文章信息:

发表于:Pattern Recognition(CCF A类)
原文链接:https://www.sciencedirect.com/science/article/pii/S0031320321003940
源代码:https://github.com/ChangYunPeng/VideoAnomalyDetection
摘要
视频中的异常检测仍然是一项具有挑战性的任务,主要由于异常的定义模糊不清以及真实视频数据中视觉场景的复杂性。
与以往利用重建或预测作为辅助任务来学习时间规律的方法不同,本研究探索了一种新颖的卷积自编码器架构,该架构能够分离时空表示,以分别捕捉空间和时间信息,因为异常事件通常在外观和/或运动行为方面与正常情况不同。具体而言,空间自编码器通过学习重构第一个个体帧(FIF)的输入来对外观特征空间中的正常性建模,而时间部分以前四个连续帧作为输入,并以RGB差异作为输出,以有效模拟光流的运动。外观和/或运动行为上的异常事件导致较大的重构误差。
为了提高对快速移动的异常值的检测性能,我们利用基于方差的注意力模块,并将其插入到运动自编码器中以突显移动较大的区域。
此外,我们提出了一种深度K均值聚类策略,强制空间和运动编码器提取紧凑的表示。对一些公开可用的数据集进行的广泛实验证明了我们的方法的有效性,达到了当前最先进的性能水平。
图1:我们的视频异常检测架构概述。我们将时空信息分解为两个子模块。空间自动编码器
E
a
E_a
Ea和
D
a
D_a
Da用于重建LIF,而时间自动编码器
E
m
E_m
Em和
D
m
D_m
Dm用于预测输入连续视频帧的FIF和LIF之间的RGB差。编码器和解码器都由三个ResNet块构成。具体来说,我们在所有块中用LeakyReLU替换ReLU层,对于解码器网络,我们用像素混洗层替换步长卷积层,以逐步提高空间分辨率。为了进一步约束这两个流,我们引入了一种深度K均值聚类策略来提取紧凑表示,表示为紫色区域。在训练阶段,我们根据空间编码器和运动编码器的级联表示与其对应的聚类中心之间的距离,使用深度K均值聚类方法对两个流进行优化。此外,我们开发了一个基于方差的注意力模块,该模块可以在运动自动编码器中自动为视频片段的运动部分分配重要性权重。(有关此图例中颜色参考的解释,读者可参考本文的网络版本。)
1.介绍
在这项工作中,我们将时空信息分解为两个子模块,以在空间和时间特征空间中同时学习规律。给定连续的视频帧,空间自编码器在**第一个个体帧(FIF)**上运行,而运动自编码器在前四个视频帧上运行。
空间自编码器以单个帧外观的形式呈现有关视频中场景和对象的信息,而运动自编码器生成最后视频帧(LIF)和FIF之间的RGB差异,以获取运动信息。然后,我们将来自空间自编码器的重建结果与来自时态自编码器的RGB差异组合起来得到最终预测。
如图1所示,我们的两个子模块可以同时学习外观和运动规律。无论事件在外观特征空间还是运动特征空间中是否不规律,都将产生较大的重建误差。特别是,先前的研究[7,10,11]还利用了双流架构进行异常检测,其运动流主要通过生成或重建相应的光流来学习运动表示。然而,由于光流并非专门为异常检测而设计,因此光流可能不是学习规律的最佳选择[1,12]。此外,光流估计具有很高的计算成本。为了克服这些缺点,我们的运动自编码器以连续的视频帧作为输入,以它们的RGB差异作为输出来学习运动信息[13],其中RGB差异提示可以比光流更快地捕捉运动信息,并且运动自编码器的生成可以很容易地与空间自编码器的重建进行逐像素融合,以进一步帮助异常检测。值得注意的是,监控视频的大部分是静止的,异常值通常与快速移动具有很高的相关性,例如在地铁入口快速奔跑的行人和在人行道上快速驾驶的车辆。因此,我们利用基于方差的注意力模块来自动突出显示具有大运动的图像区域,并在运动编码器的每个块之后附加此注意力模块。此外,类似于先前的工作[14],该工作通过使用K均值算法[15]将正常训练样本聚类成k个簇,我们引入了一种深度K均值聚类策略来强制空间编码器和时态编码器获得更紧凑的数据表示。具体而言,我们使用K均值算法初始化我们的簇中心。
总的来说,我们的工作做出了以下贡献:
- 我们提出了一种新颖的自编码器架构,以分离时空表示,并在空间特征空间和运动特征空间中学习规律,从而检测视频中的异常事件。
- 我们设计了一个高效的运动自编码器,它以连续的视频帧作为输入,以RGB差异作为输出,以模仿光流的运动。所提出的方法比基于光流的运动表示学习方法更快,其平均运行时间为每秒32帧,使用一块GPU。
- 我们利用一个方差注意力模块,自动为视频剪辑的运动部分分配重要性权重,这有助于提高运动自编码器的性能。
- 我们探索了一种深度K均值聚类策略,以迫使自编码器网络生成紧凑的运动和外观描述符。由于簇仅在正常事件上进行训练,因此簇与异常表示之间的距离比正常模式之间的距离要大得多。重建误差和簇距离一起被用于评估异常情况。
2.相关工作
