0]==key) return d0;
else {
for(int i=1; i<m; ++i) {
di=(d0+i)%m; //Linear detection method
if(a[di]==NULLKEY) return -1;
else if(a[di]==key) return di;
}
return -1;
}
}
int main() {
vector<int> v;
int n; //n<m
cin>>n;
for(int i=0; i<n; i++) {
int x;
cin>>x;
v.push_back(x);
}
int key;
cin>>key;
int t=hashSearch(v,key);
if(t==-1) cout<<"Not found"<<endl;
else cout<<"Index is "<<t<<endl;
return 0;
}样例输入输出:
输入:
16
-7 16 12 68 27 55 -19 20 85 79 10 11 10 -3 -1 7
12
输出:
Index is 2
由于已经分析过该方法的逻辑,所以代码不再做分析,细读之后应该比较容易理解。
三、处理冲突
3.1概念
选择一个“好”的散列函数可以在一定程度上减少冲突,但在实际应用中,很难完全避免发生冲突,所以选择一个有效的处理冲突的方法是散列法的另一个关键。创建散列表和查找散列表都会遇到冲突,两种情况下处理冲突的方法一致。
处理冲突的方法与散列表本身的组织形式有关。按组织形式的不同,处理冲突的方法通常分为两大类:开放地址法和链地址法。
3.2处理方法
3.2.1开放地址法
开放地址法的基本思想是把记录都存储在散列表数组中,当某一记录的关键字key的初始散列地址 H0=H(key) 发生冲突时,以 H0 为基础,采取合适方法计算得到另一个地址 H1,如果 H1 仍然发生冲突,以 H1 为基础再求下一个地址 H2 ,以此类推,直至 不发生冲突为止,则 为该记录在表中的散列地址。通常把寻找“下一个”空位的过程成为探测。
开放地址法咋咨询找下一个空的散列地址是,原来数组空间对所有的元素都是开放的,所以称为开放地址法。
开放地址法的分类:

其中,我们较为常用的是线性探测法的数学递推公式。我们来看个例题:

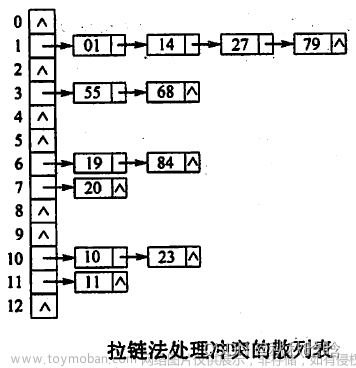
3.2.2链地址法
链地址法的基本思想是把所有具有相同散列地址的记录放在同一个单链表中,称之为同义词链表。有 m 个散列地址就有 m 个单链表。
 文章来源:https://www.toymoban.com/news/detail-773015.html
文章来源:https://www.toymoban.com/news/detail-773015.html
以上就是我对散列表(哈希表)的理解,一般来讲掌握除留余数法的代码并可以用于编程,会使用另外三种方法解决选择填空题就大致ok了 ,由于我使用这部分知识也不多,如果有错误或需要补充的,还请批评指正。文章来源地址https://www.toymoban.com/news/detail-773015.html
到了这里,关于数据结构算法设计——哈希表(散列表)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!