前面介绍了 PostgreSQL 数据类型和运算符、常用函数、锁操作、执行计划、视图与触发器相关的知识点,今天我将详细的为大家介绍 PostgreSQL 存储过程相关知识,希望大家能够从中收获多多!如有帮助,请点在看、转发支持一波!!!
工作中可能会存在业务比较复杂,重复性工作比较多,需要批量处理数据的情况,此时使用存储过程会方便很多,存储过程的执行效率也会快很多,能帮助我们节省很多代码和时间。
并且,将需要的sql写成存储过程并设置成定时任务,那样在任意时刻,需要执行任意次数都可以根据你的设定执行,哪怕你不在工位上,减少你的工作量,能让你更愉快的摸鱼(不是)。
PostgreSQL 概述
在 PostgreSQL 中,除了标准 SQL 语句之外,通过创建复杂的过程和函数来满足程序需要,我们称为存储过程和自定义函数(User-Defined Function)。它有助于您执行通常在数据库中的单个函数中进行多次查询和往返操作的操作。
PL/pgSQL 简单易学,无论是否具有编程基础都能够很快学会。PL/pgSQL 存储过程,它和 Oracle PL/SQL 非常类似,是 PostgreSQL默认支持的存储过程,下面针对优缺点给大家做了简要分析。
优点
-
减少应用和数据库之间的网络传输。所有的 SQL 语句都存储在数据库服务器中,应用程序只需要发送函数调用并获取除了结果,避免了发送多个 SQL 语句并等待结果。
-
提高应用的性能。因为自定义函数和存储过程进行了预编译并存储在数据库服务器中。
-
可重用性。存储过程和函数的功能可以被多个应用同时使用。
-
作为脚本使用,如产品的 liquibase 中, 清理或修复数据将非常好用。
缺点
-
导致软件开发缓慢。因为存储过程需要单独学习,而且很多开发人员并不具备这种技能。
-
不易进行版本管理和代码调试。
-
不同数据库管理系统之间无法移植,语法存在较大的差异。
-
更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
存储过程基本结构
定义一个函数
CREATE [ OR REPLACE ] FUNCTION
name ( [ [ argmode ] [ argname ] argtype [ { DEFAULT | = } default_expr ] [, ...] ] )
[ RETURNS rettype
| RETURNS TABLE ( column_name column_type [, ...] ) ]
{ LANGUAGE lang_name
| TRANSFORM { FOR TYPE type_name } [, ... ]
| WINDOW
| IMMUTABLE | STABLE | VOLATILE | [ NOT ] LEAKPROOF
| CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT | STRICT
| [ EXTERNAL ] SECURITY INVOKER | [ EXTERNAL ] SECURITY DEFINER
| PARALLEL { UNSAFE | RESTRICTED | SAFE }
| COST execution_cost
| ROWS result_rows
| SUPPORT support_function
| SET configuration_parameter { TO value | = value | FROM CURRENT }
| AS 'definition'
| AS 'obj_file', 'link_symbol'
} ...
由官方文档得到的定义一个函数的语法,当然现实中不需要所有的要素都要定义到。现在就常用的要素做出解释。
-
CREATE FUNCTION定义一个新函数。CREATE OR REPLACE FUNCTION将创建一个新函数或者替换一个现有的函数
-
name:表示要创建的函数名
-
argmode:一个参数的模式:IN、OUT、INOUT或者VARIADIC。如果省略,默认为IN。只有OUT参数能跟在一个VARIADIC参数后面。还有,OUT和INOUT参数不能和RETURNS TABLE符号一起使用。
-
argname:一个参数的名称
-
argtype:该函数参数的数据类型
-
default_expr:如果参数没有被指定值时要用作默认值的表达式
-
rettype:返回的数据类型,如果该函数不会返回一个值,可以指定返回类型为void。(后面详细讲)
-
column_name:RETURNS TABLE语法中一个输出列的名称
-
culumn_type:RETURNS TABLE语法中的输出列的数据类型
注意:定义函数的时候,参数可以是空,但是哪怕不修改函数体只修改参数,它会得到一个新的函数。更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
PL/pgSQL 的结构
[ <<label>> ]
[ DECLARE
declarations ]
BEGIN
statements
END [ label ];
PL/pgSQL是一种块结构的语言。一个函数体的完整文本必须是一个块。存储过程的语法如上所示。
-
在一个块中的每一个声明和每一个语句都由一个分号终止。
-
所有的关键词都是大小写无关的。除非被双引号引用,标识符会被隐式地转换为小写形式,就像它们在普通 SQL 命令中。
-
PL/pgSQL代码中的注释和普通 SQL 中的一样。一个双连字符(–)开始一段注释,它延伸到该行的末尾。一个/* 开始一段块注释,它会延伸到匹配*/出现的位置。块注释可以嵌套。
赋值语法
声明变量赋值
具体可看官方文档
name [ CONSTANT ] type [ COLLATE collation_name ] [ NOT NULL ] [ { DEFAULT | := | = } expression ];
在自定义函数中声明一个变量,并给这个变量赋值的时候可以用这个方法。示例如下:
-- 1
declare a integer default 32;
-- 2
declare a integer :=32;
-- 3
declare a integer;
a :=32;
这三种方法都能将声明一个变量a,并且将32赋值给a。若不给a赋值,就是方法三中没有a:=32;也不会报错,就是变量a初始化为sql空值。
-
constant:若是增加constant,则表示该变量的值无法修改
-
collate:给该变量指定一个排序规则
-
not null:如果给改变量赋值为空值会报错
例如,以下方式就会报错。
-- 报错1
-- 加了constant,已经无法修改a的值了。
declare a constant integer default 32;
a :=1;