2.1. 基于自编码器的异常检测
由于现实数据的复杂性和有效标记数据的限制,异常事件检测任务通常在无监督设置下进行,其中训练集仅包含正常事件。大多数基于深度学习的方法使用自编码器[17–20]来提取特征表示,并采用基于重建或基于预测的方法来学习视频序列背后的正常性。基于重建的异常检测方法将给定的视频帧作为输入,通过提取高级特征表示学习以小的重建误差重构正常事件[1]。应用2D卷积自编码器来降低维度并学习时态规律[21–23]。使用相邻帧的时态一致性先验来训练自编码器网络[24]。引入了无标签监督,结合了约束学习和物理领域知识,共同解决了包括对象跟踪和行走人在内的三个计算机视觉任务[5]。使用编码器LSTM提取特征,并应用解码器LSTM进行重建,这种策略在顺序数据建模中被广泛使用。除了基于重建的方法,未来帧预测[3]是一种将异常视为不符合预期事件的替代深度学习方法。这些方法被训练以在正常训练数据集上基于其历史观察来预测未来帧,在测试阶段,通过将预测与期望进行比较来识别异常事件。我们还将自编码器作为骨干网络,并在正常数据集上对其进行训练,以提取通用因子。值得注意的是,我们同时结合了基于重建和基于预测的架构,通过同时重构输入的单个帧以捕捉外观特征,并预测未来帧与第一个输入帧之间的RGB差异来学习正常事件的运动模式。因此,在特征空间中包含不规则因素的异常样本无法准确重构。
2.2. 具有两个流网络的视频任务
为了充分利用视频任务中的空间和时间信息,[25]首次利用了双流网络,即RGB流和光流流,其中通过后期融合将两个流组合用于动作分类[26]。提出了一个带有两个网络分支的时空注意力模块,用于活动识别[8]。共同模拟人群模式的外观和动态,并在建模复杂动态场景中证明了双流架构的有效性。由于异常事件可以通过外观或运动来检测,[7]引入了用于视频异常检测的双流架构。此外,图像补丁和由光流表示的动态运动被用作两个独立网络的输入,分别捕获外观表示和运动表示,然后通过后期融合将这两个流的异常分数进行组合以进行最终评估[11]。利用两个生成器网络学习人群行为的正常模式,其中一个生成器网络接受输入帧以生成光流图像,而另一个生成器网络从光流中重构帧[10]。使用两个处理流,第一个自编码器学习正常事件中的常见空间外观结构,第二个流学习由光流表示的相应运动特征。除了直接以视频帧和光流为输入的方法外,MPEDRNN [27]提取2D人体骨骼轨迹并将这些轨迹馈送到编码器中,然后通过两个交互分支同时重构输入和预测未来,其中每个分支由带有RNN的编码器-解码器组成,以检测监控视频中的异常人类相关事件。然而,对于这些方法,获取光流[28]或轨迹是时间成本较高的。相比之下,我们利用RGB差异策略替代光流来模拟运动信息,这更加高效。具体而言,在训练阶段,我们堆叠除LIF外的所有其他帧,并使用2D CNN作为时态自编码器的骨干来处理连续的视频帧。通过强制运动编码器学习紧凑的运动表示并产生RGB差异,运动自编码器可以有效地学习时态规律和运动一致性。
2.3. 数据表示和数据聚类
许多异常检测方法[29-33]旨在在正常事件中找到“紧凑的描述”。最近,一些基于自动编码器的方法将特征学习和聚类结合在一起[34]。联合训练CNN自动编码器和多项式逻辑回归模型到自动编码器潜在空间。类似地,[35]交替表示学习和聚类,其中使用小批量k-Means作为聚类组件[36]。提出了一种深度嵌入式聚类(DEC)方法,该方法联合更新从预训练的自动编码器初始化的聚类中心和数据点表示。DEC使用经过优化的软分配,通过Kullback-Leibler发散损失来匹配更严格的分配。IDEC[37]和ST-GCAE[38]随后被提出作为DEC[14]的改进。提出了一种基于将训练样本聚类为正态性聚类的监督分类方法[39]。通过将各种模式的正常数据记录到存储器中的各个项目中,利用存储器模块进行异常检测。基于这种架构,并受到[40]思想的启发,我们引入了一个深度K-means聚类,以迫使自动编码器网络生成用于视频异常检测的紧凑特征表示。在训练阶段,我们通过最小化数据表示和聚类中心之间的距离来训练我们的深度K-means聚类。因此,每个聚类中心可以被视为训练数据集中的正常时空模式。在推理阶段,正态样本的表示将更紧密地映射到聚类中心。
3. Methods
3.1. Overview
主要有4个点
3.2. Spatial autoencoder
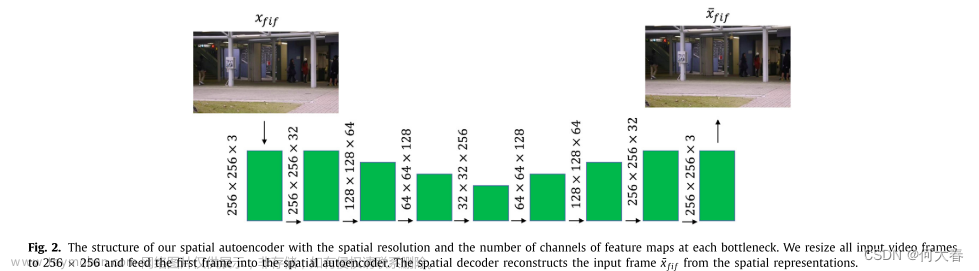
这是空间autoencoder,主要是重构视频序列的第一帧,用于重构视频的静态表示(理解为空间信息)。
输入为
x
f
i
f
x_{fif}
xfif(视频序列第一帧),通过编码器
E
a
E_a
Ea得到描述
Z
a
Z_a
Za,
Z
a
Z_a
Za再经过解码器
D
a
D_a
Da得到
x
^
f
i
f
\widehat{x}_{fif}
x
fif,如下面公式所示:

