因为现在众多音乐平台下载歌曲都要收费了,导致我没有车载音乐听了。于是便自学爬虫做了这个简易的音乐爬虫。不是那些大平台的音乐爬虫,是一个不知名的小音乐网站的爬虫。下面开始正题:
首先,便是找不是那几家大互联网公司的音乐网站,在我的不懈努力之下终于找到了一家歌曲比较齐全的野鸡音乐网站(请允许我这么说)。虽说是野鸡,但是该有的热门歌手的新歌和热门歌曲都有,麻雀虽小,五脏俱全。
接着,便要对网站进行抓包,并对网页链接寻找规律,当然,这个小网站的网页链接的规律也是非常之简单。如下图所示:


不难发现,它的网页网址的规律,前面那一串不知名网址,加上你要搜索的的歌手的名字,然后再加上.html就可以了。于是乎,就解决了代码中url的问题。代码如下:
import requests
name = input()
url = 'http://www.2t58.com/so/{}/1.html'.format(name)
response = requests.get(url = url)上面代码目前是完全可行,虽然我并没有加入heards等相关的反爬参数,但是网站在这目前为止也没有进行反爬。
接下来,我们随便点击几首歌曲:
文章来源地址https://www.toymoban.com/news/detail-776218.html

文章来源:https://www.toymoban.com/news/detail-776218.html
因为喜欢周杰伦的朋友特别的多啊,我就搜索了周杰伦,并点了他的几首歌曲,我们可以发现,网页栏的网页地址变得毫无规律了,是一串我们看不懂的英文字母加上.html。而我们想要下载歌曲又必须进入到这个给页面,所以我们必须找到它网页地址的规律,或者说我们必须找到,那一串毫无规律的英文字母可以从哪个数据包中得到。接下来,我便进行了数据抓包并分析。
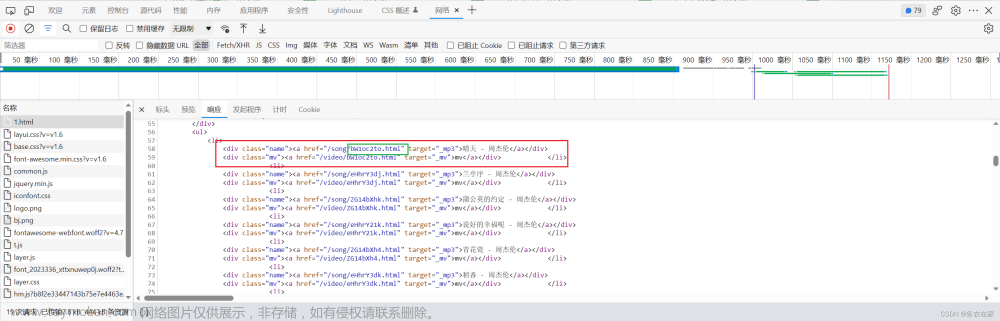
很容易发现,在每个a标签的href中的最后一个字段就是我们要的那一串毫无规律的英文字母,所以我们要做的就是查看它的url,然后通过requests的模块发送请求将这个网页给请求下来,经过我的尝试,该网站在这里进行了反爬,如果不加入heards则会请求不到数据,大家注意一下。然后,就是用正则表达式将我们需要的英文字母给匹配保留下来,代码如下:
ex = '<div class="name"><a href="/song/(.*?).html" target="_mp3">.*?</a></div>'
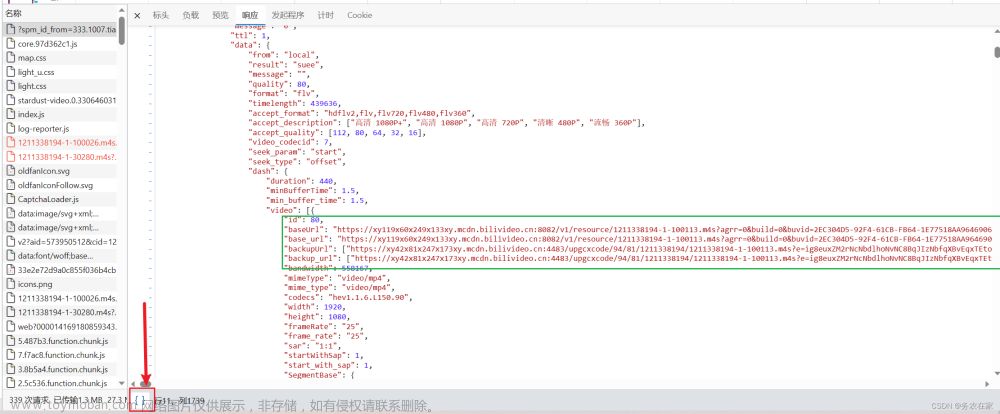
musicIndex = re.findall(ex, response.text, re.S)接下来,就是回去歌曲的下载链接,将它以二进制形式保存就可以了。随便点击一首歌曲,对歌曲详细页面进行抓包。