-- 报错2
-- 在声明变量的时候选择了not null,就应该在声明时赋值,否则哪怕后面赋值还是会报错
declare a integer not null;
a :=32;

动态赋值
具体可查看官方文档
方式一:into子句
SELECT select_expressions INTO [STRICT] target FROM ...;
INSERT ... RETURNING expressions INTO [STRICT] target;
UPDATE ... RETURNING expressions INTO [STRICT] target;
DELETE ... RETURNING expressions INTO [STRICT] target;
举个例子,如下:
-- 这就表示把test表中的id字段的值赋值给a
-- 其中 select id from test就是基础sql命令从test表中查询id的值
-- 通过 into a 将查询得到的值赋值给a
select id into a from test;
方式二:动态命令
EXECUTE command-string [ INTO [STRICT] target ] [ USING expression [, ... ] ];
举个例子,如下:
-- 和上面一样,把id的值查询出来赋值给a
execute 'select id from test' into a;
更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
返回值类型
官方文档:

returns返回类型可以是一种基本类型、组合类型或者域类型,也可以引用一个表列的类型。
当有OUT或者INOUT参数时,可以省略RETURNS子句。如果存在,该子句必须和输出参数所表示的结果类型一致:如果有多个输出参数,则为RECORD,否则与单个输出参数的类型相同。
返回void
如果该函数不会返回一个值,可以指定返回类型为void。如果选择返回returns void,那函数体最后就不用return了。
CREATE OR REPLACE FUNCTION "public"."func1"()
RETURNS "pg_catalog"."void" AS $BODY$ -- returns void,在保存的时候自动会变成"pg_catalog"."void"
BEGIN
-- 建表语句
create table a(
id int4,
name varchar(50)
);
END
$BODY$
LANGUAGE plpgsql VOLATILE
COST 100


返回基本类型
返回的结果是类似int4,float,text等这些基本数据类型都可以。示例:
CREATE OR REPLACE FUNCTION "public"."func1"()
RETURNS "pg_catalog"."text" AS $BODY$
declare val text;
BEGIN
insert into a values (1,'小明') returning name into val;
return val;
END
$BODY$
LANGUAGE plpgsql VOLATILE
COST 100