这里有个loss,是输入输出的均方误差:
3.3. Motion autoencoder
Motion autoencoder的结构如图所示:
输入4张图片,Motion autoencoder的输出为第5帧和第1帧的RGB差异,通过这种方式来表示运动差异,得到运动上的重构。
如公式所示:

过编码器
E
m
E_m
Em得到特征描述
Z
m
Z_m
Zm,
Z
m
Z_m
Zm再经过解码器
D
m
D_m
Dm得到
x
^
d
i
f
f
\widehat{x}_{diff}
x
diff。
其中
x
^
d
i
f
f
\widehat{x}_{diff}
x
diff为第5帧和第1帧的RGB差异。
这里的损失函数定义为:
由两部分组成,前半部分是
x
^
d
i
f
f
\widehat{x}_{diff}
x
diff与
x
d
i
f
f
x_{diff}
xdiff的均方误差,后半部分是梯度损失。
3.4. Variance attention module

方差注意力模块如上图所示,个人感觉论文里写的不太好理解,去源码上看了一下主要就是以下步骤:
- 对输入进行一次卷积操作:

得到图中黄色的特征图,对应公式如下:其中 W g W_g Wg表示卷积, z m i z_m^i zmi表示输入。
- 对每个通道相同位置对应的点求方差,得到通道的空间注意力权重


- 最后将注意力和原始输入相乘:

3.5. Clustering
对聚类的知识了解较少,只能理解为将两个编码器的输出进行聚类,能得到更好的正常表示。
3.6. The training objective function
损失函数有3个
分别是静态损失,动态损失和聚类的损失。
4. Experiments
评价指标采用AUC:
5. Conclusion
在本文中,我们提出了一种新的自动编码器架构,将时空信息分解为两个子模块,以学习空间和时间特征空间中的规律性,并在正常事件中生成紧凑的描述。具体地,
空间自动编码器对第一单独帧(FIF)进行操作,并通过重构输入来提取空间空间中的规则性。
时间自动编码器对连续的视频帧进行处理,通过构造RGB差来学习时间规律。根据捕获的时间规律性和运动一致性,时间自动编码器可以学习预测RGB残差,该残差包含用于异常检测的有用运动信息,非常有效。
此外,我们设计了一个方差注意力模块来突出框架的运动部分。此外,为了有效地学习空间和运动特征空间中的正规性,并获得更紧凑的数据表示,我们通过深度Kmeans聚类方法最小化级联表示与聚类中心之间的距离。我们将空间自动编码器和运动自动编码器的结果相结合,以获得最后一个单独帧(LIF)的预测,并将预测与像素级的聚类距离相融合,以评估异常。在三个具有代表性的数据集上进行的大量实验表明,我们的方法达到了最先进的性能。文章来源:https://www.toymoban.com/news/detail-775904.html
6阅读总结&&代码复现
- 将空间和运动信息结合起来重构正常序列,时间编码器用于重构一帧,运动编码器用于重构最后一帧和第一帧的RGB差,用于代表运动信息,或者叫时间信息;
- 引入Kmeans聚类算法将空间和运动信息绑定;
- 设计了一个方差注意力模块。
复现结果如下图在ped2在数据集,和作者差了两个点: 文章来源地址https://www.toymoban.com/news/detail-775904.html
文章来源地址https://www.toymoban.com/news/detail-775904.html
到了这里,关于Video anomaly detection with spatio-temporal dissociation 论文阅读的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[论文阅读笔记24]Social-STGCNN: A Social Spatio-Temporal GCNN for Human Traj. Pred.](https://imgs.yssmx.com/Uploads/2024/02/603782-1.png)