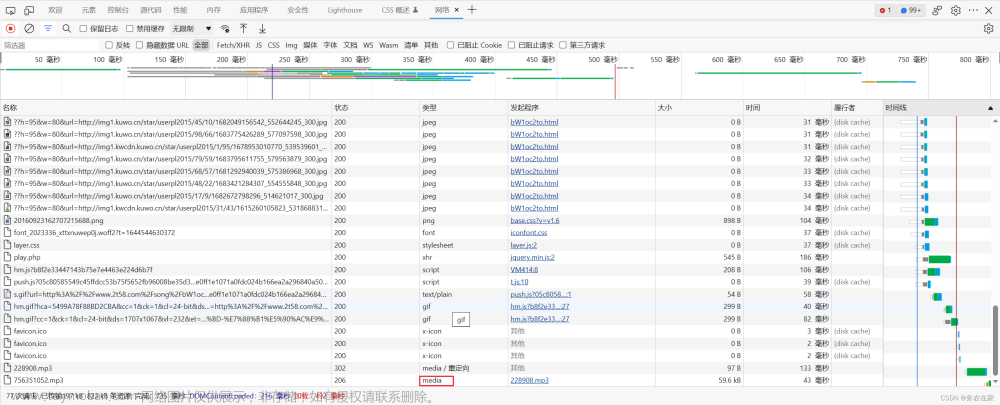
数据包是非常多的,我们可以根据数据包的类型来有选择型的查看,音频和视频等很显然就是media类型的数据包。很显然这就是我们想要的音乐链接,我们将它在一个单独的网页栏中搜索可以得到没有限制可以直接下载的完整的音乐。但是我们要的是批量下载,一首一首的下载效率太慢了。所以,我们还要继续寻找有没有一个数据包,它的响应就包含了这首歌曲的链接。我的做法是将最后一个.mp3的名称在数据包搜索栏中搜索对应关键字,很幸运,我找到了。
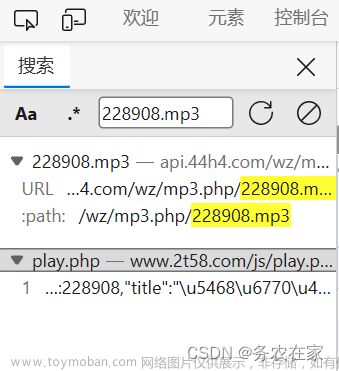
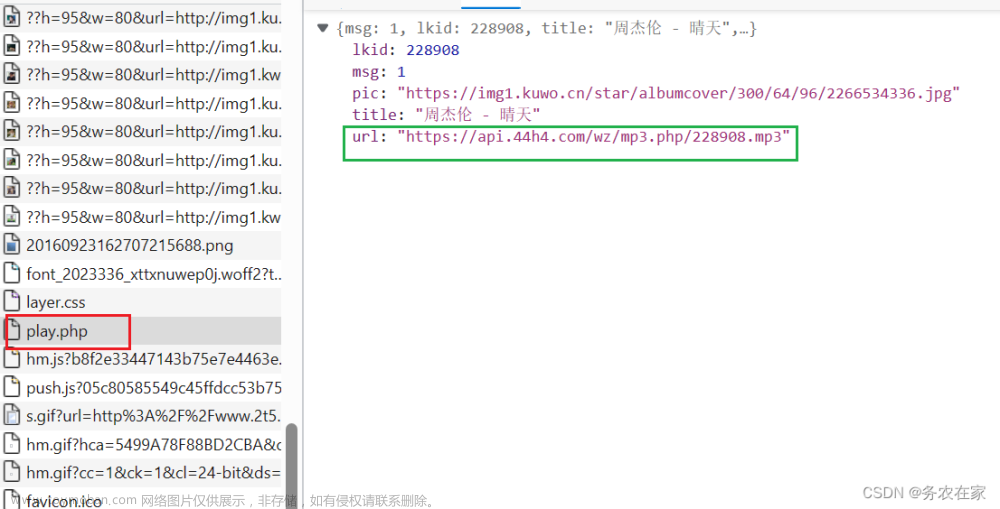
接下来就非常简单了,我们已经找到了每个要搜索的歌手的详情网页的规律(固定网址+歌手名字+.html),我们有获取了每一首歌曲的详情页面(那一段没有规律的英文字母),最后又在歌曲详情页面找到了包含歌曲链接的数据包,所以接下来我们要做的就是,将歌曲链接用二进制保存下来,学过爬虫的同学应该注意到了,上面这个数据包的响应数json数据,返回的是一个字典形式的数据,我们可以根据键值对来取出我们需要的歌曲的下载链接。首先就是将这个给数据包根据对应的url请求下来,注意在请求头中查看相应url的参数,代码如下:
data = {'id': i,'type': 'music'}
url2 = 'http://www.2t58.com/js/play.php'
response2 = requests.post(url = url2, headers = headers, data = data)
json_data = response2.json()
musicList = json_data['url']我们将歌曲的下载链接保存在列表musicList中,最后就是将歌曲保存,代码如下:
musicResponse = requests.get(url = musicList)
filename = json_data['title'] + '.mp3'
with open('E:/music/' + filename, 'wb') as f:
f.write(musicResponse.content)
print(filename + '下载成功!')大家改一下路径就可以正常运行了。
完整代码:
import requests
import re
# 张学友:aHNj
# 陈奕迅:eG4
# 林忆莲:d2t3eA
name = input()
url = 'http://www.2t58.com/so/{}/1.html'.format(name)
response = requests.get(url = url)