这个函数的结果会返回val的值,如下图:

并且在表a中会插入一条数据,如下图。

这里敲黑板!!! 这里通过into子句赋值给变量,返回的是结果的第一行或者null(查询返回零行),除非使用order by进行排序,否则第一行是不明确的,第一行之后所有的结果都会被丢弃。
如果加了strict选项,那么查询结果必须是恰好一行,否则就会报错。
举个例子,现在在a表中插入数据,表a数据如下。

然后从表中查询出name值赋值val。
CREATE OR REPLACE FUNCTION "public"."func1"()
RETURNS "pg_catalog"."text" AS $BODY$
declare val text;
BEGIN
select name into val from a ;
return val;
END
$BODY$
LANGUAGE plpgsql VOLATILE
COST 100
得到的结果如下显示。返回一行数据,并且这个第一行的排序并不是表的第一行数据。

若是添加strict选项,结果返回的是多条数据就会报错,如下显示。


如果返回的结果刚好是一行数据的,则添加strict选项就可以显示最终结果。

正常显示结果并且返回。结果如下:

返回多条数据
到目前为止,现在返回的结果要不是返回空要不就是返回一个记录,若是想要多条数据该怎么处理呢?
-
返回setof sometype
-
SETOF修饰符表示该函数将返回一个项的集合而不是一个单一项。当被返回setof sometype时,函数最后一个查询执行完后输出的每一行都会被作为结果集的一个元素返回。
-
sometype可以是某一张已经存在的表,也可以是record。也可以是某个字段类型。
-
上面那个例子,若是想要返回多条记录,就可以修改如下。
CREATE OR REPLACE FUNCTION "public"."func1"()
RETURNS SETOF "public"."a" AS $BODY$
BEGIN
return query select a.id,a.name from a limit 2;
return;
END
$BODY$
LANGUAGE plpgsql STABLE
COST 100
ROWS 1000
得到的结果如下图。

期中return query还可以使用return next。具体语法是:
RETURN NEXT expression;
RETURN QUERY query;
RETURN QUERY EXECUTE command-string [ USING expression [, ... ] ];
详细情况可以看查看官方文档。更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
控制结构
postgresql中可以使用的控制结构,有条件结构和循环结构。
条件结构
官方文档:
IF语句:
-
IF … THEN … END IF
-
IF … THEN … ELSE … END IF
-
IF … THEN … ELSIF … THEN … ELSE … END IF
具体语法官方文档链接中可查看,现在举个小例子看一个
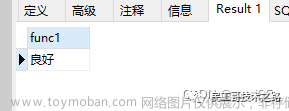
CREATE OR REPLACE FUNCTION "public"."func1"("a" int4)
RETURNS "pg_catalog"."text" AS $BODY$
declare rel varchar;
BEGIN
IF a>=90 THEN
rel:='优秀';
elsif a>=80 then
rel := '良好';
elsif a>=60 then
rel := '及格';
ELSE
rel :='不及格';
END IF;
return rel;
END
$BODY$
LANGUAGE plpgsql STABLE
COST 100

CASE语句:
-
CASE … WHEN … THEN … ELSE … END CASE
-
CASE WHEN … THEN … ELSE … END CASE
同理上面的函数可以改成case when
CREATE OR REPLACE FUNCTION "public"."func1"("a" int4)
RETURNS "pg_catalog"."text" AS $BODY$
declare rel varchar;
BEGIN
case when a>=90 THEN
rel:='优秀';
when a>=80 then
rel := '良好';
when a>=60 then
rel := '及格';
ELSE
rel :='不及格';
END case;
return rel;
END
$BODY$
LANGUAGE plpgsql STABLE
COST 100
循环结构
官方文档:
循环结构有loop,exit,continue,while,for和foreach语句
-
loop
[ <<label>> ]
LOOP
statements
END LOOP [ label ];
loop定义的是一个无条件循环,会无限重复直到被exit或return语句终止,所以
-
exit
EXIT [ label ] [ WHEN boolean-expression ];
指定when,当boolean-expression为真时会退出循环。配合loop给个例子。
LOOP
raise notice 'a is %',a;
a :=a-1;
IF a<=rel THEN
EXIT;
END IF;
END LOOP;
-- 等同于
LOOP
raise notice 'a is %',a;
a :=a-1;
EXIT when a<=rel; -- 这个相当于前面整个if判断
END LOOP;

执行函数,传入参数为5,则显示的结果如下:

-
continue
CONTINUE [ label ] [ WHEN boolean-expression ];
-
while
[ <<label>> ]
WHILE boolean-expression LOOP
statements
END LOOP [ label ];
当boolean-expression为真的时候,这个循环会执行。举例:
CREATE OR REPLACE FUNCTION "public"."loops"("a" int4)
RETURNS "pg_catalog"."void" AS $BODY$
declare rel integer default 0;
BEGIN
WHILE a>0 LOOP
raise info 'a= %',a;
rel := rel+a;
a:=a-1;
END LOOP;
raise info 'rel = %',rel;
END
$BODY$
LANGUAGE plpgsql VOLATILE
COST 100

执行函数输入参数5,得到信息如下:

-
for
整数范围循环。
[ <<label>> ]
FOR name IN [ REVERSE ] expression .. expression [ BY expression ] LOOP
statements
END LOOP [ label ];
for循环会创建一个整数返回进行迭代。此时下界临界值小于上界临界值,若是制定reverse,则上界临界值写在前,下界临界值写在后,默认步长为1,若是正向迭代,每次迭代数值都是加1,若是反向迭代都是减1。通过by,可以指定步长。
例如:
FOR i IN 1..10 LOOP
-- 我在循环中将取值 1,2,3,4,5,6,7,8,9,10
END LOOP;
FOR i IN REVERSE 10..1 LOOP
-- 我在循环中将取值 10,9,8,7,6,5,4,3,2,1
END LOOP;
FOR i IN REVERSE 10..1 BY 2 LOOP
-- 我在循环中将取值 10,8,6,4,2
END LOOP;
查询结果循环
[ <<label>> ]
FOR target IN query LOOP
statements
END LOOP [ label ];
target是一个记录变量、行变量或者逗号分隔的标量变量列表。target被连续不断被赋予来自query的每一行,并且循环体将为每一行执行一次。下面是一个例子:
CREATE OR REPLACE FUNCTION "public"."loops"()
RETURNS "pg_catalog"."void" AS $BODY$
declare rel record;
BEGIN
FOR rel IN select id,name from a LOOP
-- quote_ident()的作用是为字符串加上双引号
raise notice 'a表中的用户信息为id: %,name: %',rel.id,quote_ident(rel.name);
END LOOP;
END
$BODY$
LANGUAGE plpgsql VOLATILE
COST 100
结果显示如下:

for-in-execute语句在行上迭代的另一种方式:
[ <<label>> ]
FOR target IN EXECUTE text_expression [ USING expression [, ... ] ] LOOP
statements
END LOOP [ label ]
这个例子类似前面的形式,只不过源查询被指定为一个字符串表达式,在每次进入FOR循环时都会计算它并且重新规划。更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
在使用EXECUTE时,可以通过USING将参数值插入到动态命令中。
-
foreach
FOREACH循环很像一个FOR循环,但不是通过一个 SQL 查询返回的行进行迭代,它通过一个数组值的元素来迭代。
[ <<label>> ]
FOREACH target [ SLICE number ] IN ARRAY expression LOOP
statements
END LOOP [ label ];
具体例子不再给出,看看官方文档中的例子。
CREATE FUNCTION sum(int[]) RETURNS int8 AS $$
DECLARE
s int8 := 0;
x int;
BEGIN
FOREACH x IN ARRAY $1
LOOP
s := s + x;
END LOOP;
RETURN s;
END;
$$ LANGUAGE plpgsql;
提示信息
官方文档:
使用raise语句报告消息以及抛出错误,上面给的示例中已经有部分给出,语法是。
RAISE [ level ] 'format' [, expression [, ... ]] [ USING option = expression [, ... ] ];
RAISE [ level ] condition_name [ USING option = expression [, ... ] ];
RAISE [ level ] SQLSTATE 'sqlstate' [ USING option = expression [, ... ] ];
RAISE [ level ] USING option = expression [, ... ];
RAISE ;
level选项指定了错误的严重性。允许的级别有DEBUG、LOG、INFO、NOTICE, WARNING以及EXCEPTION,默认级别是EXCEPTION。
raise log ‘这是日志消息’; – 输出在日志文件中
raise inof ‘这是一个信息’; – 以下信息打印在控制台
raise notice ‘这个是提示消息’;
raise notice warning ‘这是个警告’;
raise exception ‘这个异常消息’;
调用存储过程
当存储过程编译出来后,我们该如何执行或者调用存储过程呢?语法如下。
select function_name();
select * from function_name();
select * from function_name where 筛选条件; -- 当返回的结果为多条数据的结果集的时候
select * from function_name() as tablename(column name,column type[,...]) ; --动态返回结果集
游标
PL/pgSQL 游标允许我们封装一个查询,然后每次处理结果集中的一条记录。游标可以将大结果集拆分成许多小的记录,避免内存溢出;另外,我们可以定义一个返回游标引用的函数,然后调用程序可以基于这个引用处理返回的结果集。
使用游标的步骤大体如下:
-
声明游标变量;
-
打开游标;
-
从游标中获取结果;
-
判断是否存在更多结果。如果存在,执行第 3 步;否则,执行第 5 步;
-
关闭游标。
我们直接通过一个示例演示使用游标的过程:
DO $$
DECLARE
rec_emp RECORD;
cur_emp CURSOR(p_deptid INTEGER) FOR
SELECT first_name, last_name, hire_date
FROM employees
WHERE department_id = p_deptid;
BEGIN
-- 打开游标
OPEN cur_emp(60);
LOOP
-- 获取游标中的记录
FETCH cur_emp INTO rec_emp;
-- 没有找到更多数据时退出循环
EXIT WHEN NOT FOUND;
RAISE NOTICE '%,% hired at:%' , rec_emp.first_name, rec_emp.last_name, rec_emp.hire_date;
END LOOP;
-- Close the cursor
CLOSE cur_emp;
END $$;
NOTICE: Alexander,Hunold hired at:2006-01-03
NOTICE: Bruce,Ernst hired at:2007-05-21
NOTICE: David,Austin hired at:2005-06-25
NOTICE: Valli,Pataballa hired at:2006-02-05
NOTICE: Diana,Lorentz hired at:2007-02-07
首先,声明了一个游标 cur_emp,并且绑定了一个查询语句,通过一个参数 p_deptid 获取指定部门的员工;然后使用 OPEN 打开游标;接着在循环中使用 FETCH 语句获取游标中的记录,如果没有找到更多数据退出循环语句;变量 rec_emp 用于存储游标中的记录;最后使用 CLOSE 语句关闭游标,释放资源。
游标是 PL/pgSQL 中的一个强大的数据处理功能,更多的使用方法可以参考官方文档。
事务管理
在存储过程内部,可以使用 COMMIT 或者 ROLLBACK 语句提交或者回滚事务。例如:
create table test(a int);
CREATE PROCEDURE transaction_test()
LANGUAGE plpgsql
AS $$
BEGIN
FOR i IN 0..9 LOOP
INSERT INTO test (a) VALUES (i);
IF i % 2 = 0 THEN
COMMIT;
ELSE
ROLLBACK;
END IF;
END LOOP;
END
$$;
CALL transaction_test();
select * from test;
a|
-|
0|
2|
4|
6|
8|
只有偶数才会被最终提交。更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
案例
以上就是存储过程的基本语法,接下来再给几个具体实例巩固一下。
案例一:无查询结果时,不用select,用perform。
CREATE OR REPLACE FUNCTION "public"."fun_etc"()
RETURNS "pg_catalog"."void" AS $BODY$
BEGIN
perform current_date;
END
$BODY$
LANGUAGE plpgsql VOLATILE
COST 100