ex = '<div class="name"><a href="/song/(.*?).html" target="_mp3">.*?</a></div>'
musicIndex = re.findall(ex, response.text, re.S)
smallmusicList = []
for j in range(0, 5):
smallmusicList.append(musicIndex[j])
print(smallmusicList)
headers ={
'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'keep-alive',
'Content-Length':'26',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie':'Hm_lvt_b8f2e33447143b75e7e4463e224d6b7f=1690974946; Hm_lpvt_b8f2e33447143b75e7e4463e224d6b7f=1690976158',
'Host':'www.2t58.com',
'Origin':'http://www.2t58.com',
'Referer':'http://www.2t58.com/song/bWhzc3hud25u.html',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
for i in musicIndex:
data = {'id': i,'type': 'music'}
url2 = 'http://www.2t58.com/js/play.php'
response2 = requests.post(url = url2, headers = headers, data = data)
json_data = response2.json()
musicList = json_data['url']
musicResponse = requests.get(url = musicList)
filename = json_data['title'] + '.mp3'
with open('E:/music/' + filename, 'wb') as f:
f.write(musicResponse.content)
print(filename + '下载成功!')
可能是因为网站不够完善,有些歌手的详情网页并不是歌手名+.html,而是一些无规律的英文字母,我暂时发现的已经放在上面,如果要下载该歌手的歌曲,就输入相应的英文字母。
仅供学习使用,请不要用于违法犯罪。
到了这里,关于Python爬虫实战案例——音乐爬虫,收费歌曲依旧可用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!