案例二:for查询结果循环,声明语法拷贝类型(拷贝一个行变量)
拷贝行类型,语法声明:v_value table_name%ROWTYPE 。若是拷贝一个已有的列数据类型,语法:v_value variable%TYPE,类似declare b a.name%TYPE。
CREATE OR REPLACE FUNCTION "public"."fun_etc"()
RETURNS "pg_catalog"."text" AS $BODY$
declare b a%rowtype;
BEGIN
for b in select id,name from a loop
raise info 'b的值=%',b;
end loop;
return b.id||'---'||b.name;
END
$BODY$
LANGUAGE plpgsql VOLATILE
COST 100

信息结果:

return返回结果:return返回只会返回执行的最后一个结果。

案例三:当sql中的语句有变量的时候,可以用||拼接,最后execute执行。
CREATE OR REPLACE FUNCTION "public"."fun_etc"()
RETURNS "pg_catalog"."void" AS $BODY$
declare ifexists integer;
declare sqltext text;
declare b record;
BEGIN
-- 判断表是否存在,存在值=1,不存在值=0
sqltext:='
select count(1) from pg_class where relname=''a_'||to_char(CURRENT_DATE,'yyyy_mm_dd')||'''';
execute sqltext into ifexists;
-- 判断表是否存在,不存在则建表
IF ifexists=0 then
-- 建立一张新表
sqltext:='
create table "a_'||to_char(CURRENT_DATE,'yyyy_mm_dd')||'"
(
create_time date,
id int4,
name varchar(50)
);';
execute sqltext;
END IF;
-- 从表a中查询数据插入这表中
sqltext :='
insert into a_'||to_char(CURRENT_DATE,'yyyy_mm_dd')||'
select CURRENT_DATE,id,name from a
';
execute sqltext;
-- 查询显示数据
sqltext:= 'select create_time,id,name from a_'||to_char(CURRENT_DATE,'yyyy_mm_dd')||';';
for b in execute sqltext loop
raise info '%',b;
end loop;
return ;
END
$BODY$
LANGUAGE plpgsql VOLATILE
COST 100



案例四:为了使函数更加通用,以解决动态返回数据集的问题,将表名作为参数传进去。
CREATE OR REPLACE FUNCTION "public"."fun_etc"("name" varchar)
RETURNS SETOF "pg_catalog"."record" AS $BODY$
declare b record;
BEGIN
for b in execute 'select * from '||name loop
return next b;
end loop;
return ;
END
$BODY$
LANGUAGE plpgsql VOLATILE
COST 100
ROWS 1000
select * from fun_etc('a') as a(id int,name varchar(50));
结果显示:
 文章来源:https://www.toymoban.com/news/detail-774353.html
文章来源:https://www.toymoban.com/news/detail-774353.html
select * from fun_etc('a_2022_12_21') as a(create_time date,id int,name varchar(50));
结果显示:
其他需要注意的是,我这边都是在一个函数上修改,若是参数都一样的话,他是会在原函数上修改的,所以你们别这样啊,否则都白写了。文章来源地址https://www.toymoban.com/news/detail-774353.html
到了这里,关于进阶数据库系列(十一):PostgreSQL 存储过程